闫东+王诚


摘要:在信息化时代,高效地组织管理大量地质领域数据成为实现良好的地质资料服务与管理的关键所在。为解决我国地质资料标准化程度低及应用难度大等问题,本文提出了一种基于本体和语义标引的地质资料服务与管理方法。首先建立地质领域信息资源元数据模型和关联关系模型;并根据关联模型自动化构建计算机可读的地质本体;采用基于地质本体的语义概念映射的方法将高维的词语向量转换到低维语义空间,加之词频、词位置和词跨度等权重因子的综合作用,对地质资料文本进行精准快速有效的分类,实现文本的语义标引;最后根据地质本体和语义标引开展地质资料检索试验,试验结果表明,查全率和查准率分别从75.7%和81.2%提高到80.7%和84.8%,检索效果得到了明显提升。因此,本文为地质资料的服务与管理模型设计与实现奠定了良好的基础。
关键词:计算机应用技术;知识服务;本体;语义标引理的趋势。利用本体方法可以建立地质领域的知识脉络,可以更好地继承共享已有的知识;利用自动化标引可以有效组织地质专业资源,可以更有效地管理资源。因此,根据本体和文本自动标引技术可以实现良好的地质资料服务与管理,在此基础上可进一步优化地质资料检索服务。本文提出的地质资料服务与管理框架主要包含四部分。
元数据关联模型:元数据是描述数据的数据,根据文档的元数据标签,可建立资源之间的关联关系模型。元数据的关联关系可以是指同一文档两主体之间的“关联关系”,也可以代表不同文档的“关联关系”,元数据关联模型的设计是实现本体构建以及文本关联关系的重要保障。
基于元数据关联模型的本体构建:在本体中有等级、等同、相关等关系。而元数据模型的关联关系恰好可以在文档之间也建立起相应的关联关系。而对于在同一元数据项有相同值的文档,可以直接建立关联关系,因此,基于元数据模型可以实现准确而快速的本体自动化构建。
基于本体映射的语义标引:利用面向自动标引应用的地质本体对词向量进行降维,尽量达到词与词之间语义的正交性,降低特征词之间的冗余度,实现地质资料分本的正确分类,为地质资料服务与管理奠定基础。
基于本体和语义标引的服务与管理:地质资料服务的主要是依赖于语义网技术实现的各种服务,如检索、关联、推荐等;地质资料管理的则是实现知识的搜集、存储和组织。通过本体与语义标引技术可有效提高地质资料的服务效果和管理效率。
2 地质资料服务与管理设计与实现
2.1 元数据关联模型
针对地质资料中的文档资源建立元数据模型,通过元数据描述文本信息,并根据文档的元数据标签,建立资源之间的关联关系模型。见表1。
2.2 基于元数据模型构建本体
自动构建本体是基于自然语言分析和基于统计的机器学习方法抽取文档中的概念和关系,自动本体。自动构建本体的方法是当前的研究熱点和难点。确定资源本体库的结构、概念、概念间关系、实例关系。在这里概念实际上是指馆藏目录资源和用户信息的元数据,而关系就是通过计量学方法得到的各个字段间关系。但由于在元数据库中的所有概念和概念关系都是已经确定好的,无需专家再进行人工干预,完全可以计算机自动操作。
本文使用OWL(Web Ontology Language)进行本体的白动化描述,OWL是从RDF(ResourceDescription Framework)上发展起来的本体描述语言,是一种标准的描述本体的类、概念及概念间关系的描述语言,也是目前应用最多的本体语义化描述方式‘5]。
在本体描述中,存在一定量的同义词或等价词,即等同关系。用“
最终,使用OWL将元数据关联模型中的数据转化为本体,含有概念4651个,概念间的关系25527条,其中等同关系4943条,等级关系13786条和相关关系6798条。
2.3基于本体映射的语义标引
影响地质资料检索服务效果的主要原因有两个:第一,检索词单一,仅仅依靠关键词的匹配大大降低了检索效果;第二,地质资料分类不准确,单一的使用题目中的主题词作为分类标准,无法实现真正的本文分类。2.2节所述的本体能够很好的解决检索词单一问题。接下来本文提出一种基于本体映射的文本语义标引技术,能够很好的解决地质资料分类不准确问题。
(1)文本预处理
本文使用的是中科院的开源分词系统实现的文本预处理,去除停用词、时间、副词等无用词汇,预处理过程中尽量保留能够显示文本特征的词汇。
(2)基于词权重的文本特征选择
通常的文本特征选择使用的是公式TF*IDF,TF是词语在文档中出现的频率,IDF是出现该词的文档的倒频率。本研究使用TW方法代替TF计算文本特征权重,词Vi-文档Dj权重Wi,j的计算公式为:
其中,Ni是与词Vi相关的文档的个数;/D/是全部文档数。
TW对词频、词位置和词跨进行综合评估,比单纯的词频TF更能反映词对文本主题的重要性。TW的计算公式为:
TW=TF×LOC×SPAN
TF为词频因子,词i在文档d中的TFi,d,计算公式为:
Fre是词i在文档d中出现的频数,MAXj(Frejd)是文档d中jL}{现频数最高的词的频数。
LOC为位置因子,出现在标题、摘要的词一般更能反映文本的主题,将不同位置出现的词赋予不同的权重值。出现在标题、摘要、正文三处不同区域的词语,其位置值分别设为60、30和10。
SPAN为词跨因子,词跨度是指词在文中首次出现和末次出现之间的距离,一般词跨度越大(即在开篇和结论都使用该词)对文本的主题就越重要。
其中,las为词Vi在文中最后一次出现的序号,fir为词Vi在文中首次出现的序号,sum为经分词计算后的文本分词总数。
(3)基于本体映射的语义标引
利用面向自动标引应用的地质本体对词向量进行降维,尽量达到词与词之间语义的正交性。这里的降维主要使用本体的层级关系和等同关系。例如:“页岩气、致密气层气、Shale gas”都可以用“页岩气”代替,这属于同等词的映射降维;“伴生气、低硫气、火山气”都可以用“天然气”代替,这属于等级词的映射降维;语义映射增大了与类别的语义关联强的词汇的权重;将同义词、近义词、相关词用一个词语表示,同时累积权重;将分散的底层概念映射到较高层概念,权重累加到高层概念词汇,高层概念能概括文本主題。
2.4 基于本体和文本标引的地质资料服务与管理
2.4.1 本体的解析与推理
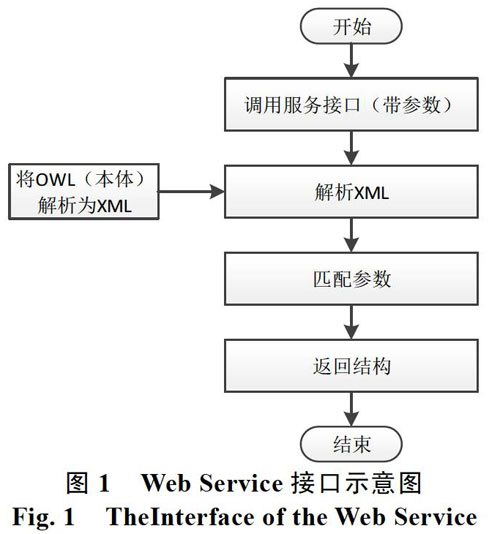
为了完成基于本体的地质资料服务与管理,必须实现基于本体的推理解析工作。OWL是一种很好的描述本体语言,但本身并不具备任何推理和计算能力,因此,为实现基于本体的语义检索,必须对OWL文件进行相应的推理解析,导出本体中存在的知识,满足对检索条件的扩展和推送。本文采用的方法是将OWL解析为XML文件,由于OWL是在XML基础上发展而来,因此转换起来相对方便,且方便保留原始特性。
图1所展示的是将OWL文件解析为XML文件之后,将其发布为Web Service。发布后,可以通过访问服务地址发出查询请求,在输入参数,完成查询偏好设置。参数的主要作用是提供多种查询条件,即不同参数值表示返回等同词、上位词、下位词、相关词等内容,能够保障用户按照自己的偏好进行检索。
2.4.2 基于本体和语义标引的检索原型
如图2所示,当用户输入检索词后,推理引擎根据本体对检索词进行扩展,检索词扩展的方式非常灵活,可以选择等同词与原来的检索词组合成新的查询条件,或者将原检索词的等级词或者相关词一并解析出来组合新的查询条件,并且与已经被语义标引过的地质资料库进行匹配,匹配成功后完成一次完整的语义检索。与此同时,推理引擎还将与检索词有关的词动态地生成一组超链接,这种超链接能够为用户提供更多感兴趣的检索推荐。同时,为了提高系统的灵活性,用户还可以在Web Service接口服务中根据自己的检索习惯来输入相应参数,如是否返回检索词的英文词、等级词和相关词等,从而方便用户更快速地获取检索结果。
通过对于同义词(等同关系)的返回,能够提高检索的命中率,即实现了检索词的有效扩展,相比于模糊匹配,又能够有效控制扩展词的数量,达到最高效的检索模式。
对于智能导航的生成(等级关系和相关关系),能够有针对性的给出用户分类推送列表,可以使用户快速的获取检索资源的相关知识。
对于Web Service参数设置,可以满足用户根据自己的检索习惯和检索需要进行个性化的设置,以更适合的方式进行检索。
3 实验分析
本次基于本体和语义标引的检索试验采用查准率(P)、查全率(R)和F值作为评测标准。使用1000档地质资料进行测试。评测标准计算公式如下。
由表2可以看出,在使用本体和语义标引后,查全率和查准率得到了明显提升。同时值得提出的是,检索结果受检索系统的检索方式影响,本文主要是借助现有的检索系统实现的检索试验,因此在检索结果上会收到诸多限制。
4 总结
基于元数据关联模型的本体构建既能够使人从繁重的本体手工构建中解脱出来,又能够提高本体构建质量和效率;而基于本体映射的文本自动标引方法,利用本体概念的层级关系映射,有效降低了文本的特征数量,快速准确地为文本标注了语义标签。由试验结果可知,结合本体和语义标引后的检索系统所能够提供的服务与管理明显优于传统系统。因此,本文为地质资料的服务与管理模型奠定了良好的基础。
- 引导青年成才促进企业发展
- 利用信息化为企业人力资源管理工作服务探讨
- 家族管理模式企业的弊端及解决方法
- 浅谈钻井井控管理工作
- 企业危机管理中的知识管理方法与策略
- 探讨联通公司营业基础业务管理策略
- 对国有船舶制造业企业平衡计分卡应用的建议
- 现代企业应着力建设“以人为本”的企业文化
- 郎志正从技术走向管理
- 大学生利用微课自主学习的统计分析
- 对勤工俭学参与图书馆管理工作的思考
- 高校教师人力资源配置的理论指导
- 高校学生电子设计能力培养的探讨
- 班主任对大学新生管理工作的浅析
- 浅谈高校师资队伍建设
- 音乐教学与现代信息技术相结合的探索
- 广东电网个性化选学培训模式的探索
- 技工院校班主任工作之用“心”抓“风”
- 多媒体辅助教学提高大学生学习效率的探讨
- 高校后勤人力资源管理问题浅析
- 计算机网络环境下的高职校园文化建设
- 论学生宿舍电器使用及管理对策
- 管理案例开发教学与评价的持续改进模型研究
- 深化校企合作 创新学生技能考核评价方式
- 关于高校院系信息化建设的思考
- infants
- infant school
- infatuated
- infatuation
- infatuations
- infavour
- in favour of
- infect
- infected
- infectedness
- infectednesses
- infecter
- infecters
- infectible
- infecting
- infection
- infections
- infectious
- infectiously
- infectiousness
- infectiousnesses
- infector
- infectors
- infects
- infer
- 清峻
- 清峻慷慨的风格
- 清崇
- 清左
- 清巧
- 清帮
- 清干
- 清平
- 清平世界
- 清平世界,荡荡乾坤
- 清平乐
- 清平俭约
- 清平吉祥
- 清平宁静
- 清平安宁
- 清平安定
- 清幽
- 清幽殊绝
- 清幽深远
- 清幽的境地
- 清幽的自然环境
- 清幽的花卉
- 清幽的隐居生活
- 清幽的韵味
- 清幽美丽