余凯

摘?要:欺诈风险是消费金融业务中存在的主要风险之一,在银行的信贷业务中反欺诈模型起着很重要的作用。通过对kaggle中的银行信用卡消费数据进行数据预处理和特征工程对特征进行缩放和选择,并且利用smote算法对数据集的不均衡现象进行处理,构建了基于SVM的反欺诈预测模型,对用户是否进行了欺诈消费进行预测,通过调整模型参数,得到最优模型,使得准确率达到了97.00%。
关键词:信用卡;反欺诈模型;SVM
中图分类号:D9?????文献标识码:A??????doi:10.19311/j.cnki.1672-3198.2019.17.081
1?研究背景
欺诈风险是消费金融业务中存在的主要风险之一,它是指信贷客户完全不具备还款意愿一类的风险。据统计,2016年中国信用卡欺诈损失排名前三的欺诈类型为伪 卡、虚假身份和互联网欺诈,与2015年一致,其中伪卡损 失占比较2015年继续上升;2016 年借记卡欺诈的主要类 型为电信诈骗,互联网欺诈损失金额排名第二位。目前欺诈呈现产业链化的特征,围绕着欺诈的实施,形成了专业 的技术开发产业,身份信用包装和虚假身份提供产业、业 务漏洞发现和欺诈方法传授产业。对于金融机构而言,需 要构建完备的风险控制方法来识别风险,避免欺诈、坏账、呆账等的发生,尤其对于消费金融业务而言,风控能力的 高低直接决定了业务盈利能力强弱。我们针对信用卡消费这一典型业务场景,应用机器学习技术进行欺诈风险管理并设计数据产品对异常客户进行监控预警。区别于将机器学习技术应用到单一反欺诈规则制定的典型做法,我们尝试从整体视角对欺诈风险进行评估,实现精准量化预测并以此作为应对欺诈风险的强有力手段。建模思路及方法具有一定的可迁移性,可以被广泛应用到银行风险防范、反欺诈等业务领域。正是由于在银行业中反欺诈的重要性,我们基于SVM这种机器学习方法构建反欺诈预测模型,探究这种模型的有效性。
2?数据预处理
我们是从kaggle数据集中获取的数据集,该数据集包含由欧洲持卡人于2013年9月使用信用卡进行交的数据。此数据集显示两天内发生的交易,其中284,807笔交易中有492笔被盗刷。数据集非常不平衡,积极类的(被盗刷)占所有交易的0.172%。
它只包含作为PCA转换结果的数字输入变量。不幸的是,由于保密问题,我们无法提供有关数据的原始功能和更多背景信息。特征V1,V2,…V28是使用PCA获得的主要组件,没有用PCA转换的唯一特征是“时间”和“量”。特征'时间'包含数据集中每个事务和第一个事务之间经过的秒数。特征“金额”是交易金额,此特征可用于实例依赖的成本认知学习。特征'类'是响应变量,如果发生被盗刷,则取值1,否则为0。
该数据的数据预处理部分我们运用了数据审查、数据清理。如图1,Time-Class31个维度的每一维度的数据量都是相同的都为284807,并且没有缺失值,所以该数据集是个良好、不需要进行补值处理,可以直接拿来使用的数据集。
观察了数据的描述性统计信息:发现Time和Amount的平均值、最大值、最小值、中位值等等与V1-V28都相差很大,V1-V28和Class的平均值都集中在0的附近,它们数据的方差都在0-1的范围内。说明该数据分布比较均匀,amout这个维度的数据分布的非常不均匀,尺度与V1-V28不相同,需要后续进行特征缩放标准化的工作。
我们统计了正常消费和欺诈消费的金额和占比绘制了图2。0表示正常消费,1表示欺诈消费,由柱状图可以看出欺诈的数据量非常小,而正常消费非常多。饼形图可以看出欺诈消费所占的百分比很小为0.17%可以发现正常消费和欺诈消费的差异性是非常大的。
时间这个维度也由秒转换为了小时,因为小时对于大多数的人而言都较于理解,并且小时可以清晰的表示出早、中、晚的三个时间段。可以方便观察不同时间段消费金额的差异等等。
3?特征工程
特种工程的目的是为了最大限度地从原始数据中提取特征以供算法和模型使用,通过对特征进行整合,选择,缩放等使得模型具有更好的效果。本文同过对我们的数据集进行特征工程的探究,来提高后续模型的准确率。
我们调查了欺诈与正常的数据每一维度之间的相关系数绘制了如图3,发现信用卡被盗刷的事件中,部分变量之间的相关性更明显。其中变量V1、V2、V3、V4、V5、V6、V7、V9、V10、V11、V12、V14、V16、V17和V18以及V19之间的变化在信用卡被盗刷的样本中呈性一定的规律。信用卡正常消费事件中,Time-Hour的相关性都很弱接近于零。所以正常和被盗刷之间存在着很大的差异性。例如:被盗刷的V2,V5相关性就非常明显接近于-1.0,而正常的V2,V5相关性为零,所以正常与盗刷的相关性差异性也很大。
我们查找到了欺詐和正常的消费金额与消费笔数,做出了如图4的柱状图。信用卡被盗刷发生的金额与信用卡正常用户发生的金额相比呈现散而小的特点,这说明信用卡盗刷者为了不引起信用卡卡主的注意,更偏向选择小金额消费。而信用卡正常消费笔数分布比较集中,呈现幂律分布,符合正常的消费习惯。
如图5所示:这是我们寻找消费笔数和时间的关系。在正常消费中,两天的消费时间上的习惯是相同的,并且有在凌晨消费不积极,而在造成8-9点之后消费热情升高,在夜晚9点之后进入高峰的特点;而在欺诈消费中,并无上述特点,分布的比较不均匀。
我们寻找消费金额和时间的关系,绘制了图6,该图表示的是:不同时间的消费金额。欺诈消费金额是散乱排布的,而正常消费金额很集中,大多数集中在0-10000元,在相同时间段的消费金额比较集中。
图7是我们发现不同变量在信用卡被盗刷和信用卡正常的不同分布情况,我们将选择在不同信用卡状态下的分布有明显区别的变量。我们观察了所有31个维度的正常和欺诈的分布情况发现了V8、V13、V15、V20、V21、V22、 V23、V24、V25、V26、V27和V28这些变量欺诈和正常消费的数据的分布差异比较小,如图7中下图中所示,V15的正常和欺诈的数据分布差异非常小,我们对这样的维度进行了剔除。而剩余的其他维度差异比较大,如图7中上图V16的正常和欺诈差异非常大,说明通过这个维度可以对是否是欺诈消费进行判断,所以我们保留了这部分变量。
随机森林可以用于特征探索,是一种基于决策树的分类方法,利用随机森林算法可以计算输出不同特征的重要行排序,在这里我们将18个维度的重要性利用随机森林进行排序如图8,hour和amout这两个维度的重要性排名比较靠后,但是我们从前面的工作中发现这两个维度是对于分类有效的特征,那么如图8前面V12-V2的维度有效性就更大了。说明我们之前进行的特征选择工作是合理的。
最后,我们对amout和hour这两个维度进行了均值-标准差的方法进行标准化,通过这样的数据缩放,使得和其他维度的尺度相同。
4?模型训练及评价
支持向量机(Support Vector Machine,SVM)的基本模型是在特征空间上找到最佳的分离超平面使得训练集上正负样本间隔最大。SVM是用来解决二分类问题的有监督学习算法,在引入了核方法之后SVM也可以用来解决非线性问题。
一般SVM有下面三种:
(1)硬间隔支持向量机(线性可分支持向量机):当训练数据线性可分时,可通过硬间隔最大化学得一个线性可分支持向量机。
(2)软间隔支持向量机:当训练数据近似线性可分时,可通过软间隔最大化学得一个线性支持向量机。
(3)非线性支持向量机:当训练数据线性不可分时,可通过核方法以及软间隔最大化学得一个非线性支持向量机。
并且SVM的优缺点优点是SVM在中小量样本规模的时候容易得到数据和特征之间的非线性关系,可以避免使用神经网络结构选择和局部极小值问题,可解释性强,可以解决高维问题。 缺点是SVM对缺失数据敏感,对非线性问题没有通用的解决方案,核函数的正确选择不容易,计算复杂度高,主流的算法可以达到O(n2)O(n2)的复杂度,这对大规模的数据是吃不消的。
4.1?处理样本不均衡问题
正常和违约两种类别的数量差别较大,会对模型学习造成困扰。举例来说,假如有100个样本,其中只有1个是贷款违约样本,其余99个全为贷款正常样本,那么学习器只要制定一个简单的方法:所有样本均判别为正常样本,就能轻松达到99%的准确率。而这个分类器的决策对我们的风险控制毫无意义。因此,在将数据代入模型训练之前,我们必须先解决样本不平衡的问题。
非平衡样本常用的解决方式有两种:
(1)过采样(oversampling),增加正样本使得正、负样本数目接近,然后再进行学习。
(2)欠采样(undersampling),去除一些负样本使得正、负样本数目接近,然后再进行学习。
在这里我们选用过采样,因为该样本的数据量本来就不是很大,应该使用过采样增加一些样本。我们使用了smote的方法。
表格1是Smote处理之后的结果。
4.2?实验过程及结果
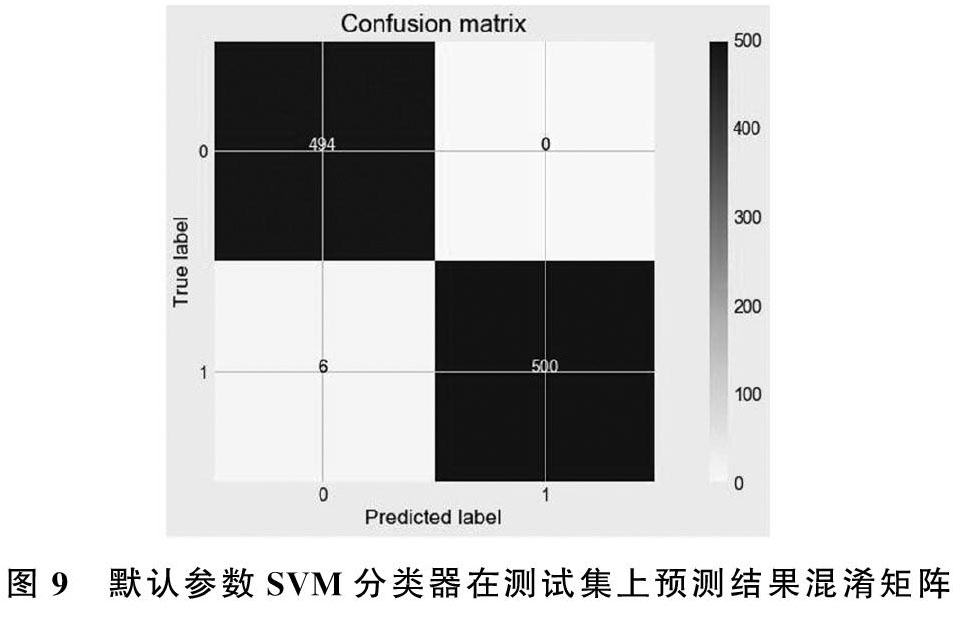
由于svm的计算量比较大,比较耗时,所以我们选择了1000个样本进行实验,是进行随机抽取的,使得0(正常消费)和1(欺诈消费) 分布均匀。我们用全体样本训练了svm分類器,其中的参数使用默认的。通过分类器产生的预测结果是99.4%。如图9所示,预测的结果和真实是一样的有994个数据,而预测错误的只有6个数据。
我们这样模型训练的不足是我们的模型训练和测试都在同一个数据集上进行,这样导致模型产生过拟合的问题。所以我们对样本进行划分.一般来说,将数据集划分为训练集和测试集有三种处理方法:(1)留出法(hold-out);(2)交叉验证法(cross-validation);(3)自助法(bootstrapping) 本次项目采用的是交叉验证法划分数据集。让模型在训练集进行学习,在验证集上进行参数调优,最后使用测试集数据评估模型的性能。在这里我们运用cv 交叉验证分训练集和测试集,用grid search选择最优参数。
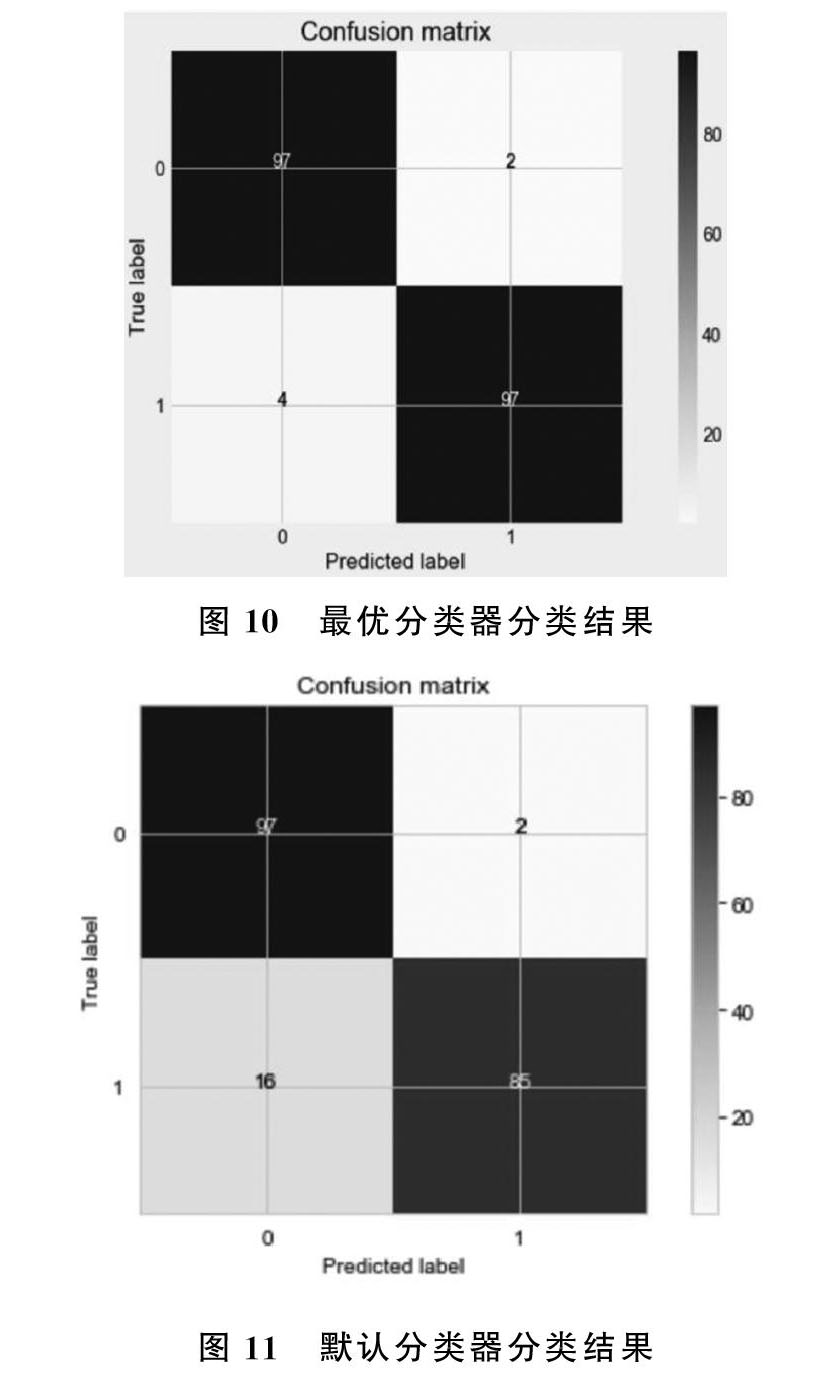
模型调优我们采用网格搜索调优参数(grid search),通过构建参数候选集合,然后网格搜索会穷举各种参数组合,根据设定评定的评分机制找到最好的那一组设置。在grid search进行调参的时候,我们调节了C和kernal两个参数, 其中‘C是惩罚参数C,默认值是1.0,C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。 kernel参数表示核函数的形式,默认是rbf,也可以是‘linear,‘poly,‘rbf,‘sigmoid,‘precomputed ,进行实验的过程中,5折cv,模型准确率评估采用了f1-score。我们设置C的取值范围为[0.01,0.1,1,10,100],kernal的取值范围为 [‘linear,‘poly,‘rbf,‘sigmoid],我们得到的最好参数'kernel'='linear','C'=0.01,在该参数模型的准确率为0.97000,其混淆矩阵如图10所示。默认参数svm分类器在相同测试集上的准确率为0.90426,其混淆矩阵如图11所示,经过调参模型准确率提高了6.6%。
对比两个分类器的分类结果,最优分类器降低了将欺诈交易判断为正常交易的错误的概率,而这类错误相比较于将正常消费判断为欺诈消费的错误,对银行造成的损失更大。经过银行调参之后的模型更加严谨有效。
5?总结
通过对kaggle中的银行信用卡消费数据进行数据预处理和特征工程对特征进行缩放和选择,并且利用smote算法对数据集的不均衡现象进行处理,构建了基于SVM的反欺诈预测模型,对用户是否进行了欺诈消费进行预测,通过调整模型参数,得到最优模型,使得准确率达到了97.00%。目前大部分的相关模型主要以logist回归和决策树为主,我们尝试了新的SVM的方法解决该问题,并且我们处理了样本不均衡的问题,得到有意义的结果。我们的不足支出在于数据集不够大,这是由于SVM计算量比较大,计算时间久,所以不得已选择了小的数据集,之后若计算条件允许的情况下,我们将尝试大数据集下的运行结果。
参考文献
[1]仵伟强,后其林.基于机器学习模型的消费金融反欺诈模型与方法[J].现代管理科学,2018.
[2]唐飞泉,杨律铭.人工智能在银行业的应用与实践[J].现代管理科学,2019,(02).
[3]赵清华,张艺豪,马建芬,段倩倩.改进SMOTE的非平衡数据集分类算法研究[J].计算机工程与应用,2018,(18).
[4]Support-Vector Networks.Corinna Cortes,Vladimir Vapnik[J].Machine Learning,1995,(3).
- 刍议中职语文古诗文教学中的传统文化渗透
- 信息化教学模式下中职语文文言文教学初探
- 中职学校思想道德修养与法律基础教学探析
- 中职德育课信息化教学的现状及优化策略
- 产业发展对职教名师成长与培养的作用研究
- 翻转课堂在中职学校计算机教学中的应用
- 技工院校数控技术应用专业建设之我见
- “互联网+”背景下中职学校在工业机器人技术与应用教育中的几点思考与探索
- 中职信息技术教学中人文素养的渗透思考
- 对中职物理教学的反思
- 就业导向下中职英语教学的有效开展思考
- 提高思政课教师教学业务能力,做新时代立德树人的教学能手
- 基于中职技能大赛的电梯专业教学融合的研究与实践
- 产教深度融合下“共享会计工厂”会计实训教学新模式的构建与实践
- 产教融合下中职生能力数据与岗位对接的研究
- 探析智能手机在汽修专业课堂教学中的应用
- 基于现代学徒制的技工院校校企协同育人培养机制探讨
- 基于现代学徒制的非遗传承人才培养模式创新与研究
- 简析中高职衔接人才培养模式存在的问题与对策
- “大思政”格局下中职汽修人才培养模式实现途径研究
- 宝马BEST课程线上线下混合式教学实践
- 职业发展背景下中职教育信息化研究
- 高中历史新教材中原始资料的运用途径
- 强化信息化教学,使中职英语课堂“活”起来
- 藏医药大学生汉语文自主学习现状及原因调查分析
- rubberiest
- rubberiness
- rubbering
- rubberless
- rubbers
- rubberstamp
- rubber-stamp
- rubber stamp
- rubberstamp1
- rubber-stamped
- rubber-stamping
- rubber stamps
- rubber-stamps
- rubbery
- rubber²
- rubber¹
- rubbish
- rubbished
- rubbisher
- rubbishes
- rubbish/garbage
- rubbishing
- rubbishly
- rubbish tip
- rubble
- 出嘴不出身
- 出囊脱锥
- 出国
- 出国潮
- 出国热
- 出国的大轮船
- 出圈
- 出圈儿
- 出土
- 出土文物
- 出土甘蔗——节节甜
- 出土的陶俑——总算有了出头之日
- 出场
- 出场费
- 出场阵容
- 出坏主意
- 出坏主意捣鬼
- 出堂
- 出堂会
- 出境
- 出墙之杏
- 出声
- 出声儿
- 出声回答
- 出声地念诗文