李博 齐耀龙
摘要:“消费者就是上帝”对于教育行业来说也一样,所以来自“上帝”——学生的反馈就是推动教学的助推剂。和各级教育机构一样,在高校中也会有学生对教师的评教,有的分项打分,有的可以文字叙述。由于学生人数较多,直接打分还好处理,主观评价的分析就比较困难了。在耗费了大量的T時后可能还是不能得到想要的结论,那就要考虑自动分析了。这里在比较了主流自动分析方法后,推荐使用深度学习的方法来进行数据挖掘达到了很好的效果。
关键词:情感分析;深度学习;评教;自动分析;python
中图分类号:TP311.1 文献标识码:A
文章编号:1009-3044(2020)20-0082-02
1引言
在高校的基础计算机教学中,由于教师和学生见面的时间比较短,再加上班级人数有时比较多,所以学生评教就成为反馈中的重中之重。2020年初的学期由于疫情的影响,都在进行网上授课,与学生之间的见面时间更是基本为零,特殊时期教师与学生之间沟通的方法除了社交媒体就剩下网上评教系统了。
评教系统一般分为客观打分和主观评语两部分,其中客观打分可以直接在Excel中进行分析,形成图表,而主观评语部分以往都是人工进行查看,但是评语太多,工作人员往往走马观花,抓不住要点;或者直接发给教师自己看,也会因为太多,大部分教师根本不看。造成了本来最重要的学生的心声反而被丢弃了,长此以往评教必将成为面子事,失去了教师学生间的最好最直接的沟通桥梁。
2解决思路
学生对教师的评语实质上就是情感问题,可以进行情感分析。情感分析也称为意见挖掘(Opinion Mining),是自然语言处理(NLP)的一个领域,它构建的系统,用于在文本中识别和提取观点。学生对于教师的评语主要分为主观性评价和客观性评价。客观性评价是客观性描述,不带有感情色彩和情感倾向,主观性评价则是学生对教师或者教学方法的看法或想法,带有自己的喜好厌恶等情感倾向。区分主客观评价主要以情感词识别为主。
目前主观性文本情感倾向性分析的研究工作,主要研究思路分为基于语义的情感词典方法和基于机器学习的方法。基于语义的情感词典方法主要利用已构建的词典(目前中文情感词典的构建主要是对知网How net的扩充),对语料库进行中文分词处理,然后扫描每个单词,与情感词典中的词进行语义相似度计算,当相似度达到一定阈值时即可判断该词的情感倾向和权值。由于中文的多样性灵活性,加上词典庞大的词汇量和不够高效的匹配算法,这种方法的分析正确性难以突破。而另一方面,最近几年,以Google公司和Facebook公司为首的企业在深度学习领域有了很大的突破。所以我们决定采用基于机器学习的方法,用Python这种在AI方面有突出应用的语言来对学生评价进行分析数据挖掘,形成有用的模型,反馈回教师进行改进提高。
3具体实现
评语分析,用的是Python的基于SnowNLP类库的数据分析挖掘方法。原有库的字典是以电子商务的买卖东西的评价为基础的,所以我们又把以往对教师和教学的评价词语,包括褒贬以及权值加入字典中,进行训练后,再用来分析评教评语。
下面是对评价的具体分析步骤(以一条评语为例):斜体为输出结果。
from snownlp import SnowNLP
text=‘备课充分,讲的也还可以。但是不注意和学生的互动,尤其是对提问缺乏耐心。
s= SnowNLP(text)
1结果一:分词
print(s.words)
[‘备,‘课,‘充分,‘,,‘讲,‘的,‘也,‘还,‘可以,‘。,‘但是,‘不,‘注意,‘和,‘学生,‘的,‘互动,‘,,‘尤其,‘是,‘对,‘提问,‘缺乏,‘耐心,‘。]
l结果二:词性标注
tags=[x for x in s.tags]
print(tags)
[(‘备,‘v),(‘课,‘n ),(‘充分,‘ad),(‘,,‘w),(‘讲,‘v),(‘的,‘u),(‘也,‘d),(‘还,‘d),(‘可以,‘v),(‘。,‘w),(‘但是,‘c),(‘不,‘d),(‘注意,‘v),(‘和,‘c),(‘学生,‘n),(‘的,‘u),(‘互动,‘v),(‘,,‘w),(‘尤其,‘d),(‘是,‘v),(‘对,‘p),(‘提问,
收稿日期:2020-03-16
基金项目:河北大学工商学院第二批课程建设项目(2019KCJS38);河北大学第二批“课程思政改革试点课程”建设项目(KCSZ-02-117)
作者简介:李博(1973-),男,河北保定人,讲师,硕士,主要研究方向为计算机软件设计、人工智能等。‘vn),(‘缺乏,‘v),(‘耐心,‘an ),(‘。,‘w )]
l结果三:断句
print(s.sentences)
[‘备课充分,‘讲的也还可以,‘但是不注意和学生的互动,‘尤其是对提问缺乏耐心]
l结果四:情绪判断
返回值为正面情绪的概率,越接近1表示正面情绪,越接近0表示负面情绪
print(text, s.sentiments)
备课充分,讲的也还可以。但是不注意和学生的互动,尤其是对提问缺乏耐心。0.6773729723566638
l结果五:关键字抽取
print(s.keywords(limit=10))
[‘互动,‘学生,‘不,‘耐心,‘缺乏,‘提问,‘课,‘备,‘还,‘讲]
l结果六:概括总结文章
print(s.summary(limit=4))
[‘备课充分,‘讲的也还可以,‘但是不注意和学生的互动,‘尤其是对提问缺乏耐心]
l结果七:信息衡量
TF-IDF是一种统计方法,用以评估某一字词对于整体文件的重要程度。TF词频越大越重要,但是文中会的“我”,“你”,“的”,“得”等无意义词频很大,却信息量几乎为0,这种情况导致单纯看词频评价词语重要性是不准确的,因此加入了idf。lDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t越重要。TF-IDF综合起来,才能准确的综合的评价一词对文本的重要性。
s= SnowNLP([[‘講的一般,‘比较充分],[‘很好,‘有耐心,‘有耐心],[‘很好,‘易懂,‘比较好][‘好老师][‘比较好,‘好老师]])
print(s.tf)
[{‘讲的一般:1,‘比较充分:1},{‘很好:1,‘有耐心:2},{‘很好:1,‘易懂:1,‘比较好:1},{‘好老师:1},{‘比较好:1,‘好老师:1}]
print(s.idf)
{‘讲的一般:1.0986122886681098,‘比较充分:1.0986122886681098,‘很好:0.33647223662121295,‘有耐心:1.0986122886681098,‘易懂:1.0986122886681098,‘比较好:0.33647223662121295.‘好老师:0.33647223662121295}
l结果八:文本相似性
print(s.sim([‘好老师]))
[0,O, 0.44592706058233045. 0.3508241329699851]
print(s.sim([‘有耐心]))
[0,1.4052017645754893,0,0,0]
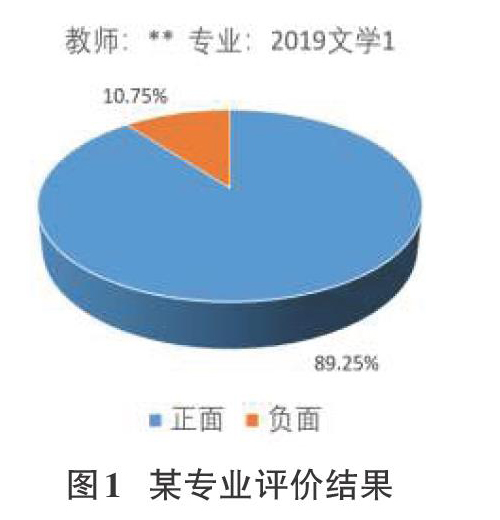
分析完成后,用图表的方式把每个专业的分析结果直观地显示出来(图l)。
4结论
目前系统经过几次对学生主观评价的分析,准确率能达到86%左右。而且随着使用的次数数据越来越多,深度学习的优势就会越来越明显。把原有的人工分析方法占用的教师和教辅的时间释放出来更好地为实际教学服务。
以前的评教基本上是每学期一次,因为原来分析方法落后,评教后的结论迟迟不能出炉。现在学生其实可以做到每次课后都提供实时评价,系统实时提供结论,就可以更好的在教学中做到扬长避短,根据每个班的实际情况进行教学的实时调整,真正做到因材施教。
参考文献:
[1]厉小军,戴霖,施寒潇,等.文本倾向性分析综述[J].江大学学报,2011,45(7): 1167-1175.
[2] Kuma R A, Sehastian T M. Sentiment analysis on twitter[J].International Journal of Computer ScienCe lssues, 2012, 9(4):628-633.
[3]李方涛.基于产品评论的情感分析研究[D].北京:清华大学,2011.
[4]朱嫣岚,闵锦,周雅倩,等.基于How Net的词汇语义倾向计算[J].中文信息学报,2006,20(1): 14-20.
【通联编辑:王力】
- 初中数学教学的常见问题与优化对策研究
- 创设情境优化数学课堂的教学研究
- 浸润式教学:初中英语三学课堂教学实践研究
- 词汇理据下的初中英语词汇教学研究
- 《“口语100”平台对初中生英语口语表达能力的作用研究》课题研究中期报告
- 基于传统美食文化的初中英语主题活动的开展
- 初中语文主题阅读教学浅析
- 基于阅读期待的课堂教学模式的核心要素解读
- 小议一道浮力题的难点突破
- 数学课堂有效提问入手点的思考
- 实现初中生物生活化教学的几点思考
- 思辨让思想深刻
- 初中道德与法治课课程资源开发之我见
- 浅谈初中地理教学中师生互动对教学效果的影响
- 在“情感”的土壤里培育“情怀”的种子
- 初中作文教学之我见
- 初中语文教学中存在的常见误区及改善对策
- 初中语文作文教学困境及对策分析
- 顾此不能失彼
- 一次自晒视频让综合性学习“活起来”
- 生本理念下的激励型课堂构建
- 合作学习在初三化学教学中开展的措施
- 浅谈多样化教学在初中篮球教学中的初探
- 思维导图在初中物理教学中的应用分析
- 小组合作学习模式在初中数学教学中的应用探究
- vacuumed
- vacuum flask
- vacuuming
- vacuums
- vacuum sweeper
- vacuum sweepers
- vacuum²
- vacuum¹
- vagaries
- vagina
- vaginae
- vaginal
- vaginally
- vaginas
- vagrant
- vagrantize
- vagrantly
- vagrantness
- vagrantnesses
- vagrants
- vague
- vagued
- vaguely
- vaguely remember
- vagueness
- 姑息放纵
- 姑息敌人,终至损害自己
- 姑息敌人,酿成祸患
- 姑息纵容
- 姑息纵容叛乱
- 姑息纵容敌人
- 姑息纵容盗寇
- 姑母
- 姑洗
- 姑溪居士前集
- 姑父
- 姑爷
- 姑爷进门,小鸡没魂
- 姑爹
- 姑祖母
- 姑纵
- 姑绒
- 姑老
- 姑老爷
- 姑舅
- 姑舅亲
- 姑舅亲,辈辈亲,打断骨头连着筋
- 姑苏
- 姑获鸟
- 姑表