方芸 马林梓
摘要:该文以深度学习技术的前身机器学习为切入点引出接下来的研究,随后介绍了深度學习技术的基本概念,并通过图示来让晦涩难懂的概念更加简洁明了;再通过有无监督特征学习两个方面来探讨它未来发展方向及其应用,主要是音、像的识别和自然语言的处理,并在不同的领域分别进行举例介绍;最后讨论了在实践过程中出现的挑战以及未来的发展方向。
关键词:深度学习;机器学习;大数据
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2020)05-0190-04
开放科学(资源服务)标识码(OSID):
在大数据处理中,数据的计算、存储和分析是它的核心技术,而对大数据的有效分析就是大数据的价值所在。所以,大数据处理中的最核心、最关键的部分就是数据分析。而这些大数据的主要来源之一是互联网。每分每秒互联网上都有大量的网页和数不清的音视频、图像等数据产生。现如今,大数据越来越与人们的工作和生活密切相互关联,已经影响到了人们的方方面面。比如,从淘宝、京东等互联网上的电子商务交易到航空交通管制,从医生接触病人、诊断出什么疾病、并做出可治疗方案到警察局接到报警电话出警,再从通过天气预报来减少灾害的破坏到利用人民群众的举报来降低犯罪的发生等等,随处可见大数据的身影。但是目前,由于技术有限,只能分析和利用极少数的数据。这就要求需要研发新的更智能的数据算法技术,在大量无序且复杂的数据中找出规律并发现新的模式,从而提取出新的、有用的知识,来帮助人类做出正确的决策或给出预测。所以,利用深度学习技术和机器学习技术去分析大数据,尽量让机器代替人工分析数据,而这项技术也获得了广泛的应用前景[1]。
1 深度学习技术概述
1.1机器学习的发展阶段
要想领会、认识深度学习技术,首先要领会与其前身机器学习的相干的基本知识。作为人工智能领域的一部分,在大多数特定的情况下,可以由机器学习来代替人工智能,机器学习便是经由过程中出现很多分歧的算法,使得大量数据能被机器发现并学习其中的规律,从而对新总结出的数据样本做出智能辨认或者对将来可能产生的现象做出猜测。1980年前后,机器学习的大概发展阶段主要是两次,划分是:shallow learning(浅层学习)、deep learning(深度学习)。
1.1.1第一阶段:shallow learning
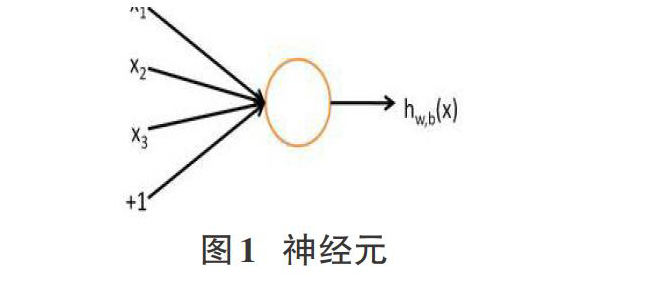
大概1980年前后,一种叫作反向传播算法作用于人工神经网络的发现(也叫作BP算法),让人们对机器学习技术燃起了新的希望。人们从中发现,在大批训练样本中,该算法能够通过运用人工神经网络模型来学习并从中找出新的规律,从而对将来不可知的事务做出尽量精确的展望。而人工神经网络又是什么呢?可以先从最简单的说起,最简单的人工神经网络就是由一个神经元组成,如图1[2]。
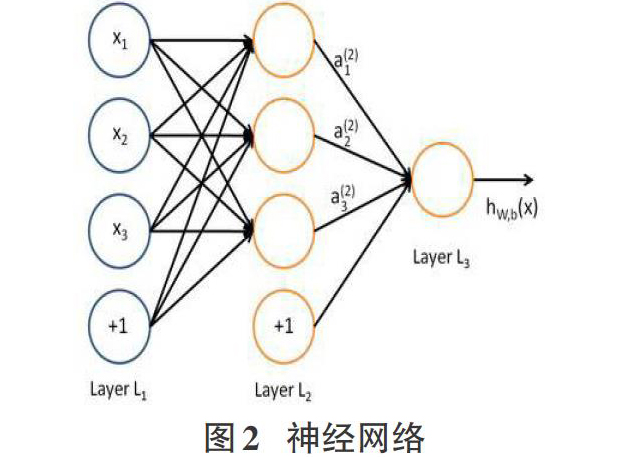
而多个神经元根据某些特定的方法互相结合起来,即这一个的输入是另一个的输出,就可以组成基本的人工神经网络,神经网络如图2[2],图中的圆形代表神经元的输入内容,最左边是输入层。
这类以数据统计为根本的机器学习方法,在很多方面要优越于以前以人工法则为根本的体系。这时的人工神经网络,因为在多层网络训练方面有很多困难,所以实际能被利用的大多数只是仅含有一层隐层节点的浅层学习模型。从1990年开始,提出了很多不同的机器浅层学习模型,比如support vector-machines,简称SVM(支撑向量机),以及最大熵方法等等。特别是从2000年开始,由于互联网络的发展,人们对大数据的需求变得更加急切,这也使得shallow learning在其互联网的利用中获得庞大的乐成。
1.1.2第二阶段:deep learning
2006年,机器学习理论的专家Hinton(加拿大多伦多大学教授)和他的学生Salakhutdinov在《科学》上发表了文章[1],正是这篇文章打开了深度学习在工业和学术界中研发的大门,从文章中可以大概得到两个重要的信息,首先,很多隐层的不被人们发现的人工神经网络有着十分优秀的特征学习能力.经过特征学习得到的数据有着更加本质性的刻画,对于可视化和分类非常有利;其次,在训练深度神经网络上,可以使用“layeI-wise pre-training”(逐层初始化)来解决其中的难题,而逐层初始化可以经由无监督学习来实现。同时从文中也可以得到一个重要的论据,那就是之所以深度学习技术可以被研发、被应用,是因为在脑神经系统中,的确存在着异常复杂、繁多的层次结构,从而使得深度学习的实现不再是空话。
所以,在当今这个大数据当家的时代,深度学习技术只能越来越炙手可热,谁能更快的取得深度学习技术的制高点,谁将更好地适应这个社会。
2 深度学习技术的分类
2.1 深度学习技术的分类简述
在深度学习中,可以通过有无监督特征学习两个方面来探讨它未来发展方向及其应用,而有无监督特征学习就可以作为深度学习技术的两个分类的依据,再在不同分类的基础上,研究它的特点和不同,以便人们更加方便的区分它们,并更加有效地利用它们,使它们在各自的领域发挥不同的功效,更好地为人类服务[3,4]。
2.1.1 无监督特征学习
在深度学习技术的研发中,无监督特征学习方法也称无监督的贪婪逐层学习方法,是最开始被提出来的中心思想:在深度结构模型中,将低层输出转化为高层的输入,然后无监督地学习一层特征的变换,最后形成的深度模型的初始化权值,就是由通过学习得到的网络权参数按顺序一层一层地码起来形成的,权参数在初始化时是在一个空间内,而这个空间是比较接近输入数据的流行空间的,因此在模型训练过程中,降低了陷入部分最小值问题的概率,这就像在过程中施加了正则化约束。
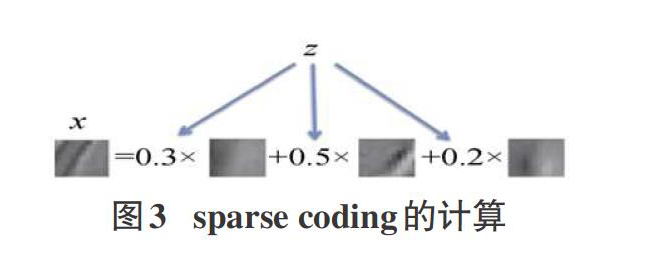
在训练数据过程中,有标签的数据数量比较少而无标签的数据数量较多时,可以采用无监督特征学习方法。而rest-rict-ed Boltzmann machine,简称RBM(也就是受限波尔兹曼机)、au-to-encoder,简称AE(也就是自编码模型)和sparse coding(稀疏编码)就是此中最主要的三个构成模块。其中sparse coding最为特殊,可以通过图片来了解它的原理,sparse coding的计算过程如图3[2]。
2.1.2 有监督特征学习
近年来,以有监督特征为基础的深度学习技术在计算机视觉的领域中取得了令人惊喜的研究成果,所以越来越多的人认为将深度学习技术从理论研究到实际的大规模应用是应该的。其中最受重视的模型是convolutional neural network,简称CNN(也就是深度卷积神经网络),也是所有深度结构模型最早获得成功的,其中CNN包含了多阶段的Hubel-Wiesel结构,如图4[4]。
专家LeCun研究的CNN是比较特殊的,该CNN是具有两种类型的层结构:卷积层和降抽样层[8]。每一层都有一种拓扑图结构,例如,每个神经元都对应着输入图像上一个固定的坐标,伴随一个感受野(输入图像上影响神经元活动的区域)。在每层的每个位置处,都有很多不同的神经元,每个神经元都有它自己的输入权值,连接着上层中一个立方体区域的神经元。不同位置的神经元都具有相同的一组权值,但对应着不同位置的立方体区域。
3 深度学习技术的应用
3.1 图像识别
在深度学习技术中最开始被应用的就是图像领域。在1989年,纽约大学教授Le Cun等人就开始了关于convolutionneural networks,简称CNN f卷积神经网络)的相关研究工作[9]。而CNN这一结构是如何被提出的呢?这多亏了在生物学领域的研究,人们正是在研究生物视觉行为时受到启发才提出这一结构,特别是通过研究在Hubel-wiesel模型中[10],模仿两个视觉皮层里的简单细胞与复杂细胞之间的行为动作时更加验证了这一结构。在过去的一段时间,CNN仅限在手写数字等小范围的领域上,获得了很好的体验结果,但在大范围应用上还没有得到大家的重视。而这一现象的产生主要是因为,CNN在大范围图像应用上还存在着问题,因此在计算机视觉领域上没有引起轩然大波。
这个低迷状态直到2012年才有所好转,在这一年图像识别技术取得了令人骄傲的大进步,而促进这一进步的正是加拿大多伦多的Hinton教授和他的学生们,他们在世界闻名的机器视觉识别问题上采用更加具有深度的CNN结构模型[3]。该模型的识别流程如图5。
在该识别模型中,全部像素的输入都是由机器独立完成的。随后在2013年,人们首次在简单图片的识别领域中运用了深度学习模型并取得了较大收获。从已知经验中可以看出,运用该模型能够从根本上解决一般模型识别正确率不高的缺点,从而减少了人们再返工的时间,大大节约了人力资源,这样在线计算的正确率就可以很大程度的提高了[6]。
图像识别也不仅仅是识别图像,随着研究的不断深入,也可以进行人脸识别、视频分析以及图像分类。其中人脸识别技术更加受到人们的追捧,因为人脸识别除了能够确认人脸之外,还能辨识不同身份的人脸,但由于不同的人有不同的身份,且相同的人由于在不同的场景拍照导致姿势、光线甚至脸型的变化,使得这一技术的实现更加困难。
综上所述,在未来深度学习技术一定会在图像识别领域中占据主要地位,并引领潮流,而以前的相对依赖人工的学习技术就会慢慢地退出时代的舞台。
3.2 语音识别
在人们开始使用语音识别系统的历史中,比较容易被人们接受的就是GMM(也就是混合高斯模型),这种模型一直在该领域起着非常重要作用,主要原因就是它有比较容易获得的区分度训练技术,有了这一技术的加持,再加上在进行大数据训练时估计较简单,所以更容易被人们接受[5]。但人无完人,同时这种模型也存在着许多弊端,比如,它从根本上来说就是一种网络层比较浅的建模,而网络层较浅就说明没有足够的深度来记录它的空间分布,虽然这一缺点可以通过区分度训练来解决一部分,但能起作用的空间还只是很小的一部分。其后,人们又开始运用DNN模型,但同样有着很大的弊端和不足。
后来,根据这一缺点,微软首先迈出第一步,比较有前瞻性的研究了以深度神经网络为基础的语音识别系统,正是这一研究颠覆性的解决了原有的深度不够这一缺点。新研发的系统,能够将原来不连续的语音片段通过描述片段之间的相似性合并起来,从而形成一个新的高维度的片段特征。
在实际应用过程中,这一技术,除了去其糟粕外,还取其精华,与原来的虽然不成熟但也有很多可取之处的语音识别技术相互联结,不但提高了语音识别的正确率还节省了不必要的开支,正可谓一举两得。
可以通过一个表,从三个方面来看看这三种模型的不同之处,如表1。
随后几年,谷歌和百度也相继采用了这一技术进行语音识别,不得不说这两大龙头企业非常具有前瞻性,这也对将来其他公司的业务拓展提供了资料。
3.3 自然语言处理(NLP)
在上文中已经了解到深度学习技术在音、像领域的应用,接下来还要介绍它在其他相对陌生的领域的应用,即自然语言的处理(NLP),顾名思义,它主要的研发方向就是通过自然语言使得原本沟通有障碍的人类和计算机之间能实现沟通,而自然语言的范畴也比较广泛,既包括人类语言也包括计算机语言,同时还注重这两者与數学之间的联系,因此涉及范围较广。
在过去的历史长河中,虽然以人工神经网络为基础的NLP模型一直存在,但由于研发的力度不够,使得人们只能一直应用存在弊端的以统计为基础的自然语言处理模型。随后,紧接着有许多学者渐渐意识到人工神经网络的重要性,开始转移了研究方向。直到2003年,Bengio(加拿大蒙特利尔大学教授)和他的同事首次提出用非线性神经网络代替原来的处理模型。而真正开始研究将深度学习技术应用于自然语言处理的是在2008年,在美国NEC研究所,Collobert研究员和Weston研究员为了有效解决原始模型不能完成词性标注、程序分块命名实体识别和语义角色标注等在NLP领域经常出现的问题,他们采用了通过嵌入多层的一维卷积结构的方法。在该方法中值得一提的是,不论是一个模型完成一个任务还是完成不同任务,正确率都较高。
同时自然语言处理大体上分为英文和中文两大方向,这两个方向的研究领域都有不同。 从整体上来看,深度学习技术在自然语言处理领域上不像音、像领域那样有较大的成绩,但我坚信在这一领域还有很大的发展空间,心急吃不了热豆腐,同样任何有价值的研究成果都不会因为时间的长短而止步不前。
3.4 搜索广告的收益预估
众所周知,搜索引擎收益的主要方式是通过用户搜索广告从而收费来获得,而计费方式也有很多,其中最常用的就是cost per click,简称CPC(即按点击付费)。所以需要通过一个比率,在按点击付费这一方式下,来预估收益,这个比率就是clikthrough rate,简称CTR(即广告点击率),也就是人们点击的广告的次数与该广告被检索阅读的次数的比率[11]。而这个比率越是精准,就越说明某个广告的点击次数多,从而说明收益越高。
而一般情况下,都是通过机器学习技术来预测得到广告的点击率,但这就会导致点击率的准确性不是很高,所以提高点击率的准确性是当务之急,这既可以提升用户的体验同时也可以为搜索公司和广告商带来高额的收益。
一开始,许多搜索引擎公司大都以逻辑回归模型(简称LR)进行预估,但直到2012年才发现,LR模型由于自身结构扁平的原因,使得对模型的分析和特征识别的效果大打折扣,人们这才知道广告点击率预估的准确性与模型的结构有着很大的关系[12]。为了解决这一问题,百度公司首次提出将DNN技术应用到于广告搜索领域,但在实施过程中却遭遇了许多问题和挑战,比如就目前的机器计算水平而言,还不能输入像1011这么高级别的特征广告,只能人为地将高级别特征数降低到一定水平,最后被DNN技术分析和学习[13]。而现在使用的广告搜索引擎正是来源于上述所描述的DNN技术,这也为广大网友提供了便利。
但是,DNN技术在该应用领域的影响还没有达到最大,在不久的将来,可以将DNN与迁移学习结合,这会大大提高点击率的正确性;同时还可以将不同的广告线联系在一起,这样不管再有多少不同的广告,数据之间都可以互通,可以大大节省计算的时间。相信以后的DNN技术在搜索广告领域中还会有更大的进步。
4 实践过程中出现的挑战
4.1 理论问题
通过这么多年研究,不论已知的函数多么复杂且难以表达,都可以找到一个深度学习技术的模型将它表示出来[14],但仅仅只是表示出来,还做不到完全可学习化,参数越复杂,过程越困难,也就是说必须要知道原始函数的复杂程度;另一方面,还需要更强大的计算能力帮助完成学习过程。对于这两方面的理论研究还有着巨大的研究空间。
4.2 模型问题
随着理论方面的更深入研究,在模型问题上也遇到了困难。首先,需要更强大的模型来处理,这个新型模型不但包含原来模型的基本功能,还要在原来基础上表现出更强大的学习能力。
其次,在不同的应用领域都需要不同的参数模型,这给日常建模造成了很大的麻烦,每次建模都需要重新定义参数,但这些模型也有一个共同点,那就是它们都是基于CNN理论的,所以能否找到一个通用的模型,不管应用在哪个领域都可以直接使用。
4.3 实际问题
众所周知,最开始只能在小范围图像数据领域应用深度学习技术,但随着研究的不断深入,在大范围数据领域也可以应用这一技术了,但是两个领域的最后处理结果几乎可以说是大不相同,这多亏了现代硬件设施比如CPU、内存等质量的提高,以及在平时训练中采取的其他线性或非线性的函数方法等[15]。
但是在最终处理结果上,由深度学习技术处理得到的结果与人类大脑处理得到的结果还是存在着很大差距,所以,还必须进一步去研究怎样改变机器固化的结构模型,并提高它们对数据处理能力的准确性。而随着数据量的持续增加,深度学习技术也不能故步不前,它们需要采用比原来更加繁杂、成熟的模型,通过提高自身的计算能力更加准确地提取数据中的信息去适应环境的变换。而做出这一改变最根本的就是,如何通过异步的更新模式将原本需要自身携带序列的学习算法,改进成可以利用CPU处理的并行学习算法,这将会大大提高计算的准确性。另外,大量的超参数在进行训练时也是必不可少的,而至今为止还没有明确的指导方法来告诉我们怎样选择超参数,所以在无形中增加了难度。最后,目前为止所有取得的成果都还没有强大的理论基础,还需要继续研究和发展。
5 结论与展望
深度学习技术为人工智能的研究开启了新的篇章,不仅受到了学术界的关注,也引起了商业等社会各界的重视,大大改变了人们的生活方式,为人们的生活提供了便利。同时它的应用领域也从音、像领域扩大到了自言语言处理领域。最后,虽然在研究过程中还存在着问题和挑战,相信我们一定可以解决,使深度学习技术的研究更加进步。
参考文献:
[1]余滨.深度学习:开启大数据时代的钥匙[D].厦门:厦门大学,2014:5-6.
[2]敖道敢.无监督特征学习结合神经网络应用于图像识别[Dl.广州:华南理工大学,2014:16-17.
[3]余凯.深度学习的昨天、今天和明天[J].计算机研究与发展,2013,5(1):3-5.
[4]李晨晓.基于深度学习的浮式储油卸油装置安全状态分类方法[D].天津:天津大学,2014:7-8.
[5]其米克·巴特西.基于深度神经网络的维吾尔语语音识别[Dl.新疆:新疆大学,2015:3-4.
[6]王强.面向大数据处理的图搜索与深度学习算法并行优化技术研究[D].长沙:国防科学技术大学,2013:5-6.
[7]雷振元.公务员应该掌握社会学基本知识[J].福州党校学报,2009,2(1):13-15.
[8] Yos hua Bengio. Learning Deep Architectures for Al[M]. New York: now publishers Inc, 1988: 15-16.
[9]张志强.基于特征学习的广告点击率预估技术研究[J].计算机学报,2016,5 (1):12-15.
[10]張志浩.基于深度学习的在线广告点击率预估系统的设计与实现[D].南京:南京大学,2015:5-6.
[11]李思琴.基于深度学习的搜索广告点击率预测方法研究[Dl.哈尔滨:哈尔滨大学,2015:13-16.
[12]毛勇华.深度学习应用技术研究叨.计算机应用研究, 2016,33(1):12-15.
[13]张驭宇.面向深度学习的分布式优化算法研究[D].北京:中国科学院大学,2015:113-116.
[14]梁军.基于深度学习的文本特征表示及分类应用[D].郑州:郑州大学,2016:3-6.
[15]和渊.用信息技术支持深度学习[J].当代教育家,2016(10):26-28.
【通联编辑:唐一东】
收稿日期:2019 -11-15
作者简介:方芸(1962-),女,本科,高级实验师,研究方向为计算机应用,实验室管理。
- 关于一稿两投和一稿两用问题处理的声明
- 循环血miR指标与前列腺癌分期及分化程度的关系探究
- 老年2型糖尿病患者下肢动脉彩超诊断的临床分析
- 高频超声在腕管综合征中的应用价值
- 混合性嗜铬细胞瘤临床病理分析
- 呼吸道核酸联合降钙素原检测在细菌性肺炎患儿中的诊断价值
- 腹部超声联合阴道超声在少见部位异位妊娠患者中的诊断价值
- AVE-562与KU-F10全自动粪便分析仪检测结果的比较
- 宫腔镜联合经阴道超声在子宫内膜病变中的诊断价值
- 妇科炎性感染中微生物检验的方法及效果研究
- 血清淀粉样蛋白A、胱抑素C与尿白蛋白/肌酐比值联合检测对早期糖尿病肾病的诊断作用
- 癫痫患者血清Hcy、血浆D-D、CRP的表达水平及与用药种类的相关性
- 降钙素原对经皮肾镜术后全身炎症反应综合征的早期诊断价值
- 急性脑梗死患者血栓弹力图与凝血功能检查的相关性分析
- 妊娠期糖尿病患者外周血中Th1/Th2细胞及相关细胞因子表达水平变化的研究
- 非酒精性脂肪肝合并T2DM患者血清IGF-1、IGF-2水平与胰岛素抵抗的相关性分析
- 组织悬液HER-2阳性标本在免疫组化室内质控中作为阳性对照的作用和价值
- 应用脑干听觉诱发电位诊断重症手足口病神经系统损害的价值分析
- 推拿手法联合揉足三里捏脊治疗早产儿泄泻的效果
- 内镜黏膜下剥离术与传统外科手术在消化道早癌或癌前病变患者中的应用效果
- 2型糖尿病患者血糖波动对血管弹性状态及肾血流的影响探究
- 加味痛泻要方对肝郁脾虚型腹泻型肠易激综合征中医证候疗效及生活质量的影响
- 连续股神经阻滞联合关节周围浸润镇痛对全膝关节置换术后关节早期功能恢复的影响
- 老年维持性血液透析患者并发心血管疾病的影响因素
- 中老年期精神分裂症患者代谢综合征患病情况分析
- uncosted
- uncostly
- uncostumed
- uncottoned
- uncounseled
- uncounselled
- uncountability
- uncountable
- uncountable nouns
- uncountenanced
- uncounteracted
- uncounterbalanced
- uncounterfeited
- uncourageous
- uncourageously
- uncourageousness
- uncourageousnesses
- uncoursed
- uncourted
- uncourtesies
- uncourtesy
- uncourtierlike
- uncourting
- uncourtlike
- uncouth
- 社会学
- 社会学习
- 社会学习论
- 社会学方法
- 社会学法学之父
- 社会学的鼻祖
- 社会学语言学派
- 社会安全
- 社会安宁,风气良好
- 社会安定
- 社会安定、太平
- 社会安定,五谷丰收
- 社会安定,天下太平
- 社会安定,没有战争
- 社会安定,治安良好
- 社会安定,犯法的人很少
- 社会安定,犯罪的人少
- 社会安定,百姓快乐
- 社会安定,秩序很好
- 社会安定,秩序良好
- 社会安定,繁荣昌盛的时代
- 社会安定,风调雨顺
- 社会实践
- 社会宣传
- 社会宣传系统