摘要:互联网是信息的载体,随着信息量的迅速增長,给用户检索获取需要的互联网学习资源增加了难度和时间。因此,学习资源爬虫是亟待研究与解决的问题。实现学习资源爬虫系统的关键为:首先界定互联网学习资源的概念、类型、格式形态,然后设计学习资源爬虫结构以及抓取、解析、去重、下载功能,最后根据系统开发环境实现爬虫结果。借助webdriver、Firfox浏览器并结合反网络爬虫策略,解决动态网站脚本与服务器异步交互时的数据丢失问题,进行完整、自动、高效的批量内容下载,优化学习资源获取的准确率与效率,以获取更有价值的学习资源。
关键词:网络爬虫;Web网页;学习资源
中图分类号:TP319
文献标识码:A
文章编号:16727800(2017)004011103
0引言
随着信息技术的发展,互联网信息量呈指数级爆炸性增长[1],信息淹没在浩瀚如海的互联网数据中。用户要从海量、异构、半异构、动态数据中快速获取有价值的学习资源是非常困难的。网络中学习资源数据量庞大,百度、Google检索也仅收录了页面的1/3,基于汉语自身的复杂性及特点,检索获取有价值的学习资源效率低、花费时间长[2]。为此,设计并实现了一个学习资源爬虫系统,使学习资源检索能快速、准确地达到预期目标。首先对学习资源的概念、类型、格式作一定阐述与界定。学习资源是指学习、教育被应用、参考,并以数字化信息加载的一切对象;学习资源类型是指试题、试卷、案例、问题解答、媒体素材、网络课程、网络课件;学习资源格式是指HTML、TXT、Word、PPT、PDF、Excel格式的文本或文档。
1系统总体设计
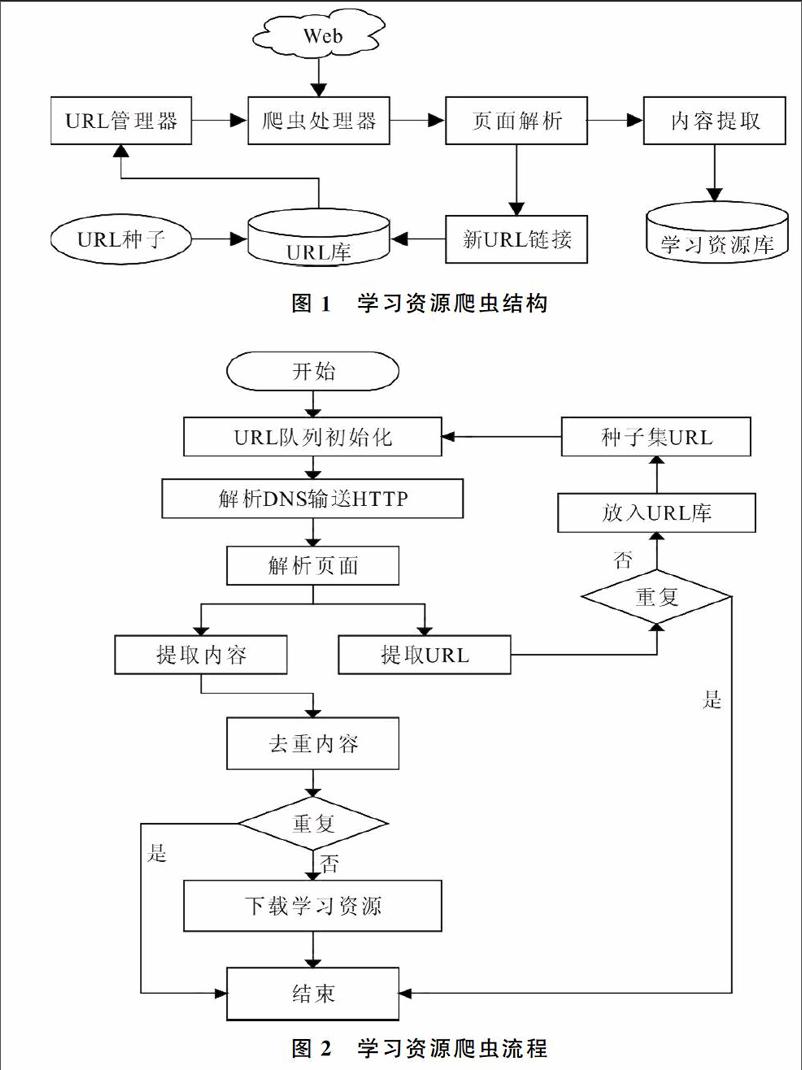
聚焦网络爬虫(Web Crawler)也称为主题网络蜘蛛,是一个自动下载网页的计算机程序。设置初始的URL(Uniform Resource Location)队列序列化开始爬取,解析原URL指向的网页并提取新的URL链接与页面信息,提取过程中对网页信息、文档文本进行过滤,剔除重复、不符合要求的URL及文本文档,下载有关主题信息储入数据库,并且不断遍历整个过程,直至程序报错或达到系统的预定规则而停止[3]。本系统设计学习资源爬虫结构如图1所示,根据系统的爬虫结构,其功能模块主要包括:网页抓取、网页解析、内容去重、内容下载。系统的功能模块其学习资源爬虫流程如图2所示。
2系统功能模块
2.1网页抓取
网页抓取策略包括深度优先搜索策略、最佳优先搜索策略、广度优先搜索策略。深度优先搜索策略在深度大、数据多时,抓取深度、命中率以及抓取效率会大幅下降,同时由于受系统堆栈容量限制,内存也会产生溢出;最佳优先策略是一种局部最优搜索算法,需结合具体应用进行改进;广度优先搜索策略必须考虑溢出和节省内存空间的问题,运行速度要比深度优先搜索快很多。本文采用广度优先爬虫策略结合反网络爬虫策略,网页抓取时应配置爬虫网页的脚本,配置网页脚本为XML、Groovy文件,XML用于限定爬虫的对象范围,过滤与学习资源无关的信息;Groovy用于限定爬虫对象内容的范围,为网页内容过滤掉“广告条”以及网页下方的网站说明等信息。系统启动时将初始的URL种子集队列放入Redis SitesQueue临时数据库,并不断地从Redis队列中抽取URL,解析其DNS,访问网页协议HTTP、主机名、路径,建立网络通信发送请求报文,连接Web服务器下载页面并把页面内容及链接信息保存到本地磁盘上[4],以节约主机内存的占用,提高网页抓取效率。
2.2网页解析
网页解析是网页处理的起点,程序发送请求信息,协议允许访问页面则进入页面框架。通过解析类ParserFile.class对HTML网页进行DOM解析,其中包括HTML标签、元素内容、脚本内容、注释等,用index处理HTML中的标签、文本、注释、指令,以及这些符号之间的语法关系,如标签与标签、标签与文本的关系。主要解析标签包括:正文标题(Title)、正文内容(Article)、链接(Link)、作者(Author)、发布时间(Publishtime)、来源(Source)。用inline处理锚文本对应URL链接节点下的“href”属性,获取锚文本与URL之间的对应关系。在DOM解析与URL语法解析的基础上,即可进行网页内容的识别操作[5],提取内容进行去重处理,提取链接URL进行判断处理。解析主要代码如下://判断fileDir文件的第index个dom中,有无
2.3内容去重
目前Internet的重复网页约占35%~45%,大部分是内答转载。爬取这些网页或者重复内容既占用网络带宽又浪费资源,用户不希望收集一堆内容相同或近似的检索结果。因此,程序启动之前已配置网页脚本为XML、Groovy文件,在URL中限定了爬虫对象、内容的范围,剔除了与学习资源无关的信息内容。程序运行时,处理爬虫过程中存在的重复网址,剔除重复学习资源内容或文本文档。互联网学习资源范围和数量庞大,选择好的去重策略,能节约大量爬虫时间,提高爬虫效率[67]。程序对Redis缓存内容去重效率相当高,对内存要求也相对较高。同时Redis要关闭VM功能,需要设置好redis.conf配置文件,因为内存使用过高将导致内存溢出。内容去重主要包括正文标题(Title)、正文内容(Article)的去重,是一种高效去重的方法。
2.4内容下载
网页分为静态和动态。静态网页由HTML代码生成,页面的内容、结果基本不会有变化;动态网页是相对静态的一种网页编程技术,具有如下几个特点:交互性、更新性、效果动态性。由于动态网站脚本与服务器异步交互易产生数据丢失,需借助Firfox浏览器、Webdriver测试工具解决该问题,以进行完整、高效、自动的批量网页内容下载。系统运行主程序MainQuartz和子程序ListStart、DetailStart时,ListStart子程序根据节点下载网址的主列表,DetailStart子程序下载列表项内容。List表下载链接URL、时间、标题、来源,Article表下载正文内容、发布时间、来源、作者、描述、关键字。下载模块始终在监听等待爬虫List表和Article表,如果为空,则处于等待状态;如果不为空,则下载列表内容,查看HeidiSQL数据库管理界面,存储记录每一条爬取成功的信息。
3系统开发环境
硬件配置:CPU为Intel Core i5,内存为8G,硬盘500G。 软件配置:操作系统为Windows7 64bit,软件集成开发工具为Eclipse,开发语言为Java,数据库为MySQL、Redis。 本系统需要对Redis缓存内容去重,对内存要求会偏高,因此采用CPU Intel Core i5,内存8G。开发工具是以Eclipse为集成框架,开发语言采用Java,因已生成的类包库可以直接调用,简单方便。Redis作为缓存数据库,可大幅提高爬虫效率,也相对减轻了對内存的需求,很大程度上避免了内存溢出,MySQL为存储数据库。
4系统爬虫结果与结论
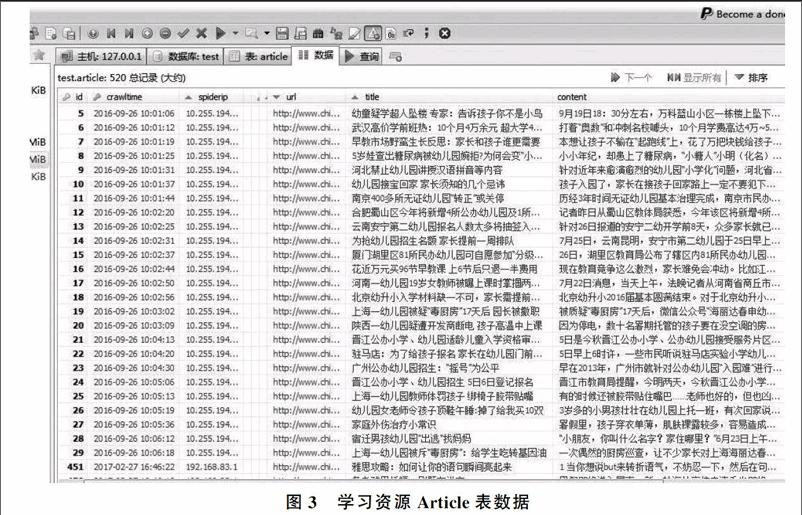
根据爬虫结构、功能设计与系统开发环境的配置,爬虫数据来源于中国教育信息网、百度文库资源、小学资源网、小教资源网,以及部分研究机构与高校的共享资源等。爬取学习资源Article表数据如图3所示。由List表和Article表的数据可知,List爬虫存入数据库的平均速度为1.3页/秒,Article表爬虫存入数据库的平均速度为6.5页/秒,学习资源爬虫的平均速度为4.0页/秒,准确率在95%左右。系统可大幅提高抓取学习资源的准确率与效率,同时提升了获取的学习资源的价值性。
爬取的学习资源为HTML、TXT、Word、PPT、PDF、Excel的文本或文档。其中影响爬虫的因素有网速、网址服务器以及学习资源的文本或文档大小等。本文设计的学习资源爬虫系统采用广度优先爬虫和反网络爬虫策略,通过解析类ParserFile.class对HTML网页进行DOM解析,通过程序对Redis缓存内容去重,并借助webdriver、Firfox浏览器,进行完整、高效、自动的批量网页内容下载,改善了网络爬虫易被屏蔽的缺点,降低了爬虫难度与任务量,同时解决了动态网站脚本与服务器异步交互的数据丢失问题,优化了学习资源获取的准确率、效率,从而获取更多、更有价值的学习资源。
参考文献:[1]孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术,2010(15):41124115.
[2]杨彦军,郭绍青.ELearning学习资源的交互设计研究[J].现代远程教育研究,2012(1):6267.
[3]J CHO.Crawling the Web:discovery and maintenance of largescale Web data[J].International Journal of Advances in Engineering Sciences, 2001,3(3):6266.
[4]翁岩青. 网页抓取策略研究[D].哈尔滨:哈尔滨工程大学,2010.
[5]王璟琦. 基于内容单元的网页解析与内容提取[D].哈尔滨:哈尔滨工业大学,2008.
[6]黄聪会,张水平,胡洋.主题Deep Web爬虫框架研究[J].计算机工程与设计,2010(5):929931,935.
[7]孙涛,曹丙章,邱荷花.基于MapReduce的视屏爬虫系统研究[J].华中科技大学学报:自然科学版,2015(5):129132.
(责任编辑:黄健)
- 日本专门职业院校的升学制度和学位授予管理机制
- “互联网+实习”背景下欠发达地区转型高校面临的困境及出路
- 新形势下改进高校党员教育探析
- 高职旅游管理专业高端技能人才培养模式探索
- PI制在高校科研项目管理中的应用研究
- 食品“卓越工程师”人才培养模式改革思路
- 管理中的营销学
- 医学院校生物技术实验教学的安全管理初探
- 谈现代远程教育学习支持服务的策略与方法
- 优秀传统德育资源缺失对高校德育工作的影响研究
- 高校学业困难学生助推工作机制探索与实践
- 建立客运出租汽车行业信用考核机制的思考
- 传统批发市场业态转型升级与新兴产业的融合发展
- 道德与法律并重构建社会诚信体系
- 分析环境监测技术在海域中的研究
- 莒国文化旅游资源开发初探
- 群体性突发事件的网络舆情引导与应对
- 环境改变及图书馆联盟协同服务构建探讨
- 浙江舟山水产品价格指数预测与对策
- 江苏创新型乡镇的发展路径分析
- 农民专业合作社发展研究
- 政府主导视角下的创业型城市环境建设问题研究
- 加快发展福建自贸区入境再制造产业的对策
- 新时期法律对网络购物诈骗的治理措施研究
- 我国狱务公开方式创新研究
- unadministered
- unadministrative
- unadministratively
- unadmirableness
- unadmirablenesses
- unadmirably
- unadmissible
- unadmissibleness
- unadmissiblenesses
- unadmissibly
- unadmittedly
- unadmonished
- unadoptable
- unadoptional
- unadoptive
- unadoptively
- unadorable
- unadorableness
- unadorablenesses
- unadorably
- unadored
- unadoring
- unadoringly
- unadroit
- unadroitly
- 山涧里走船
- 山涨
- 山清水秀
- 山渊
- 山渌
- 山温水暖
- 山温水软
- 山源
- 山溜可以穿石
- 山溜穿石
- 山溪
- 山瀑
- 山火
- 山灰
- 山灵
- 山炭
- 山烧
- 山燕子嘴——瞎啾啾
- 山父
- 山狖
- 山狙
- 山狸猫坐门墩——假充镇山虎
- 山猪
- 山猫
- 山猫儿