王丽辉 张娜 罗晓玲
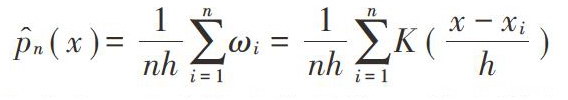


摘要:该文分析了基于非参数核密度估计技术的点云数据法向量算法的相关问题,文章先分析了非参数核密度估计技术的相关内容,并对其建模内容进行阐述;之后在非参数核密度估计技术的基础上,研究了点云数据法向量算法,希望能对相关人员工作有所帮助。
关键词:非参数核密度估计技术;点云数据法;向量算法
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2018)06-0215-02
在计算机图形学的几十年发展历程中,基于多种网格造型并绘制简单的数据结构,已经成为现阶段交互式图形绘制的主要手段。但是从应用来看,这种方法依然存在一定的局限性,包括拓扑信息数量大、难以维持密集汇集点的网格操作等。针对这种问题,点云数据应运而生,有效满足了当前建模、绘制技术的要求,产生了巨大的影响。因此在当前环境下,重视对点云技术的研究更具有实际意义。
1非参数核密度估计技术的基本内容
在传统学术研究中,很多学者在研究参数概率密度函数的估计内容时,总是假设概率函数的参数形式是已知的,并在这种条件下完成对数据信息的分析。但是越来越多的学者认为,一些特殊的假设条件是否成立有待商榷,并且从人们的实际生活中可以发现,很多学者提出的概率问题实际上只有很少的部分能符合实际情况,这一现象最终导致参数概率密度估计方法的应用价值受到影响。
非参数核密度估计技术就是在上述问题的基础上发展起来的,这一技术属于非参数统计学的范围,这一技术的出现改变了传统统计学的格局,为数据处理模型中那些不能被完全处理的数据提供了一个新的统计方法。该方法与传统的点云样本参数密度估计方法相比,非参数密度估计方法不需要对样本的分布情况进行假设,而是依靠采样数据本身所存在的特点进行估计。
在这种情况下,非参数核密度估计方法依靠统计直方图的理论得到逐渐的演变,在这个过程中,核密度估计采用核函数的方法,对窗口中的相关数据点进行加权平均,并且在获得数据点的概率密度与分布规律后进行综合的研究。假设在某个维度空间下,存在着n个数据点,这些数据点的表达方式分别为:(x1,x2,x3…xn),这些数据都是取值于R的独立分布变量,并且服从分布函数密度p(x),在这个条件下,假设任意一点x的取值范围为(x∈R),此时x点的核密度估计值为:
在这个公式中,K(·)代表核函数,n代表样本容量,h代表光滑参数或者带宽。根据该公式的基本结构,可以对该公式进行解读:核密度估计以每个采样点的中心局部函数为基础,在确定这些局部函数加权平均数效果的基础上,确定平均效果对该数据密度函数的影响,并确定其估计值。在这个公式中,核函数一般以“0”点为基础,采用对称、单峰等结构为支撑的概率密度函数。并且也有研究证明,核函数在实际上是一种权函数,其核密度估计则是依靠数据点x到xi之间的距离,来确定x点在估计xi点密度时所发挥的作用。
一般在应用非参数核密度估计技术时,必须要充分考虑多维空间核密度的估计问题,在假设存在一个m维度的空间,其n个数据点的表达方式为(x1,x2,x3…xn),此时x1(xil…xim)T。此时将一维度的核密度估计值做进一步的推广,并利用乘积核与对称正定对角型带宽矩阵的结构来判断具体的核密度估计值。
2非参数核密度估计技术下的点云数据法向量算法研究
2.1最大核密度估计
根据上述公式内容,观察数据中第i组的残差为估计值,则该数值与实际观察值之间的误差也是变化的。在这种情况下,采用回归分析的方法,依靠最小化或者最大化的残差数据的目标函数来判断整个回归系数参数。从目前点云数据法向量算法的特征来看,在这种约束条件下的非参数核密度估计技术就是要假设内部服从高斯分布的特点,并且占据了数据点的相对多数。在这种情况下,假设模型的拟合条件基本正确,则要保证其内点的残差无限接近于零。此时,假设残差空间原点处具有零残差的概率密度特征,在这种情况下,就必须要保证残差空间原点处的概率密度空间度尽可能的高。
2.2点云数据法的关键点选取
關键点又被称为兴趣点,在点云数据法中可以通过一定的算法检测出具有稳定特征、可区别特征的点,此类点的集合就被称为关键点集。在点云数据法的关键点选取中,每一个点都具有特殊性,并且能够携大量的数据(信息),因此在点云数据法的向量算法中,有关关键点的选取一直是相关人员工作的重点内容。
在研究过程中,根据向量算法的特征设计一个关键点的获取方法。首先,要保证这个关键点的主要成分分析估计点云的向量与曲率特征情况,在此基础上,就能根据目标点p与相邻区域内的点构建多个协方差矩阵,并确定点的向量特征情况,此时则有计算公式:
同时在这个过程中,根据多种向量之间的特征来选择其约束条件已经成为选取关键点的关键。此时应该保证不同半径所表示的邻域曲面存在不同的变化程度,所以已经被改变的半径大小计算得出的向量可能存在角度偏差,此时夹角的偏差越大,则证明邻域的变化越明显。在这种条件下统计计算目标点邻域半径的向量,并根据阈值约束分离出关键点。在这种情况下,满足向量的点就是关键点,并会构成关键点集合。
2.3非参数核密度估计技术下的关键点集合判断
在一般情况下,采用非参数核密度估计技术对样本数据的内容进行处理,并确定“最典型”的样本数据资料,并且根据非参数核密度估计技术的基本特征,在关键点集合研究中不需要对完整的从数据样本的内容来确定其分布特征,那么在这种约束条件下,可以假设第j个特性指标xj的第T个样本为关键点。此时,为了保证关键点的连续性,要保证核函数通常为关于y轴的对称单峰平滑概率密度函数,这样才能在最大限度上满足关键点集合能够满足点云数据分析的要求。为了保证数据分析质量,可以采用Gaussian函数对这种关系做进一步研究。
2.4实验分析
为了进一步判断非参数核密度估计技术下点云数据法向量算法的关键点,本文提出下列实验:
实验1:假设平面Z=X为测试点云,随机在该点云内采集样本121个,其中采样单据为10个。此时估计质量与窗宽、邻域、重复次数等均为常数。在这种情况下,根据正常的数据处理条件,向平面点云中加入70%的比例,此时邻域r=40,重复次数m=200;在这种约束条件下,实验结果显示方差等于零,证明点云为干净点云,估计质量等于1,则证明上述点云内的采集样本能够成为数据集。
实验2:文献在相关问题的研究中,选择球面为测试点云,此时球面的表达方式为X2+Y2+Z2=502。在这种条件下,球面坐标参数θ、φ的采样步长为π/100,采集441个样点。该文献在实验分析中的相关条件,如图l、图2所示。
根据图1、图2所确定的条件,就干净点云而言,其邻域越小,则估计精度越高。在这种情况下,文献为了确定三种研究方法的处理在点云处理中的应用效果,将实验分析的约束条件设定为0,并且假设较小的领域r=10,图中数据可以看出,在这种条件下,MKDE、QMDPE、MDPE的估计质量分别为0.998626、0.998765、0.997498,这三个数值都接近于零,则证明这种方法下的441个点为数据集合。
通过对上述两种方法进行分析,发现两种方法都能判断点云数据法分析中关键点集合,但是在应用实验1的方法时必须要充分考虑假设条件的情况,只有这样才能保证关键点集合的科学性。
2.5点云数据法向量分析
在整个点云数据法的向量分析中,考虑到非参数核密度估计技术的特点,在解决各种关键点的数据特点后,必须要根据点云数据的特点,再配合不同情况下的非参数核密度估计技术,这样才能在最大程度上保证点云数据法向量算法的精准性。所以在这种情况下,必须要了解点云数据法向量算法的要点,从数据的特征入手对其进行改进。
在这种情况下,本文介绍了一种基于核密度估计的目标分析技术。为了阐述核函数对于整个向量算法的影响,本文根据表1所给出的数据对核函数带宽进行界定,并判断不同核函数的点云数据分析情况,最后根据文献所介绍的對数据内容进行分析。
在表1的约束条件下,采集多样样本点,并分别对应Uni-form、Biweight、Guass、Cosinus核函数确定定位效果。在这个过程中,代表目标的关键点集合已经明显的偏离了点云的中心,而导致出现这一问题的主要原因就出现在Uniform上,Uniform核函数本身就是一个常数项,这种情况会导致密度分布峰值之间存在不明显的现象,并且在峰值点上会出现不同的数据偏差。这一结果说明,除了Uniform以外的各种函数都能基本确定点云数据法向量算法中的关键点集合情况。
结论:基于非参数核密度估计技术在点云数据法向量算法中具有良好的应用价值,能够显著提高点云数据法向量算法中的数据处理问题。本次研究结果可知,在整个数据分析中,要将对关键点的处理与控制作为数据处理的关键,这样才能更有效地提高整个点云数据法向量算法的数据处理结果。
- 对高中英语如何备课的建议
- “师友互助”模式在初中英语教学中运用初探
- 浅谈提高初中英语课堂教学效率的方法
- 初高中英语阅读衔接教学的现状及其对策
- 教师指导学生扩大词汇量的几点建议
- 写好高中英语作文的关键点分析
- 高中英语研究性学习与教学思路探析
- 高中英语教学中的问题与对策
- 初中英语单元复习课对话式教学初探
- 话题型任务模式在人教版初中英语教材中的应用分析
- 初中英语口语教学中任务型教学法应用研究
- 初中英语情境化教学思考
- “注意”理论在合作学习中的应用探微
- 新课改理念下的高中英语阅读教学
- 浅谈初中学生英语阅读理解能力的培养
- 初中英语学困生学习态度与学习策略的研究
- 导学案教学在高中英语阅读教学中的应用
- 夯实词汇基础,提高英语水平
- 浅析高中英语教学策略
- 初中英语合作学习中存在的问题及对策
- 讨论式教学法在高中英语教学中的应用研究
- Seminar教学模式在高中英语语法教学中的实践研究
- 探索高中英语阅读课中的有效词汇教学
- 浅谈任务教学法在英语词汇教学中的运用
- 浅析语言初级学习者在英语写作中需要把握的语言准确性问题
- undecidedness
- undecidednesses
- undecideds
- undeciphered
- undeclarable
- undeclining
- undecomposed
- undecompounded
- undecorate
- undecorates
- undecorating
- undecreased
- undecree
- undecreed
- undecrepit
- undedicated
- undeduced
- undeducible
- undeducted
- undeductible
- undeductive
- undeductively
- undeeded
- undeemed
- undeep
- 谦亨
- 谦亮
- 谦人
- 谦仁
- 谦以下士
- 谦以自牧
- 谦俭
- 谦光
- 谦光自抑
- 谦克
- 谦兢
- 谦冲
- 谦冲自牧
- 谦函
- 谦则受益
- 谦匿
- 谦卑
- 谦卑地表示完全同意或顺从
- 谦卑恭顺而讨好的样子
- 谦卑自牧
- 谦卑顺从的样子
- 谦卑顺服的样子
- 谦却
- 谦厚
- 谦受益