摘要:HBase一直是大数据领域常用的非关系型数据库。随着HBase数据库中存入的数据量不断增长,对数据库里的数据进行查询变得越来越困难,需要有一个合理的二级索引的方案提高查询的效率。Elasticsearch是一个高性能的搜索服务器,利用Elasticsearch的技术,存储并搜索二级索引可以極大地提高HBase查询效率。
关键词:大数据;HBase;二级索引;协处理器;Elasticsearch
中图分类号:TP392
文献标识码:A
文章编号:1009-3044(2020)04-0001-02
收稿日期:2019-11-18
作者简介:李传冰(1993—),男,湖北武汉人,硕士研究生,主要研究方向为大数据。
A Secondary Index Scheme of Big Data in HBase Based on Elasticsearch
LI Chuan-bing
(The Third Research Institute of The Ministry of Public Security,Shanghai 200031,China)
Abstract:HBase has always been used as a NoSQL database in the field of big data.With the increasing amount of data stored in the HBase database,it becomes more and more difficult to query the data in the database.Therefore,a reasonable secondary index scheme is needed to improve the efficiency of the query.Elasticsearch is a high-performance search server,and the efficiency of the query in the HBase database can be improved greatly by storing and searching secondary indexes with Elasticsearch.
Key words:big data;HBase;secondary index;coprocessor;Elasticsearch
1?概述
随着大数据时代的来临,人们所存储的数据量呈爆炸性增长。数据能被用起来做各种数据分析才能发挥数据的价值。而对数据的利用第一步就是查询,查询效率的高低直接影响大数据分析的快慢。因此,很多公司投入相当多的精力去寻找可以提升搜索速度的方案。HBase作为一个可以存储海量数据的数据库,存储性能十分优异,但是查询范围十分有限,在缺少主键的情况下,条件查询效率也比较低下[1],仅仅依靠数据库的搜索功能无法满足商业化的业务需求。于是,有很多新颖的搜索方案被提出,其中比较实用的方案是釆取存储并查询二级索引的方案,加上基于Lucene的分布式搜索引擎Elasticsearch的配合使用[2],整套方案更加可靠、高效。
2?基于Elasticsearch—级索引方案
为了方便测试,构建了一个完整的二级索引存储系统。首先由Kafka的生产者生产批量实验性数据,数据总量1000万条;然后由Kafka的消费者将数据写入HBase,在数据录入的同时,启动HBase的协处理器Coprocessor,通过触发Coprocessor的钩子函数,同步二级索引至Elasticsearch。
整个系统搭建在三台服务器上,三台服务器均是Think-Server RD650,操作系统centos6.7,处理器Intel(R)Xeon(R)E5-2630v3,内存32GB。为了便于区分,给三台服务器分别命名为nodel10、nodel11、nodel12。因为HBase是部署在HDFS之上的,所以先在nodel10、node111、node112上部署了hadoop,node110为NameNode,node110、node111、node112为DataNodeo通过不断的选择尝试,最后选择了安装hadoop-2.7.7,hadoop-2.7.7版本比较稳定、成熟。在安装HBase的时候,在与hadoop-2.7.7匹配的版本中,选择了比较新的HBase-2.0.5。
HBase的协处理器机制有两种:一种是Observer,另一种是Endpoint[3]。Observer类似于一个触发器,在实际使用中,Observer机制比Endpoint更加灵活,Observer机制可以给特定的表绑定,不需要该机制的表则可以不绑定。考虑到实际的应用场景,采取的是Observer机制。在Kafka的消费者向HBase传入数据的过程中,釆取了以队列的方式批量导入,每一万条数据为一个批次,这样比一条一*条数据put进HBase,速度要快上很多。在实际的数据导入过程中,数据量不可能恰好是一万的倍数,多出来的余数如果不足一万,会导致数据遗漏,为了弥补这一缺漏,还给HBase导入数据增加了一个时间机制,每隔5秒钟,会将一个批次里剩下的数据均导入HBase数据库。
Elasticsearch的连接client以前是Transportclient,根据Elasticsearch官方的建议,以后会一直使用RestHighLevelClient、RestLowLevelClient[4],并停止对Transportclient的更新。RestHighLevelClient封装的更好,相比于RestLowLevelClient更易于配置参数,因此采用RestHighLevelClient。Elasticsearch也选取了比较新的版本7.2.0。
在给Elasticsearch传输数据的过程中,配置了bulkProces-sor,设置了批量传输的机制,这样可以提高传输效率。bulkPro-cessor也是两种传输机制并行,一个是以队列的方式批量导入,另一个是时间机制。这两种机制在bulkProcssor中都可以很方便的配置参数,经过各种调试,最后选择队列容量同样为一万条数据,时间机制为每隔5秒钟回滚一次,将队列中剩余的数据一起导入。
3?Elasticsearch二级索引性能测试
3.1?数据的写入性能
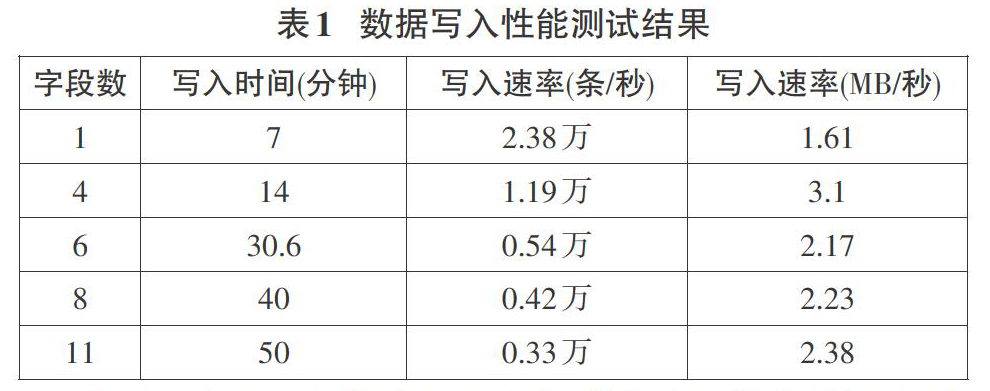
Kafka的生产者生产了批量实验性数据,每一批数据都有一千万条。每一条数据包括了一个假想用户的各项信息,一共有11个字段,字段名分别为用户名、地址、创建时间、电子邮件、序号、主机IP、登录时间、手机号码、密码、真实姓名、记录。每一个字段下的参数都是12位随机英文字符。数据写入测试进行了5次,每次测试时每条数据包含的字段数不同,依此是1、4、6、8、11个,用于比较在不同字段数的情况下整个系统的数据写入性能。对整个系统的数据写入性能测试,是从数据写入HBase开始,到二级索引全部存入Elasticsearch结束。
测试结果如表1所示:
如表1中展示的结果可以看出,随着字段数的增加,每秒写入条数开始降低,虽然每一次测试数据的条数都是一千万,但是字段数的增加等于HBase存入的列数增加,相对于一个字段来说写入的数据量更大,按每秒写入多少条数据并不能完全显示写入性能,按每秒写入的字节数可以更可靠的显示写入性能。这点可以从表1中最后一列得到验证,写入速率基本维持在2~3MB/秒之间。
基于Elasticsearch的二级索引存储系统,写入数据速率比较稳定,在存入数据的字段数为1个的情况下,按照测试的结果,一天的数据写入量可以达到20亿条左右。
3.2?数据的检索性能
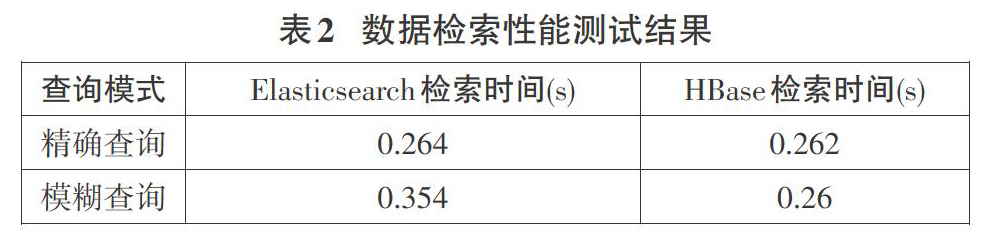
数据的检索,先依靠Elasticsearch搜索关键词查询到id,Elasticsearch中存入的每条数据的id即是HBase中所对应数据的rowKey,然后根据这个rowKey在HBase中查询原始数据。HBase搜索关键词的能力比较差,但是在已知rowKey的情况下,查询效率能够得到显著提高。
测试时,进行了两种检索性能测试,一种是精确查询,另一种是模糊查询。均进行了100次重复实验,Elasticsearch查询时间是Elasticsearch根据关键词检索id的时间,HBase检索时间是HBase根据id(rowKey)查询原始数据的时间,每次查询的总时间是这两个查询时间之和,平均查询时间如下表2所示。
Elasticsearch模糊查询时间比精确查询时间多花了一点,但基本上检索时间都在毫秒量级,Elasticsearch查询出rowKey后,HBase再根据rowKey查询原始数据所消耗的时间也很短,同样是毫秒量级,二者相加,总的查询时间不到1秒,可见整个系统的数据查询性能足够满足快速查询的需求。
4?结论
基于Elasticsearch的二级索引系统,极大地提咼了HBase的检索效率。数据写入性能可以达到2~3MB/s,总的检索性能可以达到毫秒量级。整套系统既可以满足海量数据的写入需求,也可以满足快速检索的需求。
参考文献:
[1] 夏超俊.基于协处理器机制的HBase检索速度改进研究[D].湖南大学,2015.
[2] 梁文楷.基于Elasticsearch全文检索系统的实现[J].电脑编程技巧与维护,2019(6):116-119.
[3] 朱松杰,娄渊胜,叶枫,李凌,陈勇.基于协处理器的HBase内存索引机制的研究[J/OL].计算机工程与应用,1-11[2019-11-15].
[4] 李宣廷,姜楠,狄查美玲,王淖瑩,孟德文.基于ElasticSearch的网络舆情搜索平台设计[J].大连民族大学学报,2019,21(5):449-452.
[通联编辑:王力]
- 谈谈初中物理总复习策略
- 浅谈初中英语写作中的思维训练
- 小学数学问题情境创设的探索
- 浅谈高中数学教学中学生核心素养的培养
- 游戏教学法在小学篮球教学中的应用探究
- 小学语文教学与传统文化的融合
- 提高初中语文阅读教学有效性研究策略
- 微课在小学美术手工课堂教学中的应用研究
- 信息技术在初中物理教学中的有效应用探究
- 时空观念在高中历史教学中应用的探讨
- 浅谈小学古诗词有效教学策略
- 关于小学美术生活化教学研究
- 初高中数学教学衔接策略的探究
- 浅谈戏曲表演意境营造
- 新时期高中班主任德育工作的反思与建议
- 高中生物教学中合作学习策略的应用研究
- 初中英语词汇教学的有效方法探析
- 浅谈小学语文拓展阅读教学的有效策略
- 初中数学课堂教学中学生自主学习能力的培养探究
- 情境教学法在高中生物教学中的应用
- 浅谈小学班级管理工作策略
- 浅谈小学语文教学中传统文化渗透途径
- 浅析小学数学教学中如何提高学生的兴趣
- 浅谈情景教学法在小学英语课堂教学中的应用
- 传统文化在小学语文中的渗透策略
- overjoyfulnesses
- overjoyous
- overjoyously
- overjoyousness
- overjoyousnesses
- overjudicious
- scar
- scarce
- scarcely
- scarceness
- scarcenesses
- scarcer
- scarcest
- scarcities
- scarcity
- scarcityvalue
- scarcity value
- scare
- scarecrow
- scarecrowish
- scarecrows
- scarecrowy
- scared
- scareder
- scaredest
- 有崇高品行的人
- 有崇高德行的人
- 有巢氏
- 有工贪种竹,无暇不栽松
- 有巨大影响和贡献的人物
- 有巨大推动力的事物
- 有差别
- 有己无人
- 有希望
- 有帏幔的车
- 有帝王之德而未居帝王之位者
- 有帮助
- 有帮助,能起作用
- 有帮助;有好处
- 有帷幔有窗子的卧车
- 有帷盖的车
- 有帷盖而前顶高的车
- 有年
- 有年于兹
- 有年无月
- 有年纪
- 有年纪啦
- 有幸
- 有幸不幸
- 有幸有不幸