白阳 万洪林 白成杰


摘要:在对GoogLeNet模型分析的基础上,通过Caffe平台上使用开源GoogLeNet模型,对Stanford40静态图像集中人体行为进行分类研究,得到top-5准确率为50.23%,这些工作对深入理解GoogLeNet模型和静态图像中人体行为分类的研究有所帮助。
关键词:人体行为分类;GoogLeNet;静态图像
中图分类号:TP18 文献标识码:A 文章编号:1009-3044(2017)18-0186-03
1概述
在静态图像索引和检索中,人体行为分类有许多潜在的应用。目前,对静态图像中人体行为的分类已有很多研究。有些方法是用整幅图片直接进行分类,如基于空间金字塔法、随机森林法等构建的分类器;有些方法是利用对象与人之间的相互作用或者是人体的姿态进行分类;还有些方法是利用整体和局部属性进行识别。随着深度学习的发展,卷积神经网络作为一种深度学习框架,通过卷积运算来由浅人深的提取图像不同层次的特征,且整个网络可以自动调节卷积核的参数,从而无监督的产生最适合的分类特征,取得较好的分类效果,使卷积神经网络成为当前图像识别领域的研究热点和发展趋势。
1998年,纽约大学教授Yann LeCun开发了一套能够识别手写数字的系统LeNet,这是卷积神经网络第一次用于解决实际问题。2012年,Geoffrey和Alex在ILSVRC竞赛中提出AlexNet模型,并赢得冠军。2014年ILSVRC挑战赛由Google团队提出的一种深度卷积神经网络架构GoogLeNet模型夺得冠军。随着卷积神经网络结构的不断增强,其处理的问题也可以相应变得更加复杂,本文实验使用GoogLeNet模型来测试对静态图像中人体行为的分类效果,并加以分析。
2 G00gLeNet解析
GoogLeNet是由一种深度卷积神经网络架构构成的,其网络架构代号为Inception。该网络架构的特点是提高了计算资源的利用率,可以在保持网络计算资源不变的前提下,通过工艺上的设计来增加网络的宽度和深度,从而优化网络的性能。
2.1基本单元
GoogLeNet是由卷积神经网络构成的,而卷积神经网络一般由输入层、特征提取层和全连接层三部分构成。
输入层输入测试集和训练集数据,在输入之前,需要对测试集和训练集进行标签标注和归一化等预处理。全连接层把得到的多个特征映射转化为一个特征向量,并在其中以完全连接的方式输出,最后得到图像的特征,然后结合预处理时的标签进行分类识别。
特征提取层是卷积神经网络的核心,主要包含卷积层和池化层,二者相互配合来学习图像的特征。输入层的特征经过卷积层映射到新的特征空间,再将得到的特征作为池化层的输入;池化层对得到的特征进行抽样,对区域取最大值的最大池化或取均值的均值池化来进行降采样。
2.2网络架构
GoogLeNet神经网络模型是在LeNet神经网络模型的基础上,通过加深网络模型的深度和宽度所构建的一种深度卷积神经网络模型。该网络加深了LeNet模型的深度,使带参数的层达到22个,独立成块的层总共有100多个。GoogLeNet网络的像素感应大小是224×224,采用了RGB彩色三通道。同时,为了避免梯度消失问题,在不同深度处增加了两个loss来保证梯度回传;为了防止过拟合,减小误差,强化特征,并加快收敛速度,在模型的所有卷积操作之后,都用了修正线性单元(Re-LU);最后将softmax作为分类器。
GoogLeNet在网络宽度上的增加体现在结构中加入的In-cepfion模块,如图1所示。
Inception的主要思想是找出图像的最优局部稀疏结构,并将其近似地用稠密组件替代。这样可以实现有效的降维,从而能够在计算资源同等的情况下增加网络的宽度与深度,并减少需要训练的参数,减轻过拟合问题。而且该架构实现了在不同的维度上提取图像特征并加以整合,使特征值更丰富,使得图像更易识别。
3实验结果及分析
实验在Ubuntu14.04系统下进行,CPU为Inter(R)Core(TM)i7-4790 [email protected],GPU為NVIDIA GeForce GTX 750 Ti,卷积神经网络框架为Caffe中开源的GoogLeNet框架。实验在GPU模式下进行。
3.1数据集
采用Stanford40数据集,其中共有40个类别,每个类别有180~320张图像,数据集共计9532张图像且均为RGB彩色图像,但由于数据集中图像尺寸有些许差别,因此在对图像进行学习分类之前,应先对图像尺寸进行归一化处理。图2所示为部分类别,包括跳跃、射箭、做饭、拉小提琴、打电话、攀岩、扔飞盘和切菜。
3.2实验平台
实验在Caffetm(Convolutional Architecture for Fast Feature Embedding)平台上进行。Caffe是一个实现卷积神经网络相关算法的框架,其应用的神经网络模型由若干个不同的层组成,且各层是模块化的,便于用不同类型的层来定义模型。
实验使用基于Caffe平台的GoogLeNet模型作为分类模型,该模型与文献[12]有些许不同。第一是初始化数据使用“Xavi-er代替了“Gaussian”。Gaussian是最早的一种可以实现很接近0的方法,带有较强的随机性,但也具有中央分布的特性,而Xavier可以认为是Gaussian的一种改进版,使网络具有更显著、更快的收敛性,且使得数据信息可以更好的在网络中流动,并解决梯度消失等问题。第二是改进了学习速率衰减方案,使用线性衰减“poly”交替了阶梯式衰减“step”,使得训练速度变得更快。
3.3实验过程
在进行实验前,先将Stanford40数据集中每种类别的40个图像作为测试集,剩下的图像作为训练集,即训练集共计7932张图像,测试集共计1600张图像。将测试集和训练集分别放入两个文件夹中,然后在Caffe中进行标签注释。实验中需要将数据集全部图像的尺寸分别规划为256*256、288*288、320*320和352*352,从而形成四组实验数据,每组数据(9532张图像)分别进行测试。
每次实验时,实验模型为GoogLeNet。原始数据输入为224*224*3,经过第一层卷积层convl,输出特征为112*112*64,然后进行relu,经过pooll,进行norm;再经过第二层卷积层conv2,然后进行relu、norm、pool2;第三层进入Inception模型,该模型使用4种不同尺度的卷积核来处理问题,即数据分为四条支线进行处理,然后对数据进行连接;再分为四条支线进入第四层,以此类推,最后以softmax作为分类器得到分类特征。
由于在网络中间层产生的特征可能会有判别性,所以在中间层添加辅助分类器,且中间层添加的辅助分类器损失都会加权(0.3)计人总损失。实验输出为第一个辅助分类器输出损失lossl/loss及准确率lossl/top-1、lossl/top-5,第二个辅助分类器输出损失loss2/loss及准确率loss2/top-1、loss2/top-5,最终损失loss330ss及最终准确率loss3/top-l和loss3/top-5,共9个输出。
3.4实验结果
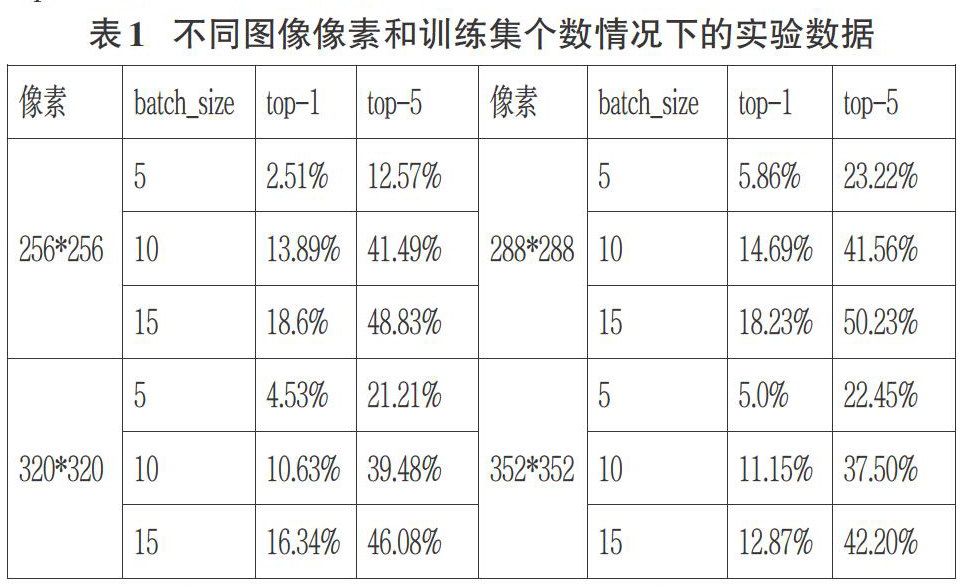
实验结果取损失loss3/loss及准确率loss3/top-1和loss3/top-5为最终结果,分别记为loss、top-1和top-5,其中top-1和top-5的部分实验数据如表1所示。
3.5实验分析
依据图3和图4中的数据分布情况可以看出,GoogLeNet的准确率受训练集每次的迭代个数和图像初始化像素大小的影响。准确率大体随训练集迭代个数的增加而增加,中间也有间断的回落,同时图像尺寸也影響着图像分类的准确率。
在本次实验中,在图像像素初始化相同的情况下,分类准确率大体上随训练集每次迭代个数的增加而增加,在最高迭代个数为15的情况下得到最高的分类准确率。在训练集每次迭代个数选定为15的情况下,图像像素初始化为288*288时,分类效果最好,得到top-5准确率的最高值50.23%,top-1准确率的最高值18.23%。
Stanford40数据集共有40个分类,分类类别较多,且每类每个图像的背景都比较复杂,主体中人体行为动作有一定程度上的相似,这些都给图像分类增加了难度。受框架限制,对样本的特征提取可能并不完全,且在图像尺寸不同的情况下,网络模型选取像素区域的不同也影响着实验的结果。
4结束语
人体行为静态图像识别作为计算机视觉的研究热点,其难点在于背景的复杂性和人体行为的复杂性,大大增加了人体行为识别的难度。在Caffe平台上使用开源的GoogLeNet模型,对Stanford40静态图像集中人体行为进行分类研究,得到top-5准确率为50.23%,相关研究工作对深入理解GoogLeNet模型等卷积神经网络和人体行为分类研究有所帮助。
随着卷积神经网络的深度以及宽度的不断加深,卷积神经网络模型将可以对更复杂的图像进行特征提取,其强大的特征识别能力也会得到充分地体现,可解决更困难的问题,卷积神经网络的应用范围将更加广泛。
- 机关档案室文书档案整理中存在的问题及对策
- 高校图书馆服务大学生创新创业的对策探究
- 浅谈如何促进文物修复技术的发展
- 基于公共文化服务的高职院校图书馆服务创新研究
- 新时期档案业务指导工作中存在的问题及对策
- 档案鉴定的原则与方法
- 公共图书馆青少年动漫阅读推广活动研究
- 关于民政档案管理的规范化的探讨
- 京津冀公共图书馆少儿阅读推广研究
- 加强地方市县及以下基层单位档案管理工作的迫切性
- 基于微信的阅读推广应用策略
- 新时期医院电子档案的数据安全研究
- 高校移动数字图书馆信息共享空间服务模型构建研究
- 新形势下档案管理工作的规范化解析
- 浅谈农业科技档案管理
- 基于文献学术力影响的图书馆馆藏资源建设与优化策略
- “互联网+”时代图书馆开展企业竞争情报服务研究
- 档案管理现代化的问题与策略
- 国外3D打印服务给我国图书馆带来的启示
- 县级公共图书馆对特殊读者群体服务探讨
- 基于要素分析的数字图书馆信息服务模式研究
- 百姓文化生活与基层图书室的建设保障
- 浅谈图书馆服务制度创新
- 基于学科分布的馆藏期刊纸质资源建设研究
- 图书管理信息化建设的思考
- antihumanistic
- antihumanists
- antihumanitarian
- antihumanitarians
- antihumanities
- antihumanity
- antihunger
- antihunter
- antihunting
- antihuntings
- antihygienic
- antihygienically
- antihypertension
- antihypnotic
- antihypnotically
- antihypnotics
- antihysteric
- antihysterical
- anti-icing
- confusive
- congame/con
- congeal
- congealabilities
- congealability
- congealable
- 睽索累年
- 睽绝
- 睽辞
- 睽违
- 睽迸
- 睽阔
- 睽阻
- 睽隔
- 睾
- 睾丸
- 睿
- 睿博
- 睿命
- 睿哲
- 睿图
- 睿圣
- 睿奖
- 睿好
- 睿学
- 睿山大师
- 睿岳
- 睿幄
- 睿德
- 睿思
- 睿情