李敬航 林泽宏 张鑫


摘要:随着我国科技、经济的快速发展,人们对电量的需求日益递增。当前,智能化体系不断完善,智能化的配网自动化系统将成为未来的主要研究方向。论文中主要解决自动配网系统中的配网参数设置问题。具体地,论文基于强化学习框架提出了一种配网参数优化的方法,该方法能够在尽可能少的人为干预下实现配网自动化,从而高效的解决传统配网问题。该智能体以最大化配网系统的供电质量为目标,利用配网系统正常供电的时长作为奖赏值,通过使用强化学习算法促使智能体不断学习,最终智能体能够为配网系统选择出一系列高质量的配网参数,从而实现高效、可靠的配网系统。
Abstract: With the rapid development of technology and economy, people's demand for electricity is increasing day by day. This paper mainly solves the problem of setting the distribution parameters in the automatic distribution system. Specifically, this paper proposes a distribution network parameter optimization method based on reinforcement learning framework, which can automate the distribution network with as little human intervention as possible, thereby efficiently solving the traditional distribution network problem. The agent aims to maximize the power supply quality of the distribution system, and uses the reinforcement learning algorithm to promote the agent to learn continuously, and finally the agent can select a series of high-quality distribution network parameters, thus achieving an efficient and reliable distribution network system.
關键词:智能化;配网自动化;强化学习
Key words: intelligent;automatic distribution network;reinforcement learning
中图分类号:O224? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文献标识码:A? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文章编号:1006-4311(2020)21-0226-05
0? 引言
在国家电网中,配网自动化技术是衡量现代电力技术的重要指标,该技术通过结合计算机科学技术、电气技术和网络技术来设置电网参数、动态监测电网状态以及实现电网的高可靠性。配网自动化有利于减少电网系统成本,同时也提高电网各个评价指标。配网自动化能够根据电网的实际运行情况,及时的进行电网调配,并能够有效的处理突发情况,保证电网的可靠性。
传统的配网自动化仍面临一些挑战,主要包括:①在自动化配网系统运行过程中,仍需大量的人为干预;②在自动化配网系统运行过程中,需要进行配网参数设置,这需要电力人员需要大量的经验积累;③对于不同的电力环境和地理环境,需要设计一个适合实际情况的电力拓扑网络[1]。为了解决上述问题,通过结合人工智能使得配网自动化系统更高效、更安全、更实用是有意义的,是当前智能电网的趋势,能够对配网系统甚至电网系统起到了十分重要的作用。在人工智能时代的背景下,有效的结合智能算法是提高配网自动化系统的一个可行的方案。
在本文中,我们通过使用强化学习中策略梯度方法对自动化配网系统中的参数进行优化,从而提高整个配网自动化系统以及整个电网系统的性能。以下将从相关工作、方法提出、未来展望和总结四部分进行详细描述。
1? 相关工作
1.1 配网自动化
先前已有配网自动化与机器学习的结合案例。针对配网系统的自动化检修问题,基于机器学习检修方法主要包含节点聚集环节、自适应连接环节和调试监测环节[2]。在进行自动检测的过程中,首先需要确定检测手段,并根据配网系统类型来确定聚类方式,然后对自动化配网设备进行自动连接及调试监测操作,从而根据实际情况实现自动化配网设备状态的自适应调试。在此基础上,我们需要完成这种新的调修方式的构造,首先需要匹配检修语义,并及时完善已生成的条目文件,最终完成搭建。在此之前,我国也有很多技术方法来研究配网设备自动检修方法,但是先前相关工作的主要关注点在于:基于配网设备通讯手段的检测分析,合理选择状态检修并形成最终汇总数据, 再利用重要性决策的方法理论,对汇总数据进行精准的风险控制与评价。该工作主要关注配网设备的检修和处理过程,虽然上述工作能够通过多次重要性指标加权的方式得到相对精准的调试和检修结果,但多次重要性指标加权的操作需要对数据进行集中处理的操作,也容易导致最终决策结果产生误差,从而容易诱发自动化配网设备在实际情况下得不到充分满足的问题。
1.2 强化学习
强化学习(Reinforcement Learning,RL)[3]是在解决决策问题方面具有很大的潜力,其通过构建智能体来代替人类进行决策,从而完成决策自动化。其基本原理是:为了代替人类进行决策,需要构建智能体(Agent);智能体会根据当前环境的状态进行决策,即输出动作(action);通过将动作作用于环境中,从而得到环境的反馈,即奖赏值(reward);通过最大化累积奖赏值来达到目标,并经过不断迭代从而学习到最优的策略(policy),该策略能够根据环境状态输出最大化奖赏值的动作(action)。通常地,当一个实际问题能够用强化学习方法解决时,我们往往可以将该过程模拟成一个马尔可夫决策过程,由一个四元组(S (state),A(action),P,R(reward))组成,其中:
①S(state)表示一个有限的状态集,其包括环境中可能出现的所有状态。St表示t时刻环境所处的状态;
②A(action)表示一个有限的动作集,其包括智能体根据环境状态可能采取的所有动作。At表示在t时刻智能体根据当前环境状态所采取的动作;
强化学习是一种策略学习方法,能够学习到从环境状态映射到动作的最优策略。强化学习与传统的机器学习方法有所不同,强化学习主要通过利用环境的反馈值进行迭代學习,该反馈值是对智能体所产生的动作的一种评价。如果智能体针对当前环境的状态做出的动作获得较高的奖赏值,那么以此计算的损失函数则会重点关注该动作区域,主要体现在梯度下降时的参数更新;相反,如果智能体做出的动作效果不够好,则降低对该动作区域的关注。通过上述的迭代学习方式,智能体不断改进行动策略从而找到适合当前环境的最优策略。
1.3 深度强化学习
随着深度学习的发展,深度学习中的神经网络的应用也越来越广泛。并且随着神经网络的种类越来越丰富,其对复杂任务的抽象能力也越来越强大。1.2节中所描述的强化学习虽然对决策问题具有很大潜力,但当问题的复杂度逐渐增加时,单纯的强化学习往往不能达到预期的效果。近期,谷歌大脑团队将具有抽象和表达能力的深度学习方法和具有决策能力的强化学习相结合,形成了深度强化学习方法[4],高效地突破了诸如自动驾驶、与人类进行围棋比赛等高难度复杂问题,并且利用该方法在一些领域的效果超越人类。通过这种方式,将深度学习中的神经网络与强化学习方法结合,这使得强化学习方法能够具有更加深层次的抽象能力,从而提高策略能力。具体的,强化学习中的智能体由深度神经网络构成,输入为当前时刻环境的状态,也就是当前时刻从环境中获得的感知信息,输出则为当前时刻智能体根据状态做出的决策或者动作。在智能体与环境交互的每一个时刻,利用神经网络构建的智能体能够获得复杂环境的潜在信息表征;接下来评估各种可能动作的价值函数,输出当前最优动作;环境对该动作做出反馈,输入到智能体。通过不断迭代训练,最终智能体能够以较高的概率选择奖赏值高的动作。该方法的优势在于,其不需要过多的人工干预,因此具有很好的实用性,并且也能大大减少资源耗费。目前,深度强化学习在对抗游戏、推荐和自动驾驶等新型领域得到广泛结合。
2? 基于深度强化学习的配网参数优化方法
在本章节中,我们将首先描述如何利用长短时记忆神经网络构造Agent以自动优化配网参数;接着描述智能体的工作流程和如何使用策略梯度算法训练智能体,并以最大化智能体选择的配网参数组合所对应的配网环境的正常运行时长作为目标。
2.1 Agent内部网络结构
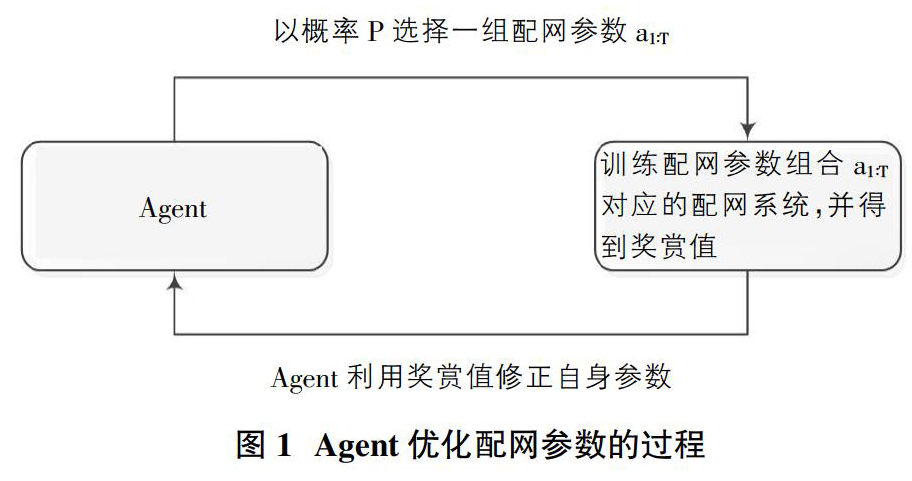
由于配网系统中的参数较多,如果直接优化整个参数空间,则会极大的降低整个配网系统的效率。在本文中,我们将自动化配网系统参数优化问题可看作一个序列决策问题,也就是将整个参数优化问题拆分成多个小的优化问题,每一时刻只针对某个配网参数的取值做出决策,整个配网系统的参数需按时间步逐个输出。为了考虑配网参数之间的相互关联和相互影响,我们使用一个变长的字符串来表示整个配网参数组合,通过这样的转变使得我们能够利用神经网络构造的智能体来生成对应的字符串,通过对字符串进行解析能够获得配网系统的实际参数值。由于LSTM网络对于解决时序问题具有很大的潜力,因此我们使用LSTM神经网络作为智能体的核心结构,具体优化过程如图1所示。Agent以概率P为算法模型选择一组配网参数a1:T(T为算法模型中需要优化的配网参数的总数);然后运行Agent选择的配网参数组合a1:T所对应的配网自动化系统,以该系统的正常运行时长作为奖赏值,利用策略梯度算法[5]来更新智能体的内部参数。通过这样的不断迭代,最终会得到一个较好的决策策略,主要体现在智能体会逐渐选择奖赏值较高的自动化配网参数组合。接下来我们以6个配网参数的配网系统为例,描述如何构建agent的模型结构。
对于配网系统中的配网参数,都会直接影响自动化配网系统的性能。我们利用长短时记忆神经网络(LSTM)[6]构造一个Agent来自动选择配网参数组合。该Agent的网络结构如图2所示,智能体按时间步展开6次,智能体的结构共享,整体显示一个流型结构。其内部结构包括一个输入全连接层、LSTM网络和一个输出全连接层。通过一个输入全连接层能够将输入统一维度且进行更深层次的特征提取。中间的LSTM网络作为智能体的核心结构,在一定程度上能够观察各个配网参数的内部联系。该核心结构由三层LSTM网络组成,每一层包含30个神经元节点。最后通过一个输出全连接层输出对应的配网参数值。
由于我们将参数选择看作一个序列决策过程,所以智能体在每一个时刻只输出对应的配网参数值。当完成所有时间步后,也就是选择完所有配网参数值后,Agent输出停止。Agent在t=1时刻的输入为全1向量(该向量的元素的值全为1),智能体在其他时刻输出对应配网参数的预选值的选择概率,该选择概率的值域为[0,1];智能体输出的动作的概率值越大,选中该动作预选值概率越高;否则相反。智能体通过不断迭代,能够根据输出的概率值进行最优的选择,即获得该配网参数的实际取值。同时,为了让所有的待优化的配网参数保持前后联系,我们把当前时刻所选择值的索引位置作为下一时刻的状态,即下一时刻智能体的输入数据。
具体地,如在t=1时刻,Agent输出配网参数1的预选值的选择概率后,通过在概率中进行采样选择出配网参数1;然后,我们将智能体所选择的配网参数值的索引位置作为下一时刻智能体的输入数据;以此类推,智能体将按时间步迭代n次(n表示待优化的配网参数个数)。当智能体按上述步骤选择了所有配网参数后,就形成了一个自动化配网系统参数组合。重要的,我们以自动化配网系统的运行质量作为优化目标,所以将配网系统正常运行的时长作为智能体的在当前时刻的奖赏值,并以此计算损失函数。通过使用梯度下降来更新智能体的内部参数。经过多次迭代,Agent通过奖赏值修正自身权重,Agent能够选择出更优的配网参数组合,使得不断提升配网系统的正常运行时长。值得注意的是,虽然Agent输入的配网参数是串行关系,但是配网参数输入顺序不会影响到最终实验结果。这是由于LSTM网络结构内部能够逐渐适应配网参数顺序不一带来的影响,并且强化学习算法也能够在参数空间充分采样,渐弱参数依赖性对最终结果的影响。
2.2 Agent工作流程
在本节中,我们将具体描述Agent智能体如何进行自动化配网系统的参数优化,主要分为以下4个步骤:
①通过输入层将状态输入到智能体,并通过Agent智能体中的全连接层,对智能体的输入进行低层次的抽象处理并统一其维度,其重要运算為:
其中,softmax函数中的exp(x)表示对x进行指数操作;N表示x中总共包含的元素值个数,即待优化的配网参数个数;Pt表示自动化配网系统参数在t时刻的候选值的概率值,其大小为[0,1];inputt+1表示智能体在t+1时刻的输入信息;onehot(x)表示对x进行onehot编码,该函数的输出维度与x的维度相同,并且其输出只包含0和1,1的位置为x中最大元素的位置,其余维度的值为0。
通过以上步骤,Agent智能体能够按时间步来选择出整个配网参数组合。接下来,我们将选择强化学习方法,并使用该配网参数的正常运行时长作为奖赏值,以此来计算损失函数,最终通过梯度下降方法来更新智能体的内部参数。
2.3 Agent训练流程
策略梯度方法是一种基于策略的强化学习方法,相比于基于值的强化学习方法,策略梯度能够更加直接的获得动作决策策略。该方法通过计算动作的概率与期望总奖赏的乘积对智能体内部参数的梯度来更新智能体的内部参数,通过不断迭代,智能体能够选择出一个较好的配网参数组合。策略梯度在解决强化学习任务时具有高效率、适应性强的优势。除此之外,它能够避免了值估计的过程,直接优化策略已到达较高的期望奖赏值。在实际使用时,在更多的领域使用策略梯度方法,并且它的最终效果也更加明显。因此,在本文中,我们采用策略梯度方法来计算损失函数,并以此来更新智能体的内部参数。
其中, T为自动化配网系统的待优化参数个数,也就是智能体所需展开的时间步数;Rk为自动化配网系统结合第k个样本,所得到的正常运行时长;b(baseline)表示基线,这里我们使用奖赏值的指数滑动平均值作为基线值。
3? 未来展望
在本文中,我们提出了一种基于强化学习的配网参数优化的方法。在该方法中,我们以自动配网系统的正常运行时长作为奖励值来更新agent的内部参数。在未来工作中,我们将继续深入研究该领域,主要改进方向有以下几点:①我们将组合自动化配网系统中的其他评估指标来作为奖励值,并进行多目标优化,从而达到综合性能更好的自动化配网系统;②在基础架构中,我们发现配网参数的评估十分耗时,我们将通过添加预测模型来进行性能预测,从而提高优化方法的时间效率;③我们将从配网参数的优化逐渐扩展到电网拓扑结构的优化,从而实现电网的全面优化。
4? 总结
本文中,我们针对自动化配网系统中配网参数优化的问题,将强化学习框架扩展到自动化配网系统的参数优化问题,并提出了一种新的自动化参数优化方法。该方法使用LSTM网络作为agent的核心网络结构,并以顺序选择的方式逐次选择出各个配网参数。在获得整个配网参数后,我们使用自动化配网系统的正常运行时长作为奖励值,并以此来更新agent的内部参数。经过不断迭代,智能体能够更加准确的选择出性能更好的配网参数组合,从而提高自动化配网系统的整体可靠性,使得优化方法在优化结果和优化效率上都具有一定的竞争力。
参考文献:
[1]盛德刚.基于配网自动化的电力系统研究[J].水利电力,2019,10.
[2]李互刚.基于机器学习的配网设备状态自动检修方法研究 [J].自动化与仪器仪表,2019,10.
[3]Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction [J]. The MIT Press.
[4]Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning [J]. Nature, 2015, 518(7540): 529-533.
[5]Williams R J. Simple statistical gradient-following algorithms for connectionist reinforcement learning [J]. Machine Learning, 1992, 8(3-4):229-256.
[6]Sepp Hochreiter and Jurgen Schmidhuber. Long Short-Term Memory [J]. Neural Computation, 1997, 9(8):1735-1780.
[7]Kingma D P and Ba J. Adam: A Method for Stochastic Optimization [J]. Computer Science, 2014.
- Box—Behnken设计—效应面法优选蒲黄干法制粒工艺
- 糖网明目颗粒喷雾制粒工艺参数优选及其颗粒性状研究
- 大孔吸附树脂分离纯化辣蓼总黄酮研究
- 基于指纹图谱与一测多评技术分析化学转化法富集甘草药渣总黄酮的研究
- 响应面法优选银槐解毒颗粒提取工艺
- 从龙牙楤木药材乙醇提取物中水解楤木皂苷工艺优选
- 不同灸量隔姜灸对脾虚证大鼠胃组织丝裂原细胞外激酶和细胞外调节蛋白激酶表达的影响
- 慈菇消脂丸对非酒精性脂肪性肝炎大鼠脂毒性及氧化应激的影响
- 不同中医证型高血压患者血压变异性及影响因素分析
- 不同中医证型原发性失眠患者肠道菌群差异研究
- 地龙降压胶囊联合西医常规治疗肝阳上亢型原发性高血压伴亚临床动脉硬化临床研究
- 基于肺与大肠相表里的肺病患者肠道便菌群特点研究
- 中药材有效部位总黄酮含量测定方法研究概述
- 雷公藤制剂生殖毒性及联用减毒研究进展
- 中药材种子种苗质量分级标准研究进展
- 补中益气汤加栀子治疗急性化脓性中耳炎1例
- 半夏泻心汤治疗嗜酸细胞性胃肠炎体会
- 魏子孝善用药对治病经验探析
- 结合圆运动理论浅谈IgA肾病辨治
- 从“分期分段分层”原则论针刀治疗臀上皮神经卡压综合征
- 中西药联合应用评价实践探索
- 基于MOOC的翻转课堂教学模式在推拿手法学课程教学改革中的应用
- 中医经典文献中的医案因子传承与源流辨证新论
- 我国居民中药材砷暴露风险评估
- 从雾霾与重症急性呼吸综合征致病特点推测温霾发病条件及其特征
- expensiveness
- expensivenesses
- experience
- experienceable
- experiencecurve
- experience curve
- experienced
- experienced/not experienced
- experienceeconomy
- experience eˌconomy
- experiencer
- experiences
- experience²
- experience¹
- experiencing
- experiment
- experimental
- experimentally
- experimentals
- experimentarian
- experimentation
- experimentations
- experimentator
- experimentators
- experimented
- 酒力
- 酒功
- 酒务
- 酒助懦夫怒气,钱添笨汉精神
- 酒劲
- 酒势
- 酒半
- 酒博士
- 酒卮
- 酒友
- 酒可擒贼
- 酒合万事,酒和性情
- 酒名
- 酒后兴奋
- 酒后吐真言
- 酒后困疲如生病一样
- 酒后失态
- 酒后失言
- 酒后失言,君子不怪
- 酒后态度狂放
- 酒后无德
- 酒后犯的过失
- 酒后狂言醒时悔
- 酒后的容颜
- 酒后的快意