赵素芬

摘? 要: 链路预测是社交网络研究中最核心、最本质的研究问题。文章基于学术合作关系社交网络,采用多种现有的经典机器学习算法进行链路预测。针对现有监督学习算法中特征集使用不够全面的问题,抽取了三大类别的特征。针对数据高度偏斜问题,采用了欠采样的方式使模型不对主要类别过度偏斜,以此保证分类器的有效性。实验结果表明,Adaboost和多层前馈神经网络模型在精确率、召回率以及F1-measure指标上优于其他监督学习方法,而朴素贝叶斯方法在本问题上表现最差。
关键词: 社交网络; 链路预测; 机器学习; 监督学习; 数据偏斜
中图分类号:TP311? ? ? ? ? 文獻标志码:A? ? ?文章编号:1006-8228(2019)01-39-04
Abstract: Link prediction is the core and essential research issue in social networks research. Based on the academic co-authorship networks, eight existing classical machine learning algorithms are used for link prediction. Three categories of features are extracted for link prediction to solve the problem that the features don't be used comprehensively in the existing supervised learning algorithms. And the under-sampling is used for the problem of high skewness of data, to overcome the model skewness and to ensure the validity of the classifiers. Experimental results show that Adaboost and Multi-Layer Perceptron model are superior to the other six models in Precision, Recall and F1-measure. However, Naive Bayesian performs the worst.
Key words: social networks; link prediction; machine learning; supervised learning; data skewness
0 引言
链路预测是图挖掘的核心,因其能够揭示社交网络演化的本质,故具有十分重要的研究意义。本文基于学术合作关系网络进行链路预测。学术合作网络即学者基于互相合作发表学术论文而构建的合作关系网。这种合作关系可以很方便地从在线的文献发表数据集中抽取,例如dblp, ACM, Google Scholar等等。我们的研究问题是,基于现有的合作关系网络,预测将来很可能出现的合作关系。对该问题的深入研究,能够为揭示学者之间的研究合作模式、了解合作关系建立的本质,以及为学者推荐最有潜在合作价值的合作关系提供良好的基础。
针对链路预测问题,现有的研究方法主要分为两个大的类别。①无监督的方式[1,2,12]。这种方式,主要针对社交网络的拓扑结构抽取特征,这些无监督的指标能够体现出网络中的两个节点建立关系的潜在可能性。绝大多数无监督指标的计算方式比较简单,其计算复杂度都很低。但是,无监督指标适合排序,如果进行链路预测就需要指定一个分类的阈值。这种情况下,链路预测的指标阈值如何设定,这是一个很难把握的部分。并且,这种情形下很难综合考虑多个不同的预测指标。②监督学习的方式[3,4,6,8,11]。随着机器学习技术的快速发展,一些研究者选择使用监督学习技术进行链路的预测[3-4]。监督学习方式能够根据抽取的显式特征或者隐式特征自动学习出分类模型,比较好地克服无监督指标的一些缺陷。但是,目前针对学术社交网络的链路预测中,其使用的特征均十分有限,这制约了链路预测的效果。
因此,为了克服现有的监督学习模型中的问题,本文中,我们基于学术社交网络,抽取了三大类别的特征,包括网络拓扑结构相关特征(节点之间的最短图距离、共同邻居的个数、Jaccard系数、偏好依附值、AA指标、重启随机游走分数等[1-2])、以及学者的研究兴趣相似度特征(标题文本相似度)、以及学者的学术地位因素(作者发表论文数之和)等八个特征。
为了克服数据集的偏斜性,本文中采用欠采样的方式对负样本进行采样,以保证正负样本的大致均衡,避免训练出对主要类别过度倾斜的分类器。然后,我们选择了八种现有的经典机器学习算法,来进行链路的预测。实验结果表明,Adaboost和多层前馈神经网络,在众多的监督学习方法中性能表现最优,而朴素贝叶斯在本问题中的表现最差。
总的来说,本文的研究有如下方面:
⑴ 本文对比了八个不同的机器学习算法在链路预测问题上的不同的性能,这对于进一步设计更高效的预测模型和合作关系推荐模型具有启发式的意义。
⑵ 与现有的方法相比,我们的模型使用了一些其他研究中没有使用的特征,例如作者发表论文的标题相似度以及发表论文数之和。
⑶ 本文使用欠采样的方式,来克服数据集高度偏斜的问题。
1 研究问题描述
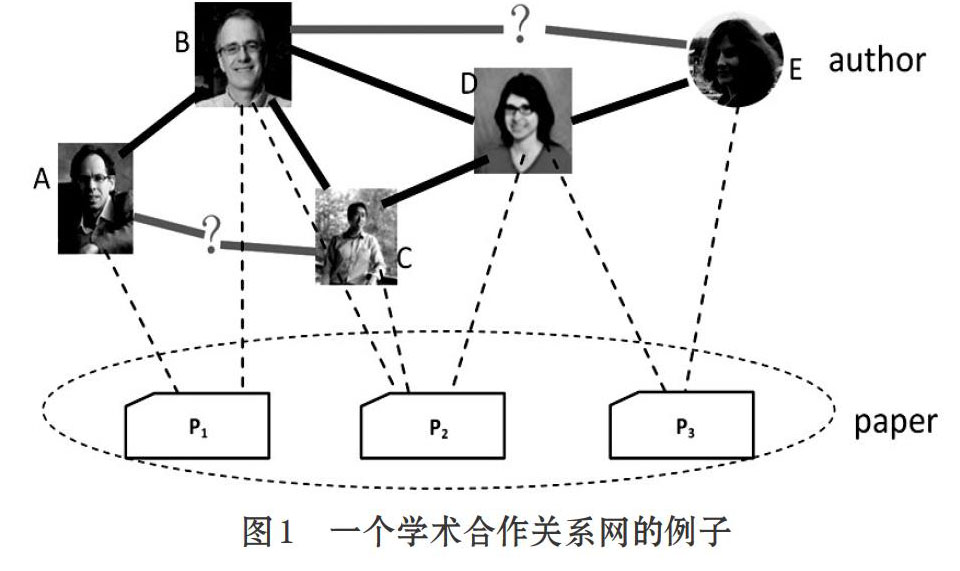
基于文献发表数据集,我们可以从中抽取合作关系网络。我们首先把学者抽象为网络中的节点,如果两个学者u,v之间至少合作了一篇论文,那么这两个学者的节点之间便存在一条边(u,v)∈E。通过这样的方式,我们可以抽取出整个合作关系网络G=(V,E)。图1给出了一个例子。作者A,B,C,D,E经由共同发表了三篇学术论文p1,p2和p3,建立了如图1粗实线所示的学术合作关系。
定义1 学术社交网络中的链路预测:给定t时刻的学术合作关系网络图G,针对G中没有建立链路关系的任意一对节点i和j,预测在t+Δt时刻,节点i和节点j之间是否会建立连接[2,10]。
2 链路预测模型
2.1 链路预测框架概览
针对定义1中的链路预测问题,我们选择了8种机器学习模型进行链路预测,包括:K近邻(KNN)、logistic回归(LR)、决策树(DT)、支持向量机(SVM)、朴素贝叶斯(NB)、多层前馈神经网络(MLP)以及集成学习算法随机森林(RF)、Adaboost等。
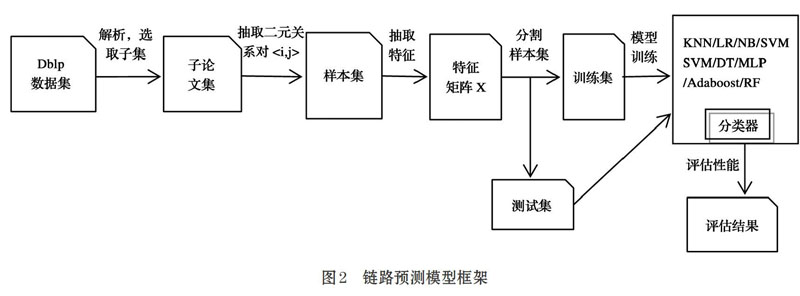
图2中给出了我们的预测模型的框架。从图2中可以看出,預测模型的构建分为几个主要的步骤:数据集的解析和预处理-->生成训练样本集-->特征提取-->模型训练-->模型评估。在2.2节中将详细介绍每一个步骤。
2.2 链路预测
2.2.1 数据集的解析和预处理
本文中使用的文献发表数据集是Dblp数据集( 2018-01版本),其中包含了2104606篇会议论文和1758872篇期刊论文,论文发表的时间范围是从1969~2018。
在对Dblp的原始XML数据集进行解析之后,我们对论文数据进行了预处理操作。首先去除了1990年以前发表的论文数据,然后在剩下的论文中选取了机器学习和数据挖掘领域相关的22个会议和23个期刊的论文作为子数据集(共计96174篇)。然后,将这些论文数据以2011年为分割点分成两个数据集:1990~2011年期间为训练阶段,2012~2018为测试阶段。接着,选择了在训练阶段和测试阶段发表论文的数目均不小于3(即3核)的全部作者,共计3609个作者。最终以这3609个作者的发表论文的数据集作为选取的子数据集。并以2011年作为分割点,构成最终的训练阶段论文集29877篇,测试阶段论文集22293篇。
2.2.2 生成训练样本集
生成了训练阶段的论文集和测试阶段的论文集之后,分别抽取出这两个阶段的合作关系邻接矩阵Gtrain和Gtest。接下来,依据这两个邻接矩阵的元素值,依次判断每两个作者i和作者j之间的关系,如果他们在t时刻前未建立关系,则将二元对<i,j>加入候选样本集。也就是说,我们仅仅对在训练阶段尚未建立关系的用户对进行建模。接下来,依据他们在测试阶段是否建立关系来确定这个二元对<i,j>的标记:如果测试阶段建立了关系,标记<i,j>为正样本(y=1);否则标记<i,j>为负样本(y=0)。
学术社交网络是极度稀疏的网络,数据的稀疏导致数据集的高度偏斜[7]。正负样本的极度不均衡性,会极大的影响分类模型的性能。因此,在我们构造训练集的步骤中,对负样本采用欠采样的方式,来保持正样本和负样本数目的大致均衡。具体来说,我们在生成了全部正样本之后,随机采样和正样本数目相同的负样本,以此作为整个模型的训练集合T。
2.2.3 特征提取
本文中,我们从数据集中抽取和使用了如下8个特征。其中,N(i)表示的是节点i的邻居节点;|N(i)|表示的是节点i的邻居节点的个数。
⑴ 最短图距离SP
最短图距离能反应两个用户互相认识的难度有多大,其值为从节点i到节点j的拓扑结构最短距离。
⑵ 共同邻居的个数CN
共同邻居的个数能反应两个作者建立潜在关系的渠道有多少,其计算公式为:。
⑶ Jaccard系数JC
Jaccard系数在信息检索领域,被大量应用于计算文本相似度,具有较好的效果。其计算公式是:。
⑷ 偏好依附PA
偏好依附指标的原理是:社交网络中,新关系的建立具有“马太效应”,即如果现有的节点具有更大的度,则新关系的建立的可能性更大,其计算公式是:。
⑸ Academic/Adar(AA)指标
AA指标仍然是一个拓扑结构相关的相似度指标[1-2],其计算公式是:。
⑹ RWR分数
重启随机游走的主要思想是:从源节点S出发,在网络中进行随机游走,每一步以α的概率回到S,以1-α的概率游走到其他节点。在经过有限步骤的随机游走之后,到达网络中每个节点的概率会达到稳定分布。这个平稳分布的概率值可以用来测量网络中每个节点和源端节点S的相似度。由于从节点i出发稳定在节点j的概率不等价于从j出发稳定在i的概率,我们计算了这两个概率的平均值来表示用户i和用户j的相似度分数。
⑺ 两个作者发表的论文之和TP
两个用户中至少有一个是精英学者,对于建立合作关系来说是一个极为有利的指征[5]。因此,我们将两个学者的发表论文的数目作为体现其研究地位的指标。
⑻ 用户的研究兴趣相似度TS
我们将两个用户的发表论文的标题取出,分词并去除停用词,然后计算标题文本的Jaccard相似度作为用户的研究兴趣相似度。
2.2.4 模型训练和评估
在全部的关系对抽取出来之后,我们依据2.2.3中定义的特征集,计算训练阶段中每个样本的特征向量,生成特征矩阵X。因为特征集的数据分布有很大的不一致,为了避免对各种机器学习算法的性能产生影响,我们将特征矩阵X进行了z-score标准化,即均值为0,方差为1。接下来,标准化之后的特征矩阵X和标记矩阵y输入到各种机器学习的模型中进行训练。
各个预测模型训练完之后,使用测试集验证每个模型的预测性能。实验中采用5折交叉验证。本文中,我们选择了三个最流行的分类性能评估指标:精确率(Precision)、召回率(Recall)以及F1-measure。
3 實验结果
从表1可以看出,在基本的机器学习模型中,多层感知机表现最好,而朴素贝叶斯方法表现最差。其他几种算法logistic回归、决策树和SVM性能性能大体一致。K近邻方法仅优于朴素贝叶斯。
这说明,由于朴素贝叶斯假定了特征之间的条件独立性,这在本问题中很难成立,因而影响了分类效果;而多层感知机神经网络由于隐藏层可以捕捉特征之间的非线性关系,并在较高层次进行抽象,所以能更好的拟合训练数据,训练出精确度更高的模型。在集成学习模型中,随机森林对于决策树算法基本没有提升,而Adaboost方法对决策树算法提升的效果很好,其预测性能超越了所有其他的基本分类器的预测效果。其原因是,我们的特征集的数目较小,而随机森林更适合处理高维数据;Adaboost则由于其组建强分类器的思路是根据弱分类器的反馈,自适应地调整样本权重和分类器权重,从而调整分类错误率,多数情况下都能有效的提升分类器的性能。
4 结束语
针对链路预测问题,我们基于学术合作网络,使用了8种经典的机器学习算法进行了合作关系的预测,并进行了预测性能的比较。
未来,将深入分析学术社交网络中链路形成的机制,考虑增加更多的特征,例如学者之间地理位置的距离特征以及隐式特征,并对分类特征的显著性进行探讨。除此以外,还将研究社交网络拓扑结构变化的时间序列信息[9],力求对链路关系的预测更加精确。
参考文献(References):
[1] David Liben-Nowell, Jon Kleinberg. The Link-Prediction Problem for Social Networks. Journal of the American Society for Information Science and Technology,2007.58(7):1019-1031
[2] Víctor Martínez, Fernando Berzal, and Juan-Carlos Cubero. A Survey of Link Prediction in Complex Networks. ACM Computing Surveys, 2016.49(4):69
[3] Gabriel P. Gimenses, Hugo Gualdron, etc. Supervised-Learning Link Recommendation in the DBLP co-authoring network. The Second IEEE International Workshop on Social and Community Intelligence,2014:563-568
[4] Nesserine Benchettara, Rushed Kanawati, etc. Asupervised Machine Learning Link Prediction Approach for Academic Collaboration Recommendation. Proceedings of the fourth ACM conference on Recommender systems(RecSys), 2010:253-256
[5] Yuxiao Dong, JieTang, Jilei Tian, Nitesh V.Chawla,?Jinghai Rao, HuanHuan Cao. Link prediction and Recommendation across heterogeneous social networks. IEEE International Conference on Data Mining,2012:181-190
[6] Salvatore Scellato, Anastasios Noulas, Cecilia Mascolo.Exploiting place features in link prediction on location-based social networks. International Conference on Knowledge Discovery and Data Mining,2011:1046-1054
[7] Ryan N. Lichtenwalter, Jake T. Lussier, Nitesh V. Chawla.New perspectives and methods in link prediction. International Conference on Knowledge Discovery and Data Mining,2010:243-252
[8] Kurt T.Miller, Thomas L. Griffiths, Michael I.Jordan.?Nonparametric latent feature models for link prediction. International Conference on Neural Information Processing Systems,2009:1276-1284
[9] Zan Huang, Dennis K.J.Lin. The Time-Series Link Prediction Problem with Applications in Communication Surveillance. INFORMS Journal on Computing,2009.21(2):286-303
[10] Behnaz Moradabadi, Mohammad Reza Meybody. Link?Prediction in weighted social networks using Learning automata. Engineering Applications of Artificial Intelligence,2018.70:16-24
[11] Yongli Li, Peng Luo, Zhi-ping Fan, Kun Chen, Jiaguo Liu. A utility-based link prediction method in social networks. European Journal of Operational Research,2017.260:693-705.
[12] Wang Peng, Xu BaoWen, Wu YuRong, Zhou Xiao Yu.?Link prediction in social networks: the state-of-the-art. Science China Information Science,2015.58(1):1-38
- 小学数学分层异步教学的实施策略苏教版
- 用游戏培养孩子的创造力
- 组织课外社团活动,体现社团活动魅力
- 浅析幼儿教学中如何培养学生的良好习惯
- 浅谈高三学生数学学习反思能力的培养
- 扬起生活的风帆
- 把握三三六模式精髓加快精准教研步伐
- 初中语文小组合作学习优化策略探讨
- 复数的运算技巧
- “等高线地形图的判读”中考备考策略
- 高中生数学学习分化的原因与对策
- “熊孩子”也许只是“娇宠过甚”
- 浅议幼儿小学化教学的危害
- 浅谈“一对一数字化学习”如何开发学生自主学习力
- 幼儿课程游戏化教学实践探索
- 数学与财务管理
- 初中物理生活化提问与学生学习心趣的培养
- 浅谈提高寄宿制农村小学中年段学困生学习数学兴趣的方法
- 高中化学备考浅谈
- 让口语交际课回归儿童生活
- 浅析高三学生如何高效复习数学函数
- 牵手跳动的音符
- 浅谈运用校园心理剧解决小学生考试焦虑的有效方法
- 论如何做好小学生培优补差工作
- 浅谈体验式团体心理辅导技术在小学生心理健康教育中的运用
- unecstatically
- uneddied
- uneddying
- unedge
- unedged
- unedges
- unedging
- unedificial
- uneducated
- uneducatedness
- well-convinced
- well-cooled
- well-copied
- well-corrected
- well-corseted
- well-costumed
- well-couched
- well-counseled
- well-counselled
- well-coupled
- well-courted
- well-crammed
- well-credited
- well-criticized
- well-crocheted
- 尊长所给予的关心照顾
- 尊长把财物送给地位低的人或晚辈
- 尊长教诲
- 尊长照顾晚辈或祖宗保佑子孙
- 尊长的教化
- 尊长阅览
- 尊閟
- 尊门
- 尊阀
- 尊阁
- 尊阃
- 尊顯
- 尊颜
- 尊食
- 尊驾
- 尊高
- 尊高的帝位
- 尊齿
- 尋
- 對
- 對醬
- 導
- 導言
- 小
- 小一辈