匡雯 顾佳燕

摘 要:大规模服务存储结构模型研究中,多级索引模型被证明是非常高效的存储结构,具有稳定、易管理、易维护、低冗余的优势。目前的研究建立在服务调用概率平均分布这一假设之上,然而现实服务调用是不等概率的,这意味着多级索引模型在服务调用的不等概率情况下还不是最优。为提高服务调用不等概率条件下多级索引模型的检索效率,通过分析多级索引模型的检索特性,推导出检索操作的时间复杂度函数。利用函数极值,设计了不等概率条件下键值的优化选择方法。实验结果显示,该方法比随机选键方法提高检索效率15%左右,证明优化选择方法能有效提高服务检索效率。
关键词:服务计算;服务检索;服务存储;多级索引模型
DOI:10. 11907/rjdk. 181798
中图分类号:TP301文献标识码:A文章编号:1672-7800(2019)001-0040-05
Abstract: Many works studied storage structures of services. Among them, a multilevel index model was proved to be very efficient for service storage for large-scale service repositories. It has the advantages of non-redundancy, stability, being easy managed and maintained. Previous works are proposed and evaluated on the assumption that the probability of service invoking is equal. However, it is too strict in reality, which means the efficiency of service retrieval is not optimal. In order to improve the efficiency of service retrieval under the condition of unequal probability of service invoking, the time complexity of the service retrieval is deduced and an optimal key selection method is proposed according to the function. Our experimental results show that the optimal key selection method reduces 15% of retrieval time. Therefore, the effectiveness and efficiency of the proposed optimal key selection method under unequal probability of service invoking are valid.
0 引言
隨着互联网技术的飞速发展和产业规模的不断扩大,Web服务呈现高速增长趋势[1],这对软件产业提出了更高要求。随时可用性、松散耦合性、灵活的可扩展性和分布式以及更高的可重用性,是现代软件产业的突出特点[2],服务组合是研究热点。Web服务组合指提供复杂新功能的组合服务过程[3]。工作流技术[4-6]、自动机[7]、Petri网[8-9]、人工智能规划[10]等理论和方法在服务组合领域都有应用。一些研究成果提出采用自己的服务存储结构减少服务组合时间,如Graph结构[11-13]、倒排索引[14]、Service Net[15-17]等,但仍存在一些缺陷,如复杂度高、可靠性差、用户满意度低等。
Wu等[2]基于等价类、等价划分、商集理论,提出了一种大规模服务存储结构——多级索引模型, Wu,Xu等[2,18-20]提到的键值选择策略与笔者先前[21]改进的键值选择策略,都是在服务等概率调用情况下的选择策略,但这种假设在实际中很难实现。由于某些服务“很火”且经常被调用,其它服务“很冷”且很少被调用,导致服务调用很可能是不等概率的,所以本文设计不等概率模块,完善不等概率的多级索引模型并提出不等概率模型上的键值选择策略。
1 多级索引模型
1.1 服务基本定义
定义1 一个服务s是一个三元组[s=s,?s,?O],其中[s]表示服务的输入参数集合,[s]表示服务的输出参数集合,O表示服务其它元素集合,如服务声誉等。
服务检索指根据用户需求接受一组参数,并返回由该组参数调用的一组服务。根据当前参数集合查找到可发生服务的集合,通过服务组合和发现来调用,定义如下:
定义2 服务的检索运算可定义为[Re(A,?S)={s | ][s?A∧s∈S}],其中,A为一个参数集合,S表示服务集合,s表示一个服务,[Re(A,?S)]表示从服务集S中找出服务的输入参数均包含在A中的所有服务,即在状态A下可以引发的所有服务。
定义3 用户需求可定义为一个二元组[Q=(Qp,Qr)],其中Qp表示用户可提供的参数集合,Qr表示用户需要的参数集合。
1.2 多级索引及模型
大规模服务存储库通过服务的输入输出参数进行服务组合操作。由于大规模服务库可能存在一些包含相同输入输出参数的服务集合,必然导致服务组合存在大量冗余。
由于等价类和等价元素具有完整性、无冗余性、正确性特征,Wu等[2]基于等价类和等价元素关系,将多级索引模型分为4个级别,分别是第1级索引(The First Level Index,L1 I):如果服务s∈Cs,那么服务s和相似类Cs之间存在一个索引链接;第2级索引(The Second Level Index,L2 I):如果相似类Cs∈Cis,那么相似类Cs和半相似类Cis之间存在一个索引链接;第3级索引(The Third Level Index,L3I):如果半相似类Cis∈Ck,那么半相似类Cis和键类Ck之间存在一个索引链接;第4级索引(The Fourth Level Index,L4 I):对于“Ck∈[?3],”k∈К, 如果fk(Ck)=k,那么在键类Ck和键k之间存在一条索引链接。
Wu等[2]基于4个索引级别提出了3种索引模型:全索引包括L1I-L4I;中级索引包括L2I-L4I;初级索引包括L3I和L4I。在多级索引服务存储模型中,基于等价关系和等价类划分的各类索引函数关系,可以有效避免相互之间服务信息冗余情况,从而解决重复检索带来的模型效率问题。
为了应对不同的服务存储仓库情形,多级索引服务存储模型提供了弹性部署方案,对于不同的存储状况和用户需求采用不同方案。弹性部署方案包括基于L1I-L4I的完整模型、基于L2I-L4I中级模型和基于L3I-L4I的初级模型。L1I-L4I构建了一个服务的多级索引模型,总体结构如图1所示。由于每级索引是完整的、无冗余的,所以整个索引模型也是完整的、无冗余的。
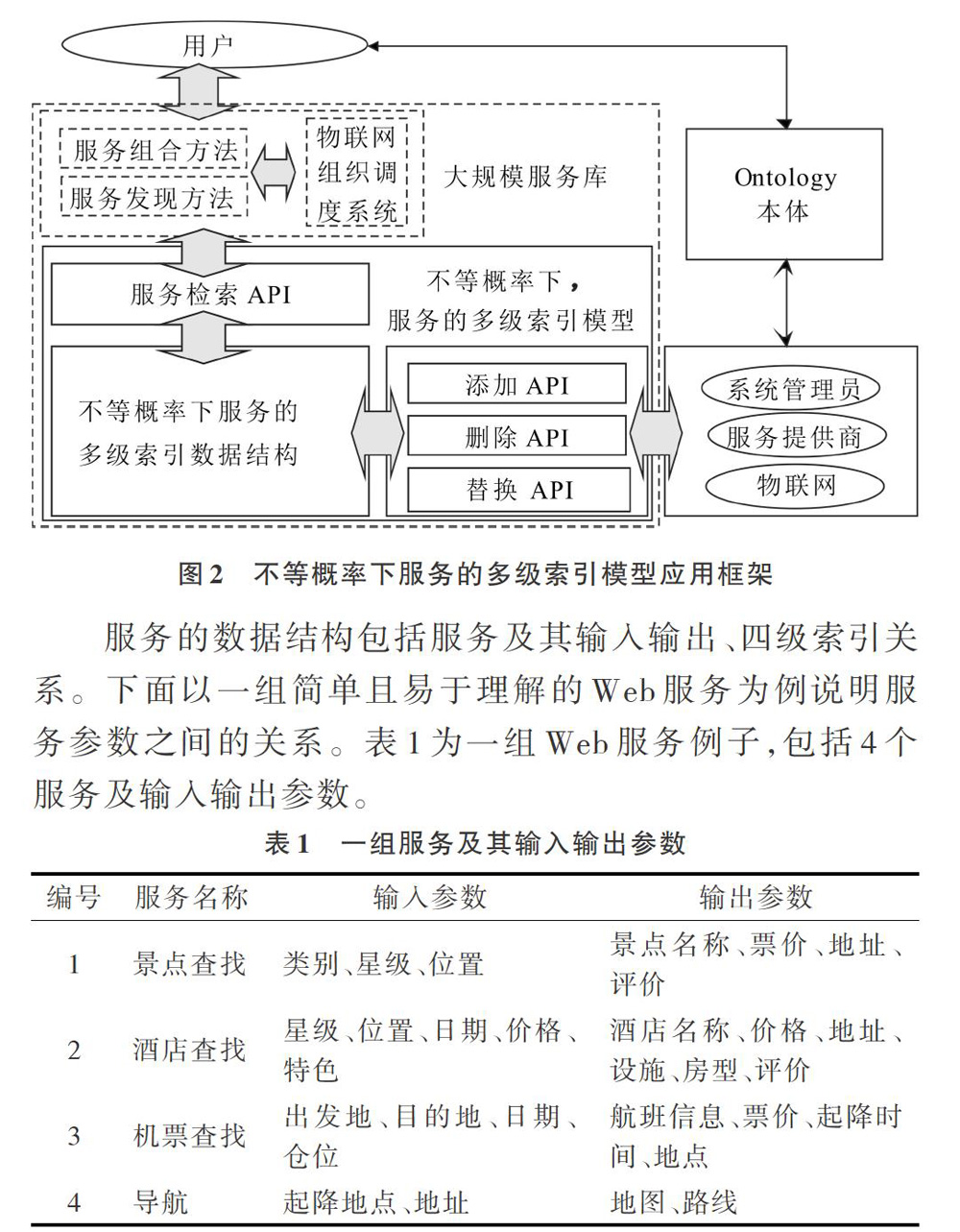
2 不等概率模块设计与实现
2.1 不等概率下的多级索引模型结构
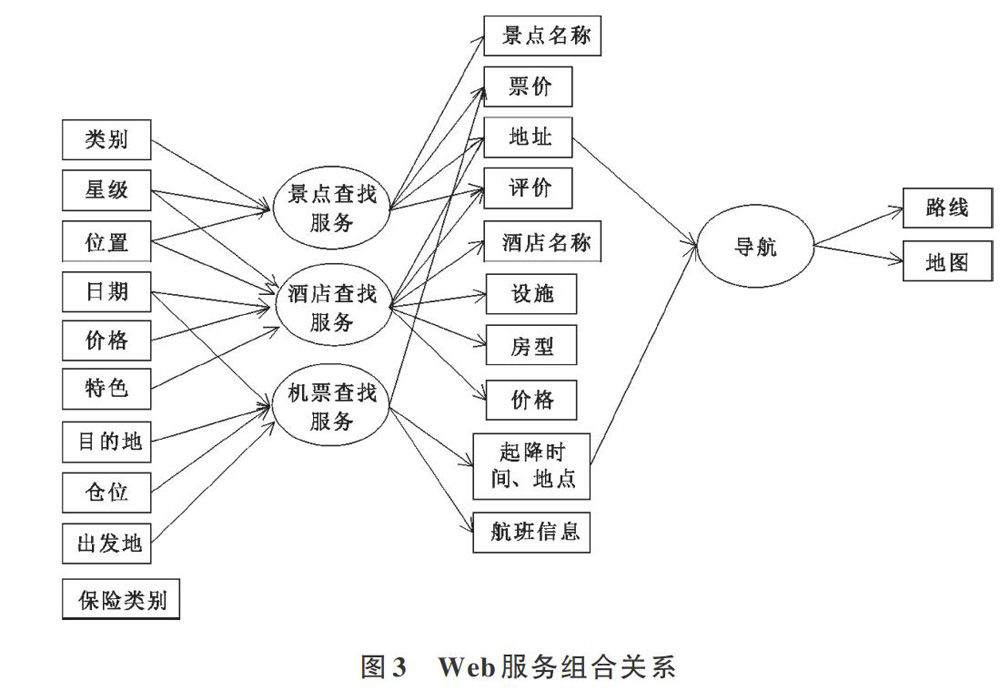
服务的数据结构包括服务及其输入输出、四级索引关系。下面以一组简单且易于理解的Web服务为例说明服务参数之间的关系。表1为一组Web服务例子,包括4个服务及输入输出参数。
2.2 服务参数的不等概率设计
在多级索引模型中,输出参数对检索操作没有影响,因此本文只讨论构建服务的输入参数不等概率情况。每组服务都有一组输入参数,服务输入参数的不等概率以两个服务s1、s2举例:s1的输入参数为{a, b},输出参数为{g, h},s2的输入参数为{a, c},输出参数为{j, k},那么输入参数a被使用两次,而b、c只被使用一次。在大规模服务存储库中,必然存在有的服务部分输入参数相同,有的服务输入参数完全不同,这就是服务输入参数的不等概率情况,其关键算法如下:
2.3 检索参数的不等概率设计
由于服务调用是通过对检索参数进行查询实现的,因此服务被调用的概率不相等,即检索参数不等于概率分布。服务检索参数由用户请求调用行为产生,每个用户的调用行为是随机的,同时各用户调用行为之间基本独立,对所有用户的调用行为进行统计可得到各个服务的检索概率。满足要素独立、随机和相加3个属性,用户检索请求数据的分布较接近于正态分布。表2为jumpshot设备的主要搜索服务情况统计,从理论和统计数据可得出检索参数的非等概率分布近似收敛于正态分布的结论。
将实验所产生的检索参数,如样本容量为3200,均值为500,标准差分别为200的检索参数集合,导出到Excel并用spss统计工具分析,结果如图4所示。显然这3200个检索参数基本符合正态分布趋势。
3 键值选择策略设计与实现
3.1 键定义
初级索引包括L3I和L4I,L3I和L4I是基于键构造的,键是多级索引结构中的一个创新性概念。在多级索引模型的添加操作中引入键,不仅能有效移除冗余,而且能提高添加和检索操作效率。Wu等[2]提出最原始的键值选择策略,简称为原始选键策略。笔者在文献[21]中对该策略进行改进,简称为随机选键策略。本文提出服务调用不等概率情况下的多级索引模型,并基于此提出一种新型的键值选择策略。
键在L3I和L4I上部署,由于初级索引模型、中级索引模型、全索引模型都包含第三和第四级索引,因此本文提出的键值策略将在初级索引模型上进行部署和实验,实验结果和效率分析同样适用于中级和全索引模型。
图5显示了初级索引结构。S是一个服务存储库,当s被添加到S中时,键值选择方法会为每个服务选择键值。键值是用作索引条目的参数。如果si和sj具有相同的键,则它们将被分类到相同的键值类别中。Ck表示一个键值类,它是一组具有相同键值的服务,[?3]表示所有键值类,К表示所有键值类的键值集合。
3.3 键值选择算法设计
初级索引模型中对服务的检索过程根据用户提出的检索参数集,先对键集合进行检索,比较检索参数集和键集合中的键,找到符合的键类。每个键类对应一些服务,对这些服务进行比较,找到请求的服务,并返回用户需要的参数集合。结合理论分析,不等概率情况下提高检索效率可以尽可能缩短整体调用时间,即整体调用次数,而整体调用次数取决于每个键类的调用次数。
由于键的调用概率和调用次数事前未知,那么不等概率下,提高检索操作的效率可从减少服务比较时间着手,即保持每个键对应的服务个数尽可能少。首先对比键集合和输入参数集,选择一个键集合中没有的输入参数作为键,如果该服务的所有输入参数在键集合中都包含了,就遍历每个输入参数作为键对应的服务个数,选择一个对应服务个数最少的作为该服务的键。为方便与其它键值选择方法进行对比,将此方法命名为整体最优键值选择方法。整体最优键值选择算法设计如下:
4 实验结果与分析
本系统开发软件环境:Microsoft Visual Studio 2012中的控制台应用程序和Windows窗体应用程序,开发语言为Visual C#,采用面向对象开发技术。各个組成部分耦合性低,从应用层模块到结构层模块均可单独修改、升级或替换。实验步骤:首先根据服务参数和检索参数不等概率分布算法进行编码,实现不等概率下的多级索引模型搭建;接着将整体最优选键方法编码实现,与等概率下吴等[2]提出的原始选键方法及笔者之前提出的优化过的选键方法——随机选键方法[21]进行检索效率比较。
4.1 基础参数设置
生成10个数据集,每个数据集包括20 000个服务,令n=20 000;参数集合大小是1 000,令m=1 000;每个服务有10个输入参数,令q=10;每个检索请求包括32个参数,令r=32;数据集包含100个检索请求。
4.2 实验结果对比分析
表3总结了服务输入参数和检索参数不等概率情况下,3种方法在初级索引模型上的检索效率。服务输入参数不等概率条件下,整体最优选键方法与随机[21]、原始选键方法[2]相比,检索效率提高20%左右;服务检索参数不等概率条件下,整体最优选键方法与随机[21]、原始选键方法[2]相比检索效率提高15%左右。因此不等概率情况下,整体最优选键方法是最优方法。
5 结语
本文針对服务调用频率不同的情况,提出了多级索引模型的新的键值选择方法,完善不等概率下的多级索引模型,使其更贴近实际情况。从理论和实验上验证了新方法的高效性。通过在初级索引模型上与原始、随机选键方法比较,发现不等概率下整体最优选键方法可缩短检索操作时间,提高检索效率,在检索参数重复率较高的情况下效果更佳。
参考文献:
[1] SERRAI W,ABDELLI A,MOKDAD L,et al. Towards an efficient and a more accurate web service selection using MCDM methods[J]. Journal of Computational Science, 2017(22): 253-267.
[2] WU Y, YAN C, DING Z, et al. A multilevel index model to expedite web service discovery and composition in large-scale service repositories[J]. IEEE Transactions on Services Computing, 2016, 9(3): 330-342.
[3] SHENG Q Z, QIAO X, VASILAKOS A V, et al. Web services composition: a decades overview[J]. Information Sciences, 2014(280): 218-238.
[4] CASATI F, ILNICKI S, JIN L J, et al. Adaptive and dynamic service composition in eFlow[J]. Seminal Contributions to Information Systems Engineering,2000(1789): 13-31.
[5] SCHUSTER H, GEORGAKOPOULOS D, CICHOCKI A, et al. Modeling and composing service-based and reference process-based multi-enterprise processes[M]. Berlin: Springer publishing international, 2000.
[6] CASATI F, SAYAL M, SHAN M C. Developing e-services for composing e-services[J]. Lecture Notes in Computer Science, 2001(2068): 171-186.
[7] BERARDI D, CALVANESE D, GIACOMO G D, et al. Automatic service composition based on behavioral descriptions[J]. International Journal of Cooperative Information Systems, 2005, 14(4): 333-376.
[8] BALDAN B, CORRADINI A, EHRIG H, et al. Compositional semantics for open Petri nets based on deterministic processes[J]. Mathematical Structures in Computer Science, 2001, 15(1): 1-35.
[9] HAMADI R, BENATALLAH B. A Petri net-based model for web service composition[C]. Australasian Database Conference, 2003: 191-200.
[10] WU D, PARSIA B, SIRIN E, et al. Automating DAML-S web services composition using SHOP2 [J]. Lecture Notes in Computer Science, 2003(2870):195-210.
[11] WAN Z, WANG P. A novel pattern based dynamic service composition framework[C]. IEEE International Conference on Services Computing, 2016: 235-242.
[12] PUKHKAIEV D,OLEKSENKO O,KOT T,et al. Advanced approach to web service composition[M]. Berlin: Springer International Publishing, 2015.
[13] CHATTOPADHYAY S,BANERJEE A,BANERJEE N. A scalable and approximate mechanism for web service composition[C]. IEEE International Conference on Web Services, 2015: 9-16.
[14] KUANG L,LI Y,WU J,et al. Inverted indexing for composition-oriented service discovery[C]. IEEE International Conference on Web Services,2007: 257-264.
[15] LALEH T,PAQUET J,MOKHOV S A,et al. Efficient constraint verification in service composition design and execution (Short Paper)[M]. Rhodes:On the Move to Meaningful Internet Systems: OTM 2016 Conferences,2016.
[16] JEONG H Y,YI G, PARK J H. A service composition model based on user experience in Ubi-cloud comp[J]. Telecommunication Systems, 2016, 61(4):1-11.
[17] SUNAINA X,KAMATH S S. Enhancing service discovery using cat swarm optimization based web service clustering[J]. Perspectives in Science, 2016, 8(C): 715-717.
[18] WU Y,YAN C, DING Z, et al. A relational taxonomy of services for large scale service repositories[C]. IEEE International Conference on Web Services, 2012: 644-645.
[19] WU Y,YAN C G,LIU L,et al. An adaptive multilevel indexing method for disaster service discovery[J]. IEEE Transactions on Computers, 2015, 64(9): 2447-2459.
[20] XU W, WU Y, LIU L. Performance analysis of multilevel indices for service repositories[C]. International Conference on Semantics, Knowledge and Grids, 2016: 103-108.
[21] KUANG W, WU Y, LIU L. Key selection for multilevel indices of large-scale service repositories[C]. IEEE/ACM International Conference on Big Data Computing, Applications and Technologies, 2017:139-144.
- 高校新生入学教育国内外现状分析与发展策略
- 专业学位领域的文献计量和知识图谱可视化研究
- 高校公共艺术课程选课需求测算与分析
- 地方本科院校实行本科生导师制的实践与探索
- 人文地理学专业大学生科技创新项目的开发及指导研究
- 基于电子设计竞赛的实验室开放项目的探索与实践
- “产学研用创”协同的大学生创新训练中心
- 深入文化育人理念,实施创造性艺术教育
- 师德教育与小学数学教学论的融合初探
- 高职实施分类培养、分层教学的探讨
- 能力导向的经济学专业应用型人才培养体系构建
- 强化地方高校工程人才培养特色的途径与实践
- 基于应用型创新性人才培养的园艺本科实践教学体系的探索与实践
- “新工科”背景下矿物加工专业人才培养的几点思考
- 应用型本科高校电子商务人才培养模式探索
- 高校办公室积极推进大学治理现代化的路径探讨
- 基于公平及博弈理论的高校教师激励机制研究
- 基于用人单位维度的高校毕业生就业质量评价体系研究
- 针对学生差异,探索“多元互动”教学模式
- 自我决定理论下的自主支持教学策略研究
- 高校教学质量提升探讨
- 中俄合作办学中研究性学习比较
- 现代大学制度视野下民办高校法人治理结构的设想
- “双创”视阈下建设高校创新创业文化的研究
- 毕业设计一年制教学改革与实践
- unjammed
- unjarred
- unjarring
- unjauntier
- unjauntiest
- unjaunty
- unjealously
- unjeered
- unjeering
- unjeopardized
- unjesting
- unjestingly
- unjeweled
- unjewelled
- un-jewish
- unjilted
- unjoinable
- unjoining
- unjoins
- unjointed
- unjoking
- unjokingly
- unjollier
- unjolliest
- unjolly
- 意念同义词
- 意念线索
- 意念被动句
- 意怀二三
- 意态
- 意态媚妩
- 意态安闲
- 意态异常
- 意思
- 意思1
- 意思2
- 意思、感情不自觉地表现出来
- 意思儿
- 意思恳切中肯,言辞毫无保留
- 意思意思
- 意思混淆不清
- 意思艰深难懂
- 意思表达得含蓄深刻,需要在绘画或文字之外细细体会才能理解
- 意思表达得很含蓄,需要在言辞之外细细体会才能明白
- 意思表达明显
- 意思还未完全表达出来
- 意怠
- 意急心忙抓心挠肝
- 意性
- 意怪