王宏涛++孙剑伟

摘要:介绍了BP神经网络和SVM算法的分类原理。附加动量因子和随机梯度下降法是对BP神经网络进行优化的重要方法,利用Google实验室的MNIST手写数字库研究了动量因子和随机数以及SVM不同核函数对分类性能影响,为实际应用中模型的选择提供一定依据。同时也研究了两个算法在不同样本数下的性能表现,实验表明样本数较少时SVM比BP具有更高的泛化能力。最后结合两个算法特点,给出层次分类法并做为今后研究方向。
关键词:MNIST数字库;BP神经网络;支持向量机;分类性能
中图分类号:TP391.41
文献标识码:A
DOI:10.3969/j.issn.1003-6970.2015.11.024
0 引言
很多实际应用问题都可归为分类问题,如故障诊断、模式识别等,分类过程包括分类器构造和运用模型进行分类两个步骤。神经网络和支持向量机(SVM)是分类领域中两种重要方法。神经网络是模拟人脑神经系统的数学模型,具有高度并行性、较强的自学习自适应和联想记忆功能特点。Vapnik在20世纪90年代基于统计学习理论提出支持向量机,它是借助最优化方法解决问题的,求解支持向量转化为解凸二次优化问题,它能够获得全局最优解,是结构风险最小化的算法。经过多年发展神经网络和支持向量机在很多领域取得成功,但是神经网络和支持向量机参数选择没有理论上支撑,参数选择优化是算法应用成功的关键,挖掘模型参数对算法性能影响具有重要意义。本文在Google的手写数字库上研究了BP(Back Propagation)神经网络和支持向量机的附加动量因子、随机数和不同核函数等变量对准确率、计算时间以及收敛曲线的影响,比较两个算法在不同训练样本数时性能表现。最后结合BP神经网络算法和SVM的各自特点提出分层分类模型,该方法适用于具有结构分解、功能分解特点的对象,为复杂对象分类提供了一种思路。
1 BP神经网络和SVM算法
1.1 BP神经网络技术
神经网络是对人脑的抽象、模拟和简化的信息处理模型,其中神经元数学模型、网络连接方式以及神经网络学习方式是神经网络的三个关键。神经网络原理是利用网络的学习和记忆功能,让神经网络学习各个类别中的样本特征,在遇到待识别样本时神经网络利用记住的特征信息对比输入向量,从而确定待测样本所属类别。该算法通过学习机制得出决策信息,并不需要模式先验知识。BP神经网络是目前最流行的一种神经网络模型,它是一种按误差反向传播的多层前馈神经网络,包括输入层、隐含层和输出层。Kolmogorov定理已经证明BP神经网络具有强大的非线性映射能力和泛化能力,任一连续函数或映射函数均可采用三层网络加以实现。
BP神经网络算法包括两个阶段:从输入层经过隐层逐层计算输出结果的过程,从输出层逐层误差反向传播的学习过程。正向传播过程中训练样本从输入层逐层处理传到输出层,将输出结果与期望值比较计算误差,若误差较大将误差按学习规则反向逐层分摊到各节点。学习规则用最快梯度下降法,通过反向传播不断调整网络的权值和阈值使网络的误差平方和最小。
1.2 BP神经网络学习算法的优化
传统BP算法采用梯度下降法,由于梯度下降法易陷入局部极小点而得不到全局最优解,在权值调整时增加动量因子项可以使算法对误差曲面局部细节不敏感能调出局部极小值。式1是学习算法的权值更新函数,其中△Wji(n)是第n次迭代时权值的更新,α(0≤α≤1)是动量系数,权值更新时不仅考虑了第n+l步梯度方向而且增加了以前梯度方向,目的是减少震荡。
△Wji(n+1)=(1-α)θδjxji+α△Wji(n)
(1)
由于批梯度下降法将所有用样本误差进行反馈学习而使得效率低下,训练次数多收敛速度慢。随机梯度下降法做为批梯度下降法的改进,每轮迭代时随机选取有限个样本误差进行学习,对于样本规模很大时可大大减少运行时间。随机个数选取是关键。
1.3 支持向量机方法
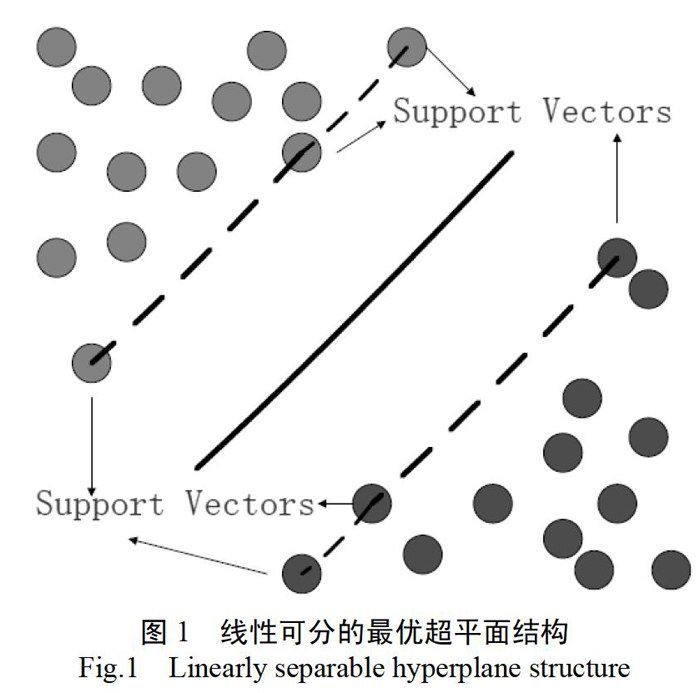
支持向量机是基于结构风险最小化原理的算法。分类原理是建立一个超平面作为决策面,该决策面在能够正确分类样本的情况下,使样本中离分类面最近的点的“间隔”最大。如图1中实线作为决策面可以将不同颜色的两类样本分开,虚线是由离决策面最近的点并且平行于决策面。虚线间距离称为间隔,当间隔最大时虚线上的点便是支持向量。SVM学习过程即是求支持向量。
对于非线性分类问题,将原始数据通过一个非线性映射Φ从原始R维空间映射到高维空间Ω,再在高维特征空间Ω中求最优分类面。Ω的维数可能会非常高,利用核函数可似解决维数灾难。根据相关定理,如果核函数K(xi,xj)满足Mercer条件,它就对应某一变换空间的内积K(xi,xj)=<φ(xi),φ(xj)>使得在原始空间中计算的结果等价于在高维空间计算内积。在实例中应用核函数可有效分类而计算量没有大幅增加,核函数有线性核函数、多项式核函数和径向基核函数等。
支持向量机可以看做具有单隐层的前馈神经网络,支持向量是隐层的神经元,神经元的权值是通过二次规划算法优化获得。但是二者只是结构上相似,优化原理及具体含义有着本质区别。SVM中支持向量是由算法自动确定不需要人为指定数目和权值,而BP神经网络的隐含层个数及单元数都需要事先人为确定。
2 基于MNIST的分类实验设计
2.1 MNIST手写数字库描述
Google实验室的Corinna Cortes和纽约大学克朗研究所的Yann LeCun建有一个手写数字数据库,训练样本有60000张图像,测试样本有10000张,都是0到9的手写数字图片灰度级为8,每个图片是28*28像素矩阵,可以使用一个784大小的向量表示。
数据预处理:MNIST样本灰度值在0-256之间,而且大部分等于0,部分大于230,数据范围跨度大,对BP神经网络来说可能导致收敛慢、训练时间长,对输出精度也有影响。对SVM算法如果直接将图像的像素值进行建模学习,分类正确率只有10%左右。所以在实验时将灰度值进行归一化处理映射到到[0,1]之间。
2.2 BP神经网络分类实验设计
(1)网络设计:隐层个数、隐层神经元个数、转移函数等参数需要事先确定,我们参考文献资料给出最优取值如图2。在此基础上分别研究动量因子和随机梯度下降法中随机数选取对分类性能影响。
(2)性能评价指标:从分类准确率、收敛时间和曲线特征三个方面考察算法性能。高准确率是算法的首要目标,而随机梯度下降法和附加动量因子作用是减少运行时间提高学习效率,所以选择收敛时间和曲线特征做为评价项。
2.3 SVM分类实验设计
SVM算法中参数相比BP算法少,主要考察不同核函数以及样本数对分类性能影响,其中关于训练样本数同BP算法性能进行比较。常用核函数有以下4种:
(1)线性核函数K(x,y)=x*y
(2)多项式核函数K(x,y)=[x*y+1]*d
(3)径向基核函数K(x,y)=exp(-(|x-y|)2/σ2)
( 4) Sigmoid核函数K(x,y)=tanh(b(x*y)-c)
多分类方法:SVM本身是二分类方法,不能直接进行多分类需要转换。实验中我们采用一对一分类法。实验具有10个分类目标,训练建立个分类函数。当对未知样本进行分类时,每个分类器都对其类别进行判断,并为相应的类别投票,最后得票多的即为该样本的类别。
3 实验仿真
实验在Matlab7.6上编程实现,其中SVM性能实验应用了LIBSVM工具包。LIBSVM是台湾大学教授林智仁博士等人开发的关于SVM软件仿真工具。
3.1 BP神经网络分类性能
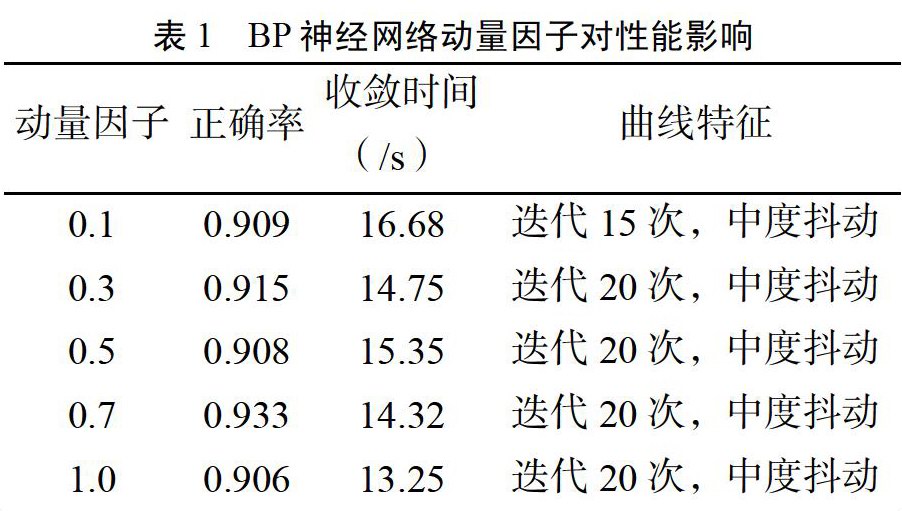
实验1 附加动量因子对性能影响
实验样本个数取5000,动量因子在0到1之间选择。
由表1可以看到,动量因子似乎没有起到平滑随机梯度下降法收敛曲线的作用。甚至,过小的动量因子会导致抖动更加明显。但准确率和运行时间上都区别不大。说明本身不加动量因子的情况下收敛曲线的抖动就不明显。引入动量因子不能使其收敛到全局最优,反而加剧了震荡。
实验2随机梯度下降法中随机数对性能影响
实验1表明附加动量因子未起到平滑作用,此实验不加入动量因子。
如果BP神经网络学习算法采用随机梯度下降法,由表2可看到当选取的随机样本数为5000时算法性能已经很优秀,说明此时随机样本已足够代表样本规律,而随着随机样本数增加运行时间急速增加但正确率并未显著提高。当选取的随机数逐渐减小时,收敛曲线抖动开始加剧,准确率也有所下降。
3.2 SVM分类性能
实验3不同核函数对算法性能影响
实验分别选择线性核函数、多项式核函数及径向基核函数在MNIST上进行分类,最优参数参考文献给出,实验结果如表3,可知三个核函数的分类结果正确率都很接近,支持向量个数也都很接近,不同核函数对分类正确率影响很小。
实验4 训练样本数对算法性能影响
在核函数研究基础上此实验选取径向基核函数中高斯核函数,样本数分别取100/500/1000/2000/5000/10000/20000/50000进行实验。
图3比较了SVM和BP算法分类准确率和收敛时间性能。在样本数即使只有500时支持向量机准确率已经很高,提高训练样本数对预测准确率没多大意义,但是会使算法运行时间大大提高,当样本数达到50000时预测准确率反而下降,主要是由于支持向量过多会使模型对有效信息“过度解读”。样本数过多带来另一个问题是支持向量增多导致运算量增大。
BP神经网络随着样本数上升实验准确率显著上升,样本数较少时准确率较低,样本数达到20000时准确率得到提升但迭代运行时间也大幅提高。另外利用样本数500训练的网络模型进行分类实验,分类结果很不稳定,说明即使样数很少时训练准确率很高但不能保证具有较高泛化能力。综合比较样本数较少时SVM比BP具有更高的泛化能力。
3.3 实验分析
BP神经网络学习算法引入动量因子可以防止陷入局部最优,但在手写数字分类中反而会加剧抖动使算法不能收敛,不是所有情况适合加入动量因子。学习算法选取随机梯度下降法时,当随机样本足够表示样本规律时能有效减少运行时间,但是过少会使预测准确率下降,过多等同于批量梯度法会加大运算量。BP和SVM分类准确率与样本数没有严格量化关系,但足够的样本可以提高BP算法分类准确率及泛化能力,样本数较少时SVM在比BP具有更高的泛化能力。
4 结论
BP神经网络和支持向量机在分类、模式识别和故障诊断中是常用的两种方法。研究了BP神经网络和SVM算法几个关键参数对算法性能影响。BP神经网络中动量因子不是在所有场合下都适用,与样本的数学特征有关,不合理引入动量因子反而会加剧抖动。随机梯度下降法中选择合适的随机数在保证分类效果同时可有效降低运行时间,这对于大规模数据学习具有重要意义。SVM算法对核函数选取不敏感,同时SVM算法在小样本上表现优秀,好于BP神经网络,对于大样本支持向量过多可能会产生过拟合,基于这一特点提出结合BP神经网络和SVM算法的分层分类方法。
如果分类对象复杂,类别具有模糊性,结合BP神经网络和SVM算法进行层次分类,可避免分类空间组合爆炸。层次分类可以发挥BP神经网络在大样本上泛化能力高以及避免在小样本上学习率不足和SVM在小样本上分类优秀的特点。算法思想:类别层次是一个树形结构,越靠近根节点分类模糊度越高数据量越大,越靠近叶子节点分类越具体。分类即是从根节点到叶子节点的寻优过程,各节点依据IR(Vk)←f(w1,w2…,wi)值选择BP神经网络或SVM分类器,其中f表示综合数据规模和维数等因素度量函数。这些是后续工作需要进一步研究。
- 浅议自首的司法认定及法律完善
- 践行公正公平原则努力提升司法鉴定的文化品位
- 探究行政诉讼中行政机关如何履行举证责任
- 检察机关提起公益诉讼制度的现实困惑及应对之道
- 试论虚假民事诉讼的规制
- 浅析虚假诉讼的检察监督
- 从典型案例分析舆论监督下的独立审判制度
- 浅谈国际商事仲裁与国际投资仲裁的区别
- 劳务派遣与相关类型合同的交叉与鉴别
- 论认定广告过滤行为构成不正当竞争行为的不合理性
- 房地产企业破产重整相关实务问题研究
- 基于执转破衔接的“僵尸企业”的有效处理
- 我国资产证券化实现真实销售的法律障碍分析
- 网络虚拟财产的法律界定与法律保护
- 论我国海上货物留置权的成立要件
- 论商业租赁的优先承租权
- 国际货物买卖中减轻损失措施的合理性分析
- 国际贸易业务中法律风险问题分析与防范
- 浅谈“海底捞”:捞出来的企业营销竞争战略以及管理艺术
- 加强企业基层党建政工工作的新思路
- 基层烟草专卖行政执法风险管理研究
- 加强合同全寿命周期管理,防范建设工程企业运行风险
- 非上市公司股权激励制度的制定和实施
- 新疆基层干部法治能力提升对策研究
- 我国基层政府政策执行力的提高途径
- be in the right ballpark
- be in the right place at the right time
- be in the running
- be in the spotlight/limelight
- be in the throes of
- be in the wash
- be in the way
- be in the wrong place at the wrong time
- be into
- be into sb
- be in training
- be in trouble
- be in tune with
- be in two minds
- be inundated with
- be inured to
- be in use
- be in vogue
- be involved
- be involved / get involved
- be involved in an accident
- be involved with
- be in work
- be in working order
- be itching to do sth
- 裘弊金尽
- 裘弊金尽裘敝金残
- 裘敝金尽
- 裘敝金残
- 裘的领
- 裘皮
- 裘皮之都
- 裘皮及裘皮制品
- 裘盛戎
- 裘罽
- 裘脱文君
- 裘良
- 裘茸
- 裘葛
- 裘葛催年
- 裘褐
- 裘集狐腋
- 裘鞸
- 裘领
- 裘马
- 裘马声色
- 裘马清狂
- 裘马轻狂
- 裘马轻肥
- 裙