
摘 要: 为提高用户获取电影相关信息的效率和准确性,设计并实现基于知识图谱的电影自动问答系统。针对电影信息实体的特征,规范解析实体和实体之间的关系,构建电影信息知识图谱;通过对用户输入的问题进行实体识别与词性标注,进行问句分析,实现问句语义理解;利用贝叶斯分类器匹配问句模板在知识图谱上进行查找,从大量的非结构化数据中得到所需的具体信息,理解用户对于电影信息的需求。本系统通过构建电影的知识图谱结构对知识作了有效区分,实现更好的匹配效果。不仅简化了操作,还极大的提高了准确度,省时省力更高效。
关键词:自动问答系统;知识图谱;问句分析;贝叶斯分类器
Abstract: In order to improve the efficiency and accuracy of users' access to film-related information, an automatic question answering system based on knowledge map was designed and implemented. According to the characteristics of film information entities, the relationship between entities and entities is standardized and analyzed, and the map of film information knowledge is constructed. The semantic understanding of the question can be realized by entity recognition and part-of-speech tagging of the question input by the user. The Bayesian classifier matching question template is used to search on the knowledge map to obtain the required specific information from a large number of unstructured data and understand the user's demand for movie information. In this system, the knowledge map structure is constructed to distinguish the knowledge effectively and achieve better matching effect. Not only simplified the operation, but also greatly improved accuracy, saving time and labor more efficient.
Keywords: automatic question answering system; Knowledge map; Question analysis; Bayes classifier
引言
自動问答是一种高级的信息检索技术,支持用户针对事物属性或联系进行提问,国内外在自动问答系统上已经研究了较长时期,从上世纪60到70年代开始,问答系统就出现在人们的视线,主要依赖搜索技术,对查询相关的文档进行检索,如Yahoo早期的answer and quora[1]。而到了上世纪70年代,自动问答系统开始以结构化知识库为基础,通过搜索知识库得到最终答案,如YAGO[2]、WordNet[3]、张克亮等人基于本体的航空领域问答系统[4]。如今,随着人工智能的发展,利用知识图谱构建信息结构设计问答系统成为一种必然的趋势,如IBM的Watson系统[5]、马晨浩设计的基于甲状腺知识图谱的自动问答系统的设计与实现[6]。基于知识图谱提供的语义层面上支持的自动问答系统,包含信息分析、自然语言处理和机器学习领域的大量技术创新,能够帮助用户从大量非结构化数据中得到所需的具体信息,是新一代信息检索技术发展的必然趋势[7]。
知识图谱,源自于Google的Knowledge Graph,其本质是一种语义网络,结点代表实体或者概念,边代表实体/概念之间的各种语义关系。随着数据的结构化发展,互联网正从大量互相链接的网页向包含大量描述各种实体和实体之间丰富关系的语义网演进。
目前,中国作为全球第二大电影市场,同时也是增长最快的市场之一,人们对电影产业需求尤为突出。人们在电影的选择上,会经常利用当代主流搜索引擎对演员、剧情、导演等关键词进行搜索,如文献文科和百科等形式,但是反馈的结果往往需要通过主观上多次筛选,才能够获得自己真正想要的答案,并不能够直接提供一个清晰明了的结果,时效性非常低。与国外的自动问答系统相比,由于中文本身的独特属性,系统在理解自然语言问句上要比英文难。系统可以自动解析用户英文提出的问题,不需要考虑问句分词和理解误差,如Microsoft Concept Graph[7]。但是从中文角度,系统总是理解的模糊不清。国内外现有的电影信息自动问答系统,大多以SSH框架为基础或利用tensorflow实现电影信息的问答,如Google中国版电影onebox[8]、时光网等,基于知识图谱实现的电影自动问答系统并不多。
本文打算做的,即是电影信息领域的自动问答系统,在对大量的电影信息做出有效的整理后,创建生成电影信息知识图谱,基于该知识图谱,在Java平台上实现电影的自动问答系统,用户输入问题,系统对输入的自然语言进行问句分析,匹配不同语义的不同模板,在知识图谱内进行查询,获取答案。该系统结合了多种自然语言处理技术,能够帮助使用者从大量的非结构化数据中得到所需的具体信息,理解用户对于电影信息的需求。
1系统架构
整个系统主要分为数据获取与存储模块、自动问答系统实现模块、用户交互模块等三个模块,具体描述如下:
(1) 数据获取与存储模块,主要是将分布在不同网站的爬虫文件获取到的电影数据信息进行整理存储在MySql数据库中,根据数据库中的数据构建出电影信息的知识图谱,供后期问答业务的处理和实现使用。
(2) 自动问答系统实现模块,主要是以设计的电影信息知识图谱为基础,系统将用户输入的问题,进行实体识别与词性标注,根据识别后的实体,对问题进行分类,匹配不同的问句查询模板,使用模板在知识图谱上进行查找,得到用户问题的最终答案并返回用户。若问题实体识别后,词性标注为实体本身,则直接在知识图谱内进行搜索,返回用户答案。
(3) 用户交互模块,指用户在使用时所看到的额人机交互界面,提供给用户查询问题并获取答案。具体系统模块结构图如图1所示。
2电影信息知识图谱的构建
本系统通过分布在不同网站的爬虫文件,聚合各大电影门户网站的电影信息,存储在MySql数据库中,并提取文本中的命名实体,使数据结构化,从而构建电影信息的知识图谱,这增强了文本的表示和组合模型[9],使用户直接获取电影信息之间的关系。同时利用知识图谱能将问句中实体和关系识别出,确定问题意图,映射对应的问题模板,形成对应的语序图,得到准确的答案。从现有的研究成果来看,知识图谱的技术还主要应用在科技专业领域的研究,而对于非科技专业的领域,如搜索一些普通的资讯信息,还停留在普通的搜索引擎阶段。因此,针对电影信息这类非科技专业领域构建知识图谱,能够将数据搜索范围缩小,从而有利于提高知识搜索的准确性和高效性。
2.1数据获取与处理
数据获取主要采取的途径是利用网络爬虫自动获取。
网络爬虫(Web crawler)又被称为网页蜘蛛(Web spider),是一种按照一定的规则,自动地抓取万维网信息的程序或脚本。因为互联网上的页面是由多个各大网站的URL相互链接起来的,所以首先从一个或若干初始网页的URL开始,获得初始网页上的URL,在爬取网页的过程中,不断从当前页面上抽取新的URL放入队列,根据页面标签的正则匹配算法,过滤与主题无关或无用的信息,保留有用的信息并建立索引,直到满足系统的一定停止条件。
电影信息的获取是通过爬取各大电影门户网站的数据,如百度百科、豆瓣网、时光网、M1905、中国电影票房网等。自动获取的电影信息主要包括电影的基本信息,如电影类型、剧情介绍、评分等;演员的基本信息,如姓名、角色、性别等。通过对页面标签的正则匹配,抽取电影各类实体关系的信息,整理存储在MySql数据库中,以备后续操作。
2.2知识图谱的构建
电影信息的表达形式,是该系统的一个重要组成部分。随着计算机科学领域和人工智能领域的发展,自然语言处理在机器学习和深度学习相关的算法下取得了突破,比如语义解析、语言建模等[10]。2012年,Google通过将如语义解析、语言建模等系统化后,提出“知识图谱”,从而越来越多的计算机领域研究学者和开发设计者,将知识图谱应用在知识的表达形式上。融合知识图谱,能够使系统自动给将问题中实体和关系识别出来,基于模板的方法对结构化查询进行问题的描述[11],形成对应的语序图,通过查询知识图谱中的三元组得到答案。
本系统电影信息知识图谱根据MySql数据库中存储的电影信息构建,包括电影名称信息实体、电影类别信息实体、演员信息实体等,实体之间存在多种联系,规范解析实体和实体之间的关系,将数据库中不同表内的不同数据,以三元组<实体,关系,实体>形式构建电影信息知识图谱的概念層设计。
定义1 电影信息实体 包括电影名称实体、电影类别实体、演员信息实体等。实体名称存放于根目录,每个实体都包含一组属性[12],在定义了电影信息实体之后,可以构建电影信息知识图谱概念层设计如图2所示。
定义2 电影基本信息关系实体 电影信息关系实体表示电影信息实体间产生的联系,如<电影名称,电影信息,演员>。其中,电影名称、演员都是电影信息的实体,而电影信息为电影基本信息关系实体。电影基本信息关系类型主要包括内容如下:
(1)A is B关系:表示实体A有一个属性实体B。
(2)A actedin B关系:表示实体A出演实体B的关系。
最后抽取实体和关系,综合确定三元组,借助Neo4j服务中Cypher模板文件存储数据,将模糊的查询条件转化为精确的查询区间[13],有效的管理每个节点的特定属性,以及每条边与实体之间存在的关系。知识图谱设计模式图如图3所示。
查询语句[14],利用JDK提供的一些低级API,用基于图的模式匹配,实现对数据的处理与扩展。同时,Neo4j能够非常方便的融合到系统中进行后续开发。本系统使用Neo4j构建的电影信息领域的知识图谱可视化展示如图4所示。
本系统主要构建以电影信息为核心的知识图谱,以电影名称为根节点,以此延伸出电影的名称、时间、剧情介绍、演员等信息,每一级的节点又可以延伸至下一节点,如将章子怡节点进行展开,可以看得到与章子怡相关的所有电影。电影信息知识图谱的节点可视化展开如图5所示。
3问句分析
问句分析主要研究问句的抽象以及问句的分类等自动问答系统所采用的对中文进行自然语言处理的技术,使系统对问题的理解准确度得到提升
3.1问句的抽象
问句的抽象是针对中文进行自然语言处理的基础步骤,也是实现数据标注处理的基础模型。与英文问句相比,系统可以通过疑问句中固定的疑问词自动解析用户英文提出的问题,但中文具有本身的独特属性,中文提出的问题无明显词性的界限,因此进行中文问句的自然语言处理时,利用分词技术实现问句的抽象是第一步。
将知识图谱中的实体概念和属性等词加入领域词库,标注单词的词性,并添加部分人工标注的命名实体,比如问句中会涉及到的专有的电影名称、人名、剧情等实体,完成自定义带有词性的字典数据[13]。这相当于提供给机器人一个习题集,所谓的标注,就是将整个数据、正确答案作为习题集教给机器人,机器人在学习过程中,就会在做题过程中在习题集内搜索答案。
系统在收到用户提出的问题后,能够自动进行问句抽象,对问句进行分词处理,将中文转化成系统能够理解的语义,更加贴合用户的意图。
3.2问句的分类
由于中文的独特属性,不像英语具有专属的疑问词、时态与语法,用户输入的问题具有随意性,即表达相同意思的词语可以被多种同义词所替代,表达某一问题的问句可以被随意组合成多种问句。根据电影信息知识图谱,自定义带有词性的字典数据,将问句定义成不同的类别。问句分类如表1所示。
3.3问句的匹配
对于输入的自然语言,首先进行问句的分类,根据问句类别的关键词,构造出问句类别向量,进行问句匹配,映射其对应的问句模板,形成对应的有向语序图。问句匹配是从概率学的角度进行分类,如果将用户输入的问句与知识库中存在的问题库进行最高程度的匹配,则系统反馈给用户的答案也将更加准确、快速。
目前常用的分类算法朴素贝叶斯分类器(na?ve Bayes classifier)、支持向量机(support vector machine)与最大熵模型(maximum entropy model)等[15]。其中朴素贝叶斯分类器能够在复杂的场景中,使对文本训练集的速度较快且准确。考虑到本系统的研究主要在于准确和问题样本的特点,需要从电影的名称这类实体和人工标注的问题分类两个方面进行匹配计算,所以选择采用朴素贝叶斯分类器。首先我们要清楚什么是贝叶斯定定理,当事件B已经发生,事件A发生的概率叫做事件B发生下事件A的条件概率,其基本求解公式为:
现有事件B,则在事件A发生的条件下,事件B发生的概率,其基本求解公式为:
朴素贝叶斯分类器是基于贝叶斯定理,根据特征项,选取预测类别,再进行概率计算的分类方法,具体实现的数据模型可以表示如下:
4答案生成
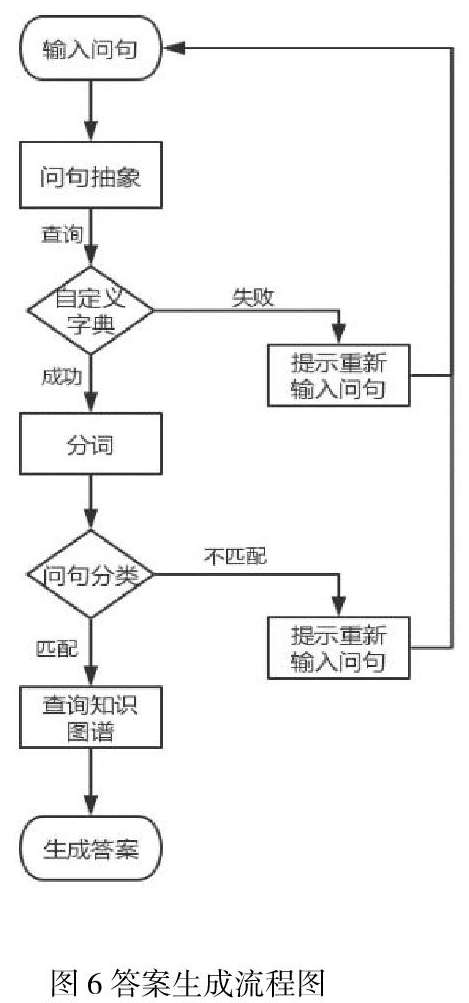
本系统的答案生成主要就是通过朴素贝叶斯分类器实现。答案可能是一个单词、一个句子片段、一个结构良好且有意义的句子或一组逻辑连贯的句子。答案类型取决于问句的抽象与匹配[16]。基于知识图谱的自动问答系统通常包括为特定领域开发问答对数据库,然后根据用户的问题获取答案。在用户输入问题时,此时问句为原始句子,利用分词器对原句子进行抽象,将其中电影名称、人名等用自定义的词典进行替换,并与事先训练好的朴素贝叶斯分类器中问题样本数据集进行匹配问题模板,判断是否为匹配。若匹配,则直接返回模板中匹配的最终标准问题给用户,并去图形数据库Neo4j中查找问题的答案;反之,则将预测的结果反馈给用户,提示用户输入有效问题。答案生成流程如图6所示。
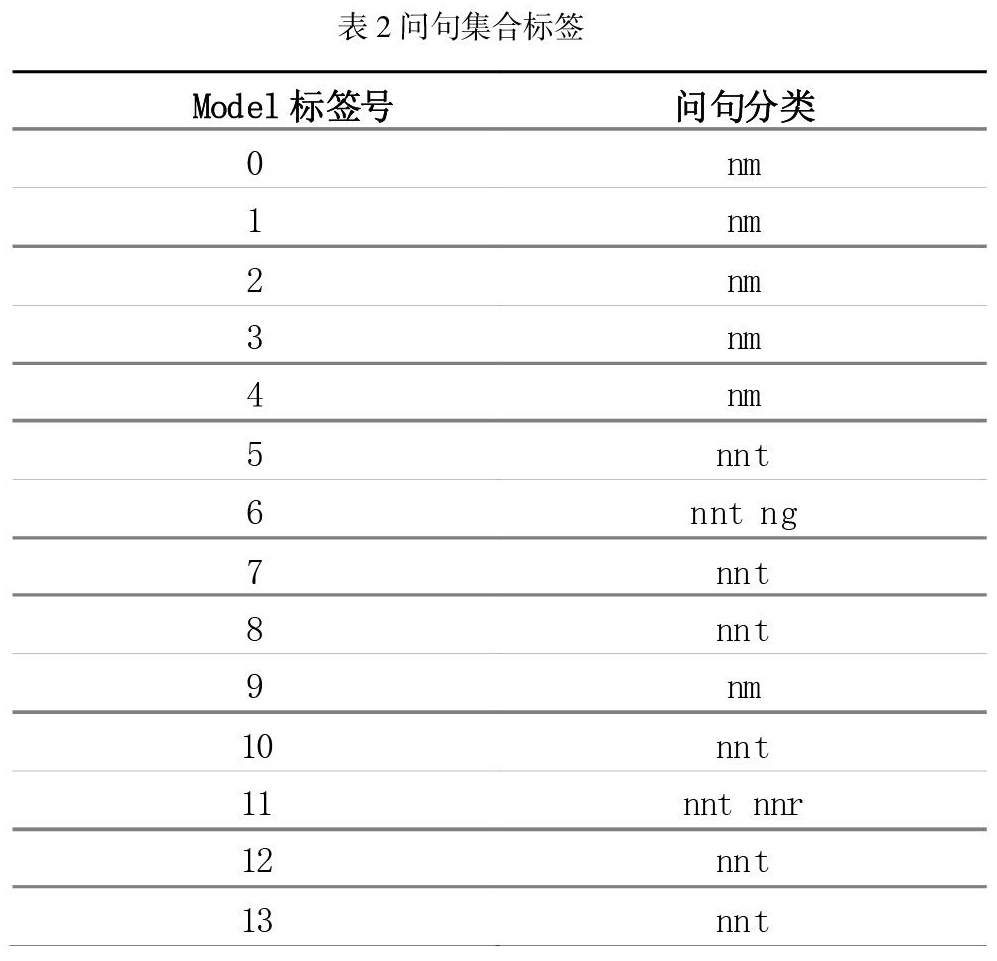
根据之前自定义好的数据词典,设计用户可能会提出的问题,将问题词汇集合成vocabulary数据集,之后按照数据集设置问题集合,分类Model标签号,具体问题集合如表2所示。
对原始问题进行分词,提取关键特征词,如“评分”、“多少”等和数据集中关键特征进行匹配,在贝叶斯分类器中构造向量,进行词汇数据集的比对,若有则返回1,反之返回0。
实现答案的查询过程只要时将问题有序语句转换成Neo4j的查询语句,在图形数据库中进行查询。在结构化查询语言中,键值时完全匹配的,但是用户输入的是模糊查询,所以需要将用户输入的模糊查询,转换为统一键值,再翻译为Neo4j图数据库的标准查询语句Cypher,從而再知识图谱上进行查询,如查询某电影出演的演员有哪些,可以表示为“match(n:Person)-[:actedin]-(m:Movie) where m.title ={title} return n.name”。若遇到不相关的词语,则用贝叶斯分类器进行特征值和问题模板的匹配,从而完成答案的生成。
5实验结果与分析
5.1 实验一 问句词性识别标注为实体本身类问题
输入:<实体>
实例输入:章子怡
预期结果:Beijing-China,人工查询知识图谱中章子怡对应为Beijing-China。
实验运行结果如图7所示。
5.2 实验二 问句识别为人工标注的问题-电影评分
输入:<实体>评分是多少?
实例输入:英雄的评分是多少?
预期结果:7.3,人工查询知识图谱中英雄的评分对应为7.3。
实验运行结果如图8所示。
5.2 实验三 问句识别为人工标注的问题-演员电影作品
输入:<实体>出演了哪些电影?
实例输入:章子怡出演的冒险电影有哪些?
预期结果:Godzilla: King of Monsters, Godzilla vs. Kong, 卧虎藏龙, 英雄, TMNT, 十面埋伏。人工查询知识图谱中英雄的评分对应为Godzilla: King of Monsters, Godzilla vs. Kong, 卧虎藏龙, 英雄, TMNT, 十面埋伏。
实验运行结果如图8所示。
6结束语
随着互联网的不断发展,自动问答系统正在日趋完善。以电影信息为数据,构建基于知识图谱的电影自动问答系统,在人工标注和自动化结合的方式下,构建了电影知识图谱和问题词汇数据集,并设计了多种可能的问题模板,即帮助系统理解用户意图,利用知识图谱获取用户想查询问题的准确答案。可以存储大量的数据的同时,在后续数据应用方面相比较传统模式也占据了明显优势。
在未来,本系统将会在已有基础上,不断扩展电影信息的知识图谱,使得自动问答系统能够处理的问题信息更多,并且不断完善贝叶斯朴素分类器模型,提升被提取特征值的准确率和速率,保障在自动问答模块上的稳健性。
参考文献:
[1]刘乙蓉,刘芸.问答平台中的答案聚合及其优化[J].图书馆学研究,2017,6.
[2]Suchanek F M, Kasneci G, Weikum G. Yago:a core of semantic knowledge.In:Proceedings of International Conference on World Wide Web,2007:697-706.
[3]Miller G A. WordNet:a lexical database for English. Commun ACM,1995,38:39-41.
[4]张克亮,李伟刚,王慧蘭.基于本体的航空领域问答系统[J].中文信息学报,2015.
[5]孔鹿.IBM的Waton如何改善中国医疗[N].第一财经日报,2016-08-30(A08).
[6]马晨浩.基于甲状腺知识图谱的自动问答系统的设计与实现[J].智能计算机与应用,2018,8(3):102-107.
[7]孟明明,张坤,论兵.一种面向知识图谱问答的语义查询扩展方法[J/OL].计算机工程.
[8]Google谷歌中国版电影onebox上线[C].CFan PE:软件学用通.
[9]安波,韩先培,孙乐.基于知识表示的知识库问答系统[J].中国科学:信息科学,2018,48(11):1521-1532.
[10]薛蕊,马小宁.自然语言处理关键技术在智能铁路中的应用研究[J].计算机应用,2018,27(10):40-48.
[11]Dominic Seyler, Mohamed Yahya,Klaus Berberich.Knowledge Questions from Knowledge.Graphs arXiv:1610.09935v2 [cs.CL],1,Nov,2016.
[12]Yuan Yang,Jingcheng Yu,Ye Hu,Xiaoyao Xu,Eric Nyberg.CMU LiveMedQA at TREC 2017 LiveQA: AConsumer Health Question Answering System,2017.
[13]李雪.一种基于Neo4J图数据库的模糊查询研究与实现[J].计算机技术与发展,2018,28(11):16-21.
[14]刘峤,李杨,段宏,刘瑶,秦志光.知识图谱构建技术综述[J].计算机研究与发展,2016,53(3):582-600.
[15]李文宽,刘培玉,朱振方,刘文锋.基于卷积神经网络和贝叶斯分类器的句子分类模型[J/OL].计算机应用研究.
[16]Ashwini Jaya Kumar , Christoph Schmidt, Joachim K?hler .A knowledge graph based speech interface for question answering systems :Speech Communicatio 92(2017),1-12.
作者简介:
徐宇晨(1997-),女,民族: 汉 ,籍贯:江西景德镇,学历 :大学本科,职称:无,毕业院校:无,研究方向:软件工程 飞行器控制技术.
- 中美中小企业公共商务信息服务水平比较研究
- 完善人力资源管控体系构建多元化薪酬模式
- 企业人力资源管理的不足与改进措施探讨
- 新媒体时代下现代企业营销策略创新研究
- 广西中小企业电子商务发展分析研究
- 对工业企业项目成本管理和控制措施的研究
- 企业管理体制创新途径探析
- 技术能力与技术管理能力协同发展的路径
- 现代供应链管理视域下的社会管理机制探究
- 军工科研院所事业单位改制面临的问题及对策
- 现代社会组织体制问题探究
- 事业单位岗位设置管理的难点与对策
- 社会主义和谐社会与生态文明间的关联性
- 国土资源交易纳入公共资源交易管理的思考
- 劳动合同法与就业促进法对人力资源建设发展的影响
- 事业单位人力资源管理改革分析
- 浅论环境公益诉讼的原告资格
- 韩国的互联网管理政策变迁
- 公众参与对社会保障基金管理的影响及完善途径
- 承德市旅游产业发展研究
- 我国基层政府公信力建设研究
- 公共图书馆信息化建设及创新服务研究
- 加强和改进党委中心组学习制度的管理探究
- 事业单位职工离职文档管理研究
- 内蒙古基本公共服务均等化研究
- postpregnancy
- postpresidential
- post-primary
- postprimary
- postprison
- postprophetic
- pick-out
- pick-over
- pickpocket
- pickpocketed
- pickpocketing
- pickpockets
- picks
- pick sb's brains
- pick sb/sth out
- pick sb/sth up
- pick sb/sth ↔ out
- pick sb up
- pick somebody/somethingup
- pick somebodyup
- pick somethingup
- pick something up
- pick sth off
- pick sth up
- picks up
- 诗句中最精练传神的一个字
- 诗句极优秀
- 诗句清新
- 诗句的末尾
- 诗句的语气
- 诗句语法的反叛
- 诗句题词
- 诗可以兴,可以观,可以群,可以怨
- 诗史
- 诗吊汨罗魂
- 诗名
- 诗吟饭颗
- 诗启
- 诗吻
- 诗呆子
- 诗味
- 诗和偈
- 诗和散文
- 诗和文
- 诗和词
- 诗和词的格调
- 诗和赋
- 诗和辞赋
- 诗咏
- 诗咏于归