杨欢 王新房

摘要:为解决传统协同过滤推荐算法数据稀疏、可扩展性差等问题,采用改进预测评分矩阵的协同过滤算法。首先使用基于线性回归分析的加权Slope One算法,在传统Slope One算法中加入可信度,提高共同评分基数;然后采用网上标准数据集movielens作为测试数据,结合协同过滤算法进行top-N推荐。实验结果表明,使用改进预测评分矩阵的协同过滤算法的MEA较小,在近邻数大于25时达到0.74,表明该算法改善了传统协同过滤算法数据稀疏、扩展性差问题,降低了推荐误差,提高了推荐系统准确度。
关键词:协同过滤;线性回归分析;SlopeOne算法;top-N推荐
DOI:10.11907/rjdk.191026开放科学(资源服务)标识码(OSID):
中图分类号:TP312文献标识码:A 文章编号:1672-7800(2019)010-0090-04
0引言
随着Web2.0时代的到来,海量信息涌现在互联网上,消费者与商家都希望从大量数据中找到有用信息。推荐系统应运而生,它根据用户历史数据信息构建用户兴趣模型,从而向用户推荐有用信息。近年来随着各大网站的建立及APP的开发,推荐系统被广泛应用于电子商务、电影视频、音乐推荐等,亚马逊、Facebook、京东、淘宝等网站均有属于自己的个性化推荐系统。推荐算法的应用也显著提高了推荐系统准确性。
2005年Adomavicius等将主流推荐算法分为3个主要类别:基于内容的推荐、基于协同过滤的推荐和各种组合推荐方法,其中应用最广的是协同过滤推荐算法。该算法又可分为基于用户的协同过滤(UBCF)和基于项目的协同过滤(IBCF)。这两种算法的主要特征是近邻推荐,根据目标用户最近邻购买的商品预测其即将购买的商品。但是随着时间的推移,商品和用户数量不断扩大,且很少用户会对每个商品进行评价,这就导致了近邻推荐构成的评分矩阵不是很完整,而且会越来越稀疏,最终导致推荐质量变差,可扩展性下降。
近些年也有很多研究聚焦于该问题。文献[5]提出了基于高维稀疏数据聚类的协同过滤推荐算法,首先通过聚类处理原有高维稀疏数据,再利用稀疏差异度和集合差异度量公式,在用户一项目评分矩阵上进行聚类,然后利用协同过滤算法推荐聚类后的矩阵,提高算法推荐精度;文献[6]利用深度学习算法获取神经网络训练商品的评分,降低数据稀疏性,提高了算法推荐质量;文献[7]把奇异值分解融合到基于项目的协同过滤中,降低用户项目矩阵维度,有效缓解了数据稀疏的问题;文献[8]提出一种有关用户社交信任关系的改进协同过滤算法,通过用户关系社交填充评分数据,从而提高协同过滤的推荐性能。
针对传统推荐算法中数據稀疏、扩展性差等问题,本文提出一种改进预测评分矩阵的协同过滤算法。首先在传统基于线性回归分析的Slope One算法基础上提出加权Slope One算法,考虑到可信度的问题,以共同评价过项目的用户数作为项目评分加权值,通过加权SlopeOne算法填充稀疏用户项目评分矩阵,然后结合协同过滤进行top-N推荐。
1协同过滤算法
1.1相似度计算
相似度可衡量事物的相近程度,在本文算法中指两个用户对同一个项目的喜好程度(用户相似度)或两个项目被同一个用户喜好的相似程度(项目相似度)。协同过滤推荐算法通常使用的相似度有3种:
(1)余弦相似性。两个用户间相似程度可通过余弦夹角获得,相似度越小,夹角越大;相似度越大,夹角越小。
1.2协同过滤算法原理
2Slope One算法
2.1传统基于线性回归模型的Slope One算法
2.2加权Slope One算法
传统Slope One算法仅根据式(7)求取待推荐用户的历史评分,以此推算出该用户对项目j的评分,由于项目偏差没有考虑到不参予的用户基数,因此用户可信度不同。对于预测评分的项目,共同评分基数越大,则可信度越高。假设m个用户同时评价项目j和k,而n个用户同时评价项目j和l,当m>n时,前者置信度大于后者。
在表1的项目一评分矩阵中,“一”代表用户2对项目1的评分未知或者没有评分,用户3对项目3的评分为需要预测的目标用户的评分,计算项目1与项目2的偏差为((2-1)+(4-2))/2=0.5,由该偏差计算出用户2对项目1的评分为3+0.5=3.5,项目1与项目3的偏差为2-4=-2,则用户2对项目1的评分为-2+5=3,由此计算出用户2对项目1的评分为(3.5+3)/2=3.25,同理可求得用户3对项目3的预测评分为2.19。由上可知项目1与项目2都评价的用户数为2,因此权重为2;项目1和项目3都评价的用户数为1,因此权重为1。
3基于最近邻的Sloope One智能推荐算法
一般对推荐算法的要求包括:容易实现、便于维护,对新的评分要立即响应、查询速度快,对新的用户也要能给出有用的推荐,精度上要有竞争力。
协同过滤推荐算法在研究之初迅速成为信息推荐中一项很受欢迎的技术,特别是IBCF,被广泛应用于各大网站。但随着内容复杂性不断增加及用户人数不断增多,协同过滤算法的一些缺点逐渐显露出来,主要有数据稀疏性、扩展性差、精确性不高等。
传统Slope One算法的优点是实现简单且易于维护、响应即时,并且用户新增评分对推荐数据的改变较小,因为在内存中储存的是物品间的平均差值,新增差值只需进行累加,且范围只是用户评分过的产品,在一定程度上算法的准确率也很高。基于以上两种算法的优缺点,本文提出一种新的基于最近邻的Slope One智能推荐算法。
3.1项目一评分矩阵构成
4实验结果与分析
基于用户的协同过滤对测试集中458个用户分别进行预测评分实验,采用3种不同的相似度计算方法,最近邻居数范围是5~60,得到的平均MAE结果如图1所示。从中可知,采用不同相似度量对预测精度有一定影响,其中相关相似性精度最差,余弦相似度次之,精度最高的是修正的余弦相似度,所以本次实验采用修正的余弦相似度。
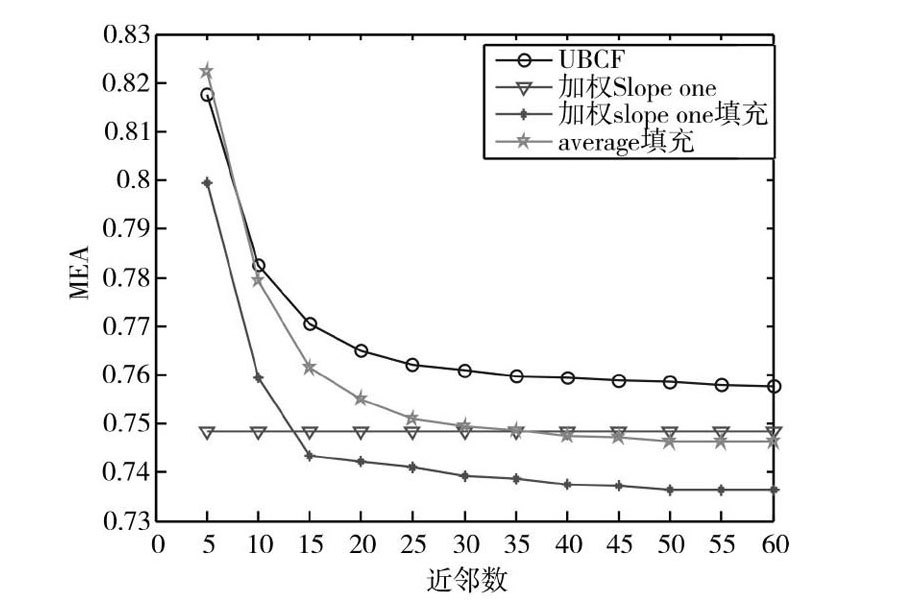
4种算法对比如图5所示。从图5可以看出,UBCF的MAE值会随着近邻数的增加而减小,但是当近邻数增加到35后,算法的MEA值趋于平稳,不会发生巨大波动。而传统Slope One算法的MEA值几乎不波动,但相对于前两种算法精度有所提高。而经由均值填充的算法在近邻数小于10时算法的MEA值高于UBCF,虽然后期算法的MEA值明显降低,但是相对于本文算法仍然较高。本文算法以加权Slope One算法填充UBCF评分矩阵为例,精度一直高于UBCF,虽然当近邻数小于13时精度小于Slope One算法,但是后期算法精度明显提高。
5结语
本文将加权Slope One推荐算法融入到传统协同过滤算法中,用线性回归分析填充稀疏的评分矩阵,解决了传统算法中数据稀疏、可扩展性不强等问题。实验结果表明,本文算法与传统协同过滤及Slope One算法相比,推荐精度更高,与平均值填充的协同过滤算法相比,精度也有所提高,更适用于推荐算法研究。
在推荐系统中,推荐算法的研究还需不断深入,可以加入用户关系模型和时间戳以及地理位置等因素,提取更多隐含特征使推荐更准确。
- 去除浮华 留下数学的“根”
- 正确分析:初中数学应用题解题教学的关键
- 浅谈数学教学中“认知冲突”的创设
- 活动教学:彰显学科本质与儿童立场
- 善于捕捉反馈信息,实施课堂有效教学
- 基于数学活动的初中数学概念类知识建构教学
- 好的“提问”成就精彩课堂
- 变“独裁”为课堂生成
- 探寻教学优化良计,例谈初中数学课堂教学
- 创新与传统并重,实效为教学之首
- 浅析新课标下的小学数学教学
- 主体性:初中数学学生解题错误讲评的焦点
- 引导有序思考 渗透数学思想
- 经历分层探索 积累活动经验
- 用交互式电子白板有机融合初中数学概念课
- 合作学习中常见问题的思考
- K—W—L策略指导下的初中数学教学
- “学生说题”,开辟“培优”新路
- 由基本图形入手巧解中考题
- 探究解方程(组)的检验问题
- 数学期望相同,游戏就一定公平吗?
- 动态世界?摇 亮点永恒
- 解决分式相关问题的十五种常用策略
- 一个折叠问题的再解
- 初中数学常见应用题解法例谈
- free agencies
- free agency
- freeagent
- free agent
- free-agentries
- free agentries
- free agentry
- free agents
- free-agents'
- free alongside ship
- freealongsideship
- free-and-clear
- freebee
- freebees
- freebie
- freebie, freebee
- freebies
- free carrier
- freecarrier
- freecashflow
- free cash flow
- freecollectivebargaining
- free collective bargaining
- free competition
- freecompetition
- r2014097200000565
- r2014097200000566
- r2014097200000567
- r2014097200000569
- r2014097200000570
- r2014097200000571
- r2014097200000572
- r2014097200000573
- r2014097200000574
- r2014097200000575
- r2014097200000576
- r2014097200000577
- r2014097200000578
- r2014097200000579
- r2014097200000580
- r2014097200000581
- r2014097200000582
- r2014097200000584
- r2014097200000586
- r2014097200000587
- r2014097200000588
- r2014097200000589
- r2014097200000590
- r2014097200000592
- r2014097200000593