郑浩鑫 林楷焱 陶铭

摘? 要: 在现实生活中,人们具有丰富的情感,而情感会影响人的行为及认知等。为了获取并识别人类的情感,提出一种基于深度学习的“视觉情感识别系统”的设计方案。通过Python语言编写网络爬虫程序,爬取网络上带有情感标签的人脸图片,从而为神经网络的训练提供数据;采用Keras框架搭建卷积神经网络,对带有情感标签的人脸图片进行深度学习,使卷积神经网络收敛到理想的模型,从而实现对人脸图片的情感识别。实验结果表明,该方案具有一定的识别效率。
关键词: 网络爬虫; 深度学习; 卷积神经网络; 情感识别
中图分类号:TP393? ? ? ? ? 文献标识码:A? ?文章编号:1006-8228(2021)03-33-04
Design and implementation of visual emotion recognition system
Zheng Haoxin, Lin Kaiyan, Tao Ming
(School of Computer Science and Technology, Dongguan University of Technology, Dongguan, Guangdong 523808, China)
Abstract: In real life, people have a wealth of emotions which will affect people's behavior and cognition, etc. In order to acquire and recognize human emotions, a design scheme of "visual emotion recognition system" based on deep learning is proposed. To provide data for the training of neural networks, the Python language is used to write a web crawler to crawl the face pictures with emotional tags on the network. Keras framework is adopted to build convolutional neural networks for deep learning of face images with emotion tags, so that the convolutional neural networks converges to an ideal model to realize the emotion recognition of face images. The experimental results show that the proposed scheme has certain recognition efficiency.
Key words: web crawler; deep learning; convolutional neural networks; emotion recognition
0 引言
人的情感能夠表达出人的想法和行为。人对于情感的利用有很多方面,例如教学中研究学生的情感以便即时关注学生的心理活动;商家通过客户的情感来对商品和服务进行改进;企业通过研究员工的情感来对工作进行合理分配等。对于情感的获取渠道也有多种,比如图像、声音和文字等[1-2]。
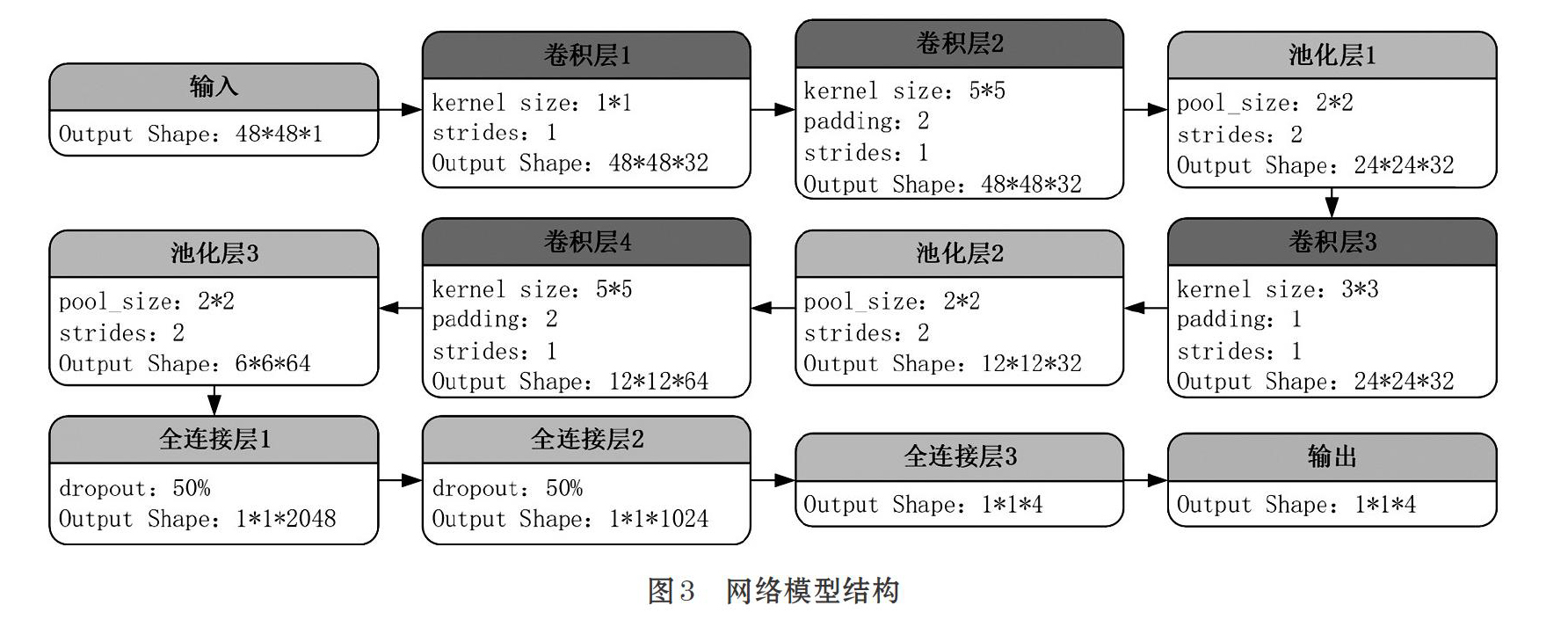
本系统是在人脸检测基础之上的更进一步地研究[3],通过识别人脸的表情来获取人的情感。先使用网络爬虫技术和人脸目标检测技术从网络上爬取带有情感标签的人脸图片并按照训练图片所需的格式对图片进行处理。然后使用Keras框架,来进行卷积神经网络的结构设计和参数优化[4-6],并且通过爬取的图片数据,来对卷积神经网络进行多次迭代训练,从而得到一个理想的情感识别模型。最后实现对人脸情感的识别。
1 系统架构
系统主要有两大模块。爬虫模块负责爬取数据和对图片数据进行格式化处理;训练模块负责生成TFRecord训练文件、搭建卷积神经网络模型,并对其进行训练和识别人脸的情感。
1.1 爬虫模块
1.1.1 网络图片爬取
本项目使用Scrapy框架进行图片爬取[7]。首先确定爬取图片的网址,然后根据需要要爬取的标签和网页页码得到完整的URL列表并发送给调度器,接着调度器分析URL地址响应内容并找出图片下载地址。最后,只需在Scrapy框架里的setting中设置好下载路径,就可以启动引擎调度各模块,让爬虫程序自动下载这些图片。为防止浏览器阻止python爬虫程序爬取网页图片,还需要修改setting里的ROBOTSTXT_OBEY为TRUE以及让爬虫程序每一次爬取网页时使用不同的USER_AGENT。图片爬虫流程图如图1所示。
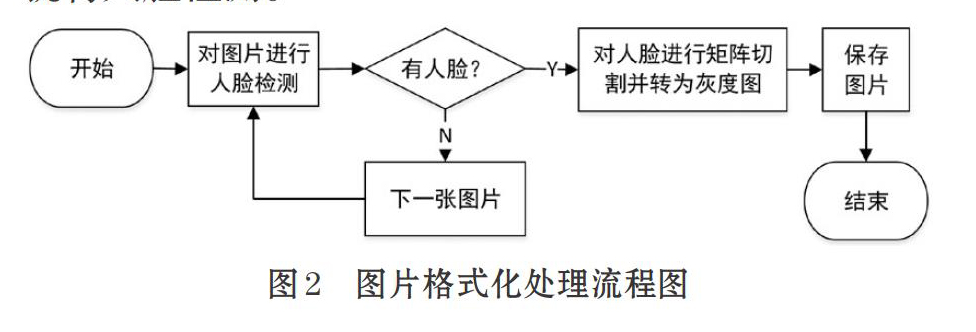
1.1.2 图片格式化处理
本项目对爬取的图片进行格式化处理将用到Dlib库和Opencv库。如图2 所示,图片格式化处理流程为:先使用Dlib库的人脸目标检测函数循环检测每一张图片,若检测到人脸,则使用Opencv库的图片切割函数对人脸进行矩形框切割并转为灰度图,然后保存图片;若检测不到图片,则跳过此图片选取下一张就行人脸检测。
1.2 训练模块
1.2.1 生成TFRecord文件
本系统通过网络爬虫模块爬取的图片已经放到了对应的标签目录下。首先把每个标签目录下的图片按照比例分为train,test和val这三部分,然后生成对应的TFRecord训练文件,分别为train训练集,val验证集和test测试集。train训练集用于卷积神经网络的训练;val验证集是训练过程中的测试集,主要是用来判断网络是否过于拟合,以便网络参数的调整;test测试集是在网络模型训练结束后,用来评估网络模型效果的测试集。
- 新形势下小学德育
- 新课程语境下如何在小学音乐教学中融合德育
- 让美育之花绽放“艺”彩
- 农村留守儿童的思想品德教育现状与对策
- 立德树人在小学数学课堂中的应用
- 浅谈高段品德与社会在各学科教学中的渗透研究
- 浅谈班级管理中的沟通艺术
- 优化班级管理 构建和谐班集体
- 小学德育中渗透中国传统文化的实践研究
- 关于新形势下小学德育的探索
- 课堂因情境而生动
- 小学班主任班级管理的实践与创新活动探索
- 小学品德课小组合作学习存在的问题与对策
- 浅谈小学英语课堂教学创新探究
- 巧用思维导图,提高英语阅读素养
- 积极语用下的文体分类
- 谈小学语文作文“先导式”教学
- 让幼儿懂得爱,学会关心
- 语文课堂呼唤思辨式阅读
- 几何直观在低段数学教学中的运用
- 例谈几种常用思维导图在小学语文阅读教学中的应用
- 激扬生本课堂,实施有效的小组合作学习
- 读懂教材本质,灵活用好教材
- 激发学生学习兴趣 提高课堂教学效果
- 基于翻转课堂的小学语文口语交际教学模式研究
- wire service
- wire sth (to sb)
- wire sth (up)
- wiretap
- wiretapping
- wire transfer
- wiretransfer
- wire wool
- wire²
- wire¹
- wirier
- wiriest
- wirily
- wiriness
- wirinesses
- wiring
- wirings
- wiry
- wisdom
- wisdomless
- wisdomness
- wisdoms
- wisdom teeth
- wisdom tooth
- wise
- 流便
- 流俗
- 流俗的言论
- 流俗词源
- 流俗词源学
- 流借
- 流僈
- 流充
- 流光
- 流光似水
- 流光如水
- 流光如箭
- 流光如驶,节序怀人
- 流光容易把人抛
- 流光易逝
- 流光溢彩
- 流光烁石
- 流光烁金
- 流光益彩
- 流光瞬息
- 流光荏苒
- 流光逐逝,盛年难再
- 流光铄金
- 流入
- 流入主流的河流