摘要:近年来,随着互联网广泛作为人们交流和表达的工具,文本情感计算成为了热点研究方向。本文针对文本情感计算相关研究进行综述。归纳不同领域的诸多学者对于情感类型的划分;介绍文本情感识别中三个主要问题的研究情况:文本情感特征标注、情感特征提取算法和文本情感分类技术。未来的研究可关注以下几点:建立统一的实验语料和词典;情感特征提取方面研究;语义成分的理解和识别。
关键词:文本情感计算 情感识别 特征提取 情感分类
中图分类号:TP391.1 文献标识码:A
情感计算为改善人机交互环境提出了新的想法和实现手段。作为一个新兴的交叉学科,情感计算引起了众多学术团体和企业机构的兴趣,在国际期刊和会议上出现了不少有关情感计算的研究成果,主流的研究对象包括表情情感、语音情感、行为情感和文本情感等。由于面部、语音和行为的信息量丰富,相应的情感识别技术的发展相对较为成熟。文本情感计算属于计算机语言学的研究范畴,在互联网的发展的推动下,Web文本逐渐成为情感信息的载体,文本情感计算体现出重要的研究价值,本文将重点放在对文本进行情感计算的有关研究,以期对今后的研究有所借鉴。
1.文本情感计算过程
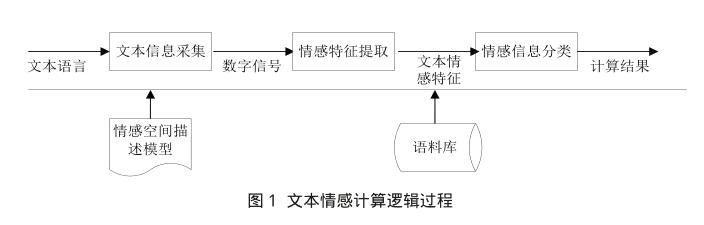
文本情感计算的过程可以由3部分组成:文本信息采集、情感特征提取和情感信息分类,如图1所示。文本信息采集模块通过文本抓取工具(如网页爬虫工具)获得情感评论文本,并传递到下一个情感特征提取模块,然后对文本中自然语言文本转化成计算机能够识别和处理的形式,并通过情感信息分类模块得到计算结果。
文本情感计算主要研究情感状态与文本信息之间的对应关系,提供人类情感状态的线索。具体地,需要找到计算机能提取出来的特征,并采用能用于情感分类的模型。因此,关于文本情感识别的讨论,主要集中在文本情感特征标注、情感特征提取算法和情感信息分类这三个方面,本文将主要对这三个方面的研究详细综述。
1.1文本情感特征标注
情感特征标注是对情感语义特征进行标注,通常是将词或者语义块作为特征项。情感特征标注首先对情感语义特征的属性进行设计,如褒义词、贬义词、加强语气、一般语气、悲伤、高兴等等;然后通过机器自动标注或者人工标注的方法对情感语义特征进行标注,形成情感特征集合。情感词典是典型的情感特征集合,也是情感计算的基础。在大多数研究中,有关情感计算研究通常是将情感词典直接引入自定义词典中。
针对不同的语言文字,情感词典有所不同。例如哈佛大学编录的G(IGeneral Inquirer)词典,主要对每个英文词汇的词性、属性和强度进行了相应的标注,在英文的情感分析中广泛使用[1]。Hu整理汇编的情感词典Opinion Lexicon,也是很多研究人员选用的基础资源[2]。针对汉语文字,最常用的是知网发布的词典《How Net》[3],该词典既包括中文也包括英文。柳位平等人结合种子词,在《How Net》基础上形成了中文基础情感词词典[4]。还包括:张伟、刘缙等人的《学生褒贬义词典》[5];杨玲,朱英贵的《贬义词词典》[6];史继林、朱英贵的《褒义词词典》[7]等等。虽然中文的情感分析研究起步较晚,但是在情感词典的构建方面的研究发展迅速,不少研究人员在建立情感词汇本体库时,并不局限于使用单一情感词典。例如,王素格等人集成5个情感词典的基础上建立情感词表SWT,据此进行情感类别判断[8]。吴江等以《知网》《台湾大学情感词典》和《学生褒贬词典》合并去重后形成基础词典,分析web上的金融文本[9]。
运用情感词典计算出文本情感值是一种简单迅速的方法,但准确率有待提高。在实际的情感计算中,会因为具体的语言应用环境而有所不同。例如,“輕薄”一词通常认为是否定词,但是在电脑、手机却被视为肯定词汇。同时,文本中常会出现否定前置、双重否定以及文本口语化和表情使用等,这些都将会对文本情感特征的提取和判断产生较大的影响。因此在进行文本情感提取时,需要对文本及其对应的上下文关系、环境关系等进行分析[10]。
1.2情感特征提取算法
文本包含的情感信息是错综复杂的,在赋予计算机以识别文本情感能力的研究中,从文本信号中抽取特征模式至关重要。在对文本预处理后,然后对初始提取情感语义特征项。特征提取的基本思想便是根据得到的文本数据,决定哪些特征能够给出最好的情感辨识。通常算法是对已有的特征词情绪打分,接着以得分高低为序,超过一定阈值的特征组成特征子集。
不少研究人员提出一些文本特征提取算法,例如文档频率法、期望交叉熵、互信息以及卡方统计量等。归纳总结现有的文本特征提取算法,整理得到表2。
在文本分析理论研究不断发展的趋势下,不同的特征提取算法都得到了很大的改进。由于特征提取算法较大程度上依赖训练集和分类算法,因此不同的研究人员在不同的应用领域对各特征提取算法的评价结果也有差异。黄萱菁认为交叉信息熵的效果比不上互信息和卡方统计量[11],而单丽莉通过比较认为交叉信息熵的效果最好[12]。李纲证明出局部文本特征选择时,互信息和卡方统计的性能比优势比的性能好[13]。可见,特征算法的优劣性并没有统一结论。针对不同的应用领域的需求,应根据具体的训练集过程和分类算法选择合适的特征选择算法。
特征词集的质量直接影响最后结果,为了提高计算的准确性,文本的特征提取算法研究将继续受到关注。长远看来,自动生成文本特征技术将进一步提高,特征提取的研究重点也更多的从对词频的特征分析转移到文本结构和情感词上。
1.3文本情感分类技术
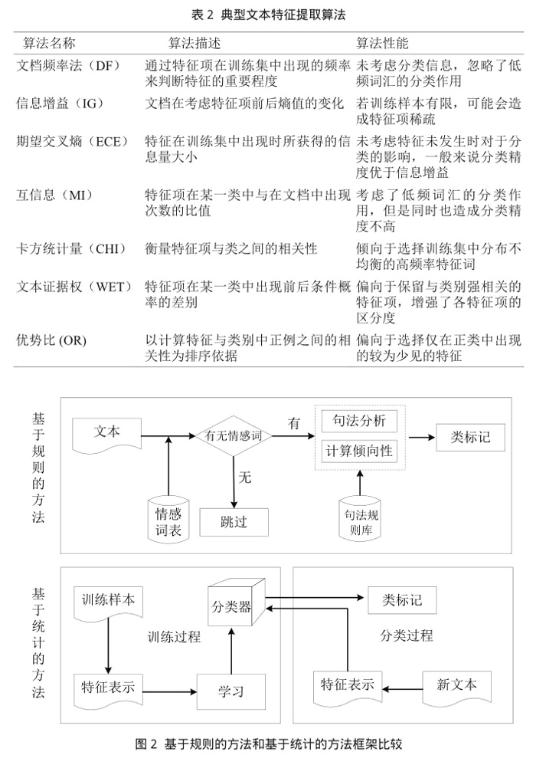
文本情感分类技术中,主要采用两种技术路线:基于规则的方法和基于统计的方法。在20世纪80年代,基于规则的方法占据主流位置,通过语言学家的语言经验和知识获取句法规则,以此作为文本分类依据。但是,获取规则的过程复杂且成本巨大,也对系统的性能有负面影响,且很难找到有效的途径来提高开发规则的效率。
20世纪90年代之后,人们更倾向于使用统计的方法,通过训练样本进行特征选择和参数训练,根据选择的特征对待分类的输入样本进行形式化,然后输入到分类器进行类别判定,最终得到输入样本的类别。基于规则的方法和基于统计的方法框架比较如图2所示。
2.基于规则和统计的方法
2.1 基于规则的方法
Qiu等人提出一种领域无关的双向传播算法,根据依存模式由种子情感词抽取属性词,这些属性词又可以反过来发现新的情感词[14]。Pang采用新的思路,提出了对文本进行重新划分的方法,根据相邻句子之间的关系,结合词语的统计信息,先进行主观句与非主观句的区分,并对区分后的句子进行分析获得文本的极性[15]。语法规则的获取和优先级的确定是研究基于规则的句法分析方法时所面临的主要问题。随着语料库技术的发展,近年来,短语识别和句法分析过程中偏向使用基于统计的方法。传统方法对语言规则的获取需要以语言学家的总结为线索,基于语法规则的方法则更倾向于自动从语料库中自动获取语法规则,许多利用句法结构分析句子的方法也在相继革新。
2.2 基于统计的方法
Pang使用朴素贝叶斯模型、最大摘模型、支持向量机等分类模型挖掘文本中的情感倾向性,实验表明支持向量机的分类效果最好,准确率达80%[16]。Hatzivassiloglou采用机器学习的方法来计算形容词之间的关系强度实现对形容词的情感倾向进行预测[17]。迄今为止,采用机器学习方法进行情感分类的研究成果有很多,采用此方法的关键在于特征选择算法和语料库的完善程度。目前,基于统计的文本情感分类方法更受重视,因为这种方法有如下优点:其信息唯一来源语料库,全部知识(除了统计模型的构造)均来自于语料库;运用统计的概念去解释语言,一切从语料库中得到的参量都需要经过统计方法的运算。
3.总结与展望
文本情感計算是自然语言处理的一个研究分支,其工作展开的关键在于情感特征提取和情感分类方法的不断进步优化。尽管经过了大量研究,文本情感计算取得了很大的进展,但整体仍处于探索阶段,存在一些亟待解决和研究的问题。
3.1 缺乏统一的实验语料和词典
文本情感计算离不开情感词典、测试语料库等基础资源。但是,各研究人员都在各自构建的词典和实验预料上进行的,没有统一的规范,因此研究结果的对比常常无法进行。而且,为解决不同领域的情感分析工作,这些资源是远远不够。中文公开的语料库较少,大多还处于建设中。因此,研发开放统一的语言工具和实验平台是接下来重要工作。
3.2 情感特征提取需进一步深入分析
文本情感信息相对于语音信息和图像信息而言是相对匮乏的,因此在文本中找到与情感相关的特征参数较困难。加入新的特征参数,采取更有效的特征提取算法势必会提高识别效率。如何围绕文本资源进行情感特征提取工作是关键问题,也是需要继续研究的课题。
3.3 加强语义成分的理解和识别
文本情感计算本质上是自然语言处理研究的一个分支,单从词汇的含义来判别其褒贬义等情感属性并不充分。目前针对语言规律和句子语义成分的分析问题,还没有成熟的解决方案。因此,进一步的研究,一方面是加强语义与情感之间的联系,另一方面是充分利用自然语言处理技术和语言学知识,提高情感语境分析研究,更高层次地掌握文本的情感信息。
参考文献:
[1] Stone P J. T he general inquirer : a computer approach to content analysis[M]. M.I.T. Press, 1966.
[2] Hu M, Liu B. Mining and summarizing customer reviews[C]. T enth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, Washington, Usa, August. 2004:168- 177.
[3] 董振东,董强,郝长伶.知网的理论发现[J].中文信息学报, 2007,21(4):3- 9.
[4] 柳位平,朱艳辉,栗春亮等.中文基础情感词词典构建方法研究[J].计算机应用,2009,(10):2875-2877.
[5] 张伟,刘缙,郭先珍.学生褒贬义词典[M].北京:中国大百科全书出版社,2004.
[6] 杨玲,英贵.贬义词词典[M].成都:四川辞书出版社,2006.
[7] 史继林,朱英贵.褒义词词典[M].成都:四川辞书出版社,2005.
[8] 王素格,杨安娜,李德玉.基于汉语情感词表的句子情感倾向分类研究[J].计算机工程与应用,2009,45(24):153- 155.
[9] 吴江,唐常杰,李太勇.基于语义规则的Web金融文本情感分析[J].计算机应用, 2014, 34(2):481- 485.
[10] 黄萱菁,张奇,吴苑斌.文本情感倾向分析[J].中文信息学报,2011,(06):118- 126.
[11] 单丽莉,刘秉权,孙承杰.文本分类中特征选择方法的比较与改进[J].哈尔滨工业大学学报,2011,(s1):319- 324.
[12] 李纲,夏晨曦,郑重.局部文本特征选取算法的比较和改进研究[J].情报学报, 2008,27(4):506- 511.
[13] 杜嘉忠,徐健,刘颖.网络商品评论的特征–情感词本体构建与情感分析方法研究[J]. 现代图书情报技术,2014,30(5):74- 82.
[14] Qiu G, Liu B, Bu J, et al. Opinion W ord E xpansion and T arget E xtraction through D ouble Propagation. C omputational Linguistics[J]. C omputational Linguistics,2010,37(1):9- 27.
[15] Pang B, Lee L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts[C]. Association for Computational Linguistics,2004.
[16] Pang B, Lee L, Vaithyanathan S. Thumbs up? Sentiment Classification using Machine Learning Techniques[J]. Proceedings of Emnlp,2002:79- 86.
[17] Hatzivassiloglou V, Mckeown K R . Predicting the semantic orientation of adjectives[C]. 1997.
- 基于微课的小学美术教学模式新探
- 翻转课堂在小学美术中的实践探究
- 古典诗词歌曲进入小学音乐课堂的教学策略研究核心探究
- 多媒体在农村小学数学教学中的运用探析
- 春城无处不飞花
- 激发体育兴趣 提高体育素质
- 教育戏剧
- 让“美”尽情于儿童诗阅读
- 挖掘体育资源,促进学生身心健康发展
- 遵循指南构建具有农村特色的美术课堂
- 小学体育教学中拓展训练的应用研究
- 挖掘自然素材 丰富美术课堂
- 小学音乐健康教育、健康课堂
- 游戏教学法在小学体育课堂的运用和分析
- 音乐游戏在小学音乐教学中的应用分析
- 依循学生特点,实施分层教学
- 理性凝视
- 核心素养下小学英语高效课堂的构建研究
- 小学英语绘本阅读教学策略的研究
- 例谈思维导向下的小学英语“深度阅读”的教学策略
- 如何在小学英语教学中运用故事教学法
- 互联网背景下英语阅读教学之谈
- 农村低年级学生口语交际能力的培养
- 基于素质教育背景探究创新小学语文课堂教学
- 预习
- stethoscopes
- stethoscopies
- stethoscopists
- stevedore
- stew
- stewable
- steward
- stewarded
- stewardess
- stewardesses
- stewarding
- stewardly
- stewards
- stewardship
- stewing
- stews
- stewy
- stew²
- stew¹
- sth could go either way
- sth does not come cheap
- sth ends in tears
- sth goes for
- sth is not all it's cracked up to be
- sth takes the cake
- 衣钵相传
- 衣钵相承
- 衣锦
- 衣锦之荣
- 衣锦乘肥
- 衣锦回
- 衣锦回乡
- 衣锦夜游衣绣夜行
- 衣锦夜行
- 衣锦归
- 衣锦归田
- 衣锦故乡
- 衣锦昼游
- 衣锦昼行
- 衣锦白日
- 衣锦肉食
- 衣锦荣归
- 衣锦荣旋
- 衣锦褧衣
- 衣锦过乡
- 衣锦还
- 衣锦还乡
- 衣锦还乡衣锦归乡
- 衣锦食肉
- 衣靠腋下的接缝部分