基于格局理论的多模态语言档案数据库建设研究
彭飞
摘要:本文对现有语言档案数据库进行调查,就其存在的缺少原始语音信息、系统搜索功能单一、资源非共享、音質保真度低等问题,提出如何构建格局理论的多模态语言档案数据库建设,并对该数据库中的语音子数据库、图像视频子数据库和文本子数据库的基本结构和主要功能进行详细分析。
关键词:格局理论多模态档案数据库
自20世纪90年代以来,蒙古语、哈萨克语、维吾尔语等多种少数民族语言档案数据库陆续建设成功。20世纪初,安多藏语、云南各少数民族语言运用新技术,拥有了自己的有声语言数据库。2011年,“浙江方言语音档案建设工程”开始建设,包含了68个方言点,涉及语音、词汇、语法及说唱、歌谣、戏曲等内容,同时还录制了部分音视频材料。通过这种方式,一定程度上改变了口口相传或文字记载等保留方言的传统形式,对保存和抢救民族语言资源具有重要意义。从整体上看,目前我国语言档案数据库建设尚处于探索阶段,面对大数据以及“互联网+”的挑战,如何实现对语言档案的有效管理将成为档案学研究的热点。其中,本文所涉语言档案数据库指的是以录音、录像等多种电子媒体录制民族语言资源有声语料,以高保真的质量为目的,收集研究样本而建立的数据库,它可以原生态地保留现阶段有关语言的语音、词汇、语法及篇章等面貌。
一、基于格局理论的多模态语言档案数据库的提出
以往的语言档案和数据库研究,通常都是从词汇、语音或者语法的某个方面入手,缺少相互之间的联系,导致材料缺乏整体性和相关性。另外,在研究范式上,大多数语言档案数据库仅依靠文字、录音等,各种信息之间的匹配度和精准度一直受到质疑。具体而言,现有的各种语言档案库,如丁邦新等开发的“汉藏同源词研究系统”,收录了汉藏语系122种语言和12种汉语方言的1500余条词汇;中国科学院多民族语言资源数据库,建立了汉语、藏语、蒙语和维语的平行语料库和形态库,目前收录了781篇文章的文本信息;上海语言资源有声数据库仅列举了上海不同区域的几十个单音字。这些语言档案库均在不同程度上存在缺少语音原始情景信息(如无法直观用图像展示两个音的差异)、系统搜索功能单一(大多仅用于搜索汉语普通话对应的方言词或民族词)、资源非共享等缺陷。在技术层面上,档案声音的音质也不够理想,录像不够清晰,数据清晰度和保真度较低。
针对上述问题,笔者提出从格局理论的角度出发,建立多模态语言档案数据库。其中,格局理论提倡用科学实验的方法对语言进行研究,用计算机软件将原本口口相传的内容转变成可视图像,构建出一种语言或方言的格局。即把语音学和音系学联系在一起,用于声调、元音、辅音、语调、韵律、听感等多个方面的研究,能够从这些维度全方位地保存语音的原始情景信息,提升数据的完整性。多模态研究则是通过多种技术手段采集人们使用语言过程中所呈现的各种类型的多模态数据,发掘蕴含在音频、视频、图像等各种媒介中的各种信号、数据,从而多维度地解读人们言语交际的意义及其产生机制,有效进行语言档案的采集和保护。在此基础上的格局理论下的多模态语言是一种融合了多种符号模态进行交际的话语,除了传统的文本之外,它还包括口头语言、图像、体态语、音调、音乐等形式,具有复合性和动态性的特点,能够全方位地展现语音的特点。与常见的词汇、语法等传统文本语料库相比,多模态语言档案数据库的语料采集、转写、切分、标注以及建库均不相同。它采集的所有语料必须是高保真、非压缩的语音信号,这样才能完成后期语音实验,数据的准确性可以得到保证。也可以采用高速摄像头、呼吸带等最新研究仪器,进行跨学科研究,关注发声态、韵律等特征。最近也有专家尝试用Terason超声仪、电磁发音记录仪(EMA)等采集更多复合信息。综上,本研究以格局理论为指导,参照国际语言档案数据库的标准,采用新型的生理及声学观测方法,收集多模态的语言数据,采用最新搜索技术(包含文本和声音搜索,还有二三次搜索),从而建设了一个动态的、数字信息化的语言档案数据库。目标是将数据中包含的性别、年龄、表情等信息综合处理,提高信息处理的速度和准确度,为信息资源建设服务,实现资源共享。
二、基于格局理论的多模态语言档案数据库的构建
多模态语言档案数据库的建设并不是简单地录音、摄像保存,而是一个系统的、多维度的立体建设过程,从最开始的确定调查材料,经过数据采集、分析,到最后的建成使用,中间有多个过程。如图1所示。在构建多模态语言档案数据库的过程中,本文针对现有语言档案资源库存在的系统搜索功能单一、资源非共享等问题,特别强调各个系统及子系统档案数据库之间的交互性。这里,笔者主要以畲话为例进行阐述。畲话是浙江畲族群众普遍使用的一种语言,他们主要分布在丽水、温州等地。其中,景宁是我国唯一的畲族自治县,现有畲族人口约1.45万人。在前期田野调查时我们发现,越来越多的畲族年轻人已经不会说畲话了,可见建立畲话语言档案数据库迫在眉睫。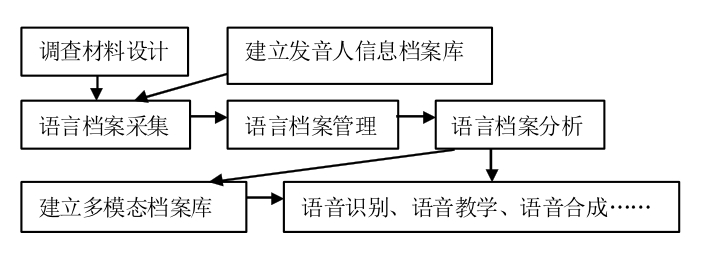
(一)调查材料设计
这是建设语言档案数据库的第一步。在这个过程中,需要注意的是语言档案数据库是否具有代表性,其体现在分析得出的结果能否概括这种语言的整体或指定部分的特征,进而归纳出语音格局。在参考其他学者音系研究的基础上,笔者所在课题组制定了录音的字表、词表、句表和语篇。原则是尽量选取畲话中使用的自然语言作为调查材料,主要包含使用频率较高的常用字词、具有畲话特征的字词、具有代表性的语音结构的字词,每一部分都要经过精心设计。最终的语料文本由以下部分构成:9个单元音、20个辅音、6个声调。
1.在设计字表的时候,分为元音、辅音、声调三个部分,根据录音要求分别制定。如针对每个声调,所用发音字表设计了包括六个声调在内的单音字6组,其中每组包含同一声调的单音例字10个。这样能够保证用尽量少的语料覆盖全部的声调和语音,进而使数据库的冗余度较小。相较而言,词表的设计相对复杂,我们主要设计了双音节词,研究畲话中的连读变调现象。6个声调,构成了36种组合方式,每种组合方式有6个词语,共得到196个语料。
2.句子和语篇设计包括朗读部分和表达部分。朗读部分主要包含经过处理的畲族民间故事、诗歌等。语篇设计尽量做到聲、韵、调搭配的全面性,同时考虑不同的语调、韵律、音段等。为了使语料包括不同的韵律结构单位,设计的句子包括畲话的多种句类、句型、句式。表达部分确定了一些常见话题,主要有个人经历、家庭情况、情景描述等,构成了鲜活的“口述档案”。这一部分不指定文本,记录发音人独自表达或与他人交谈时的数据,因此自然度较高,收集到了一些特殊的语音现象,如情绪、心理变化对语调的影响、口语化的停顿与呼吸模式等。
(二)建立发音人的信息档案库
为了保证研究结果的科学性,我们在选择发音人前,确定了相关标准:一是世代生活在景宁当地的畲族群众,母语为畲话,没有长时间外出经历,家庭成员均为畲族。二是均为右利手,听力和发音器官均正常。三是发音当日身体健康,无影响录音和录像质量的疾病。四是认识语料中的汉字,但无语言学背景知识。经过筛选,笔者所在课题组选取了不同年龄段(20-60岁)的5名男性和5名女性,作为储备发音人。
(三)语言档案采集
语料采集是语言档案库建设的关键。其采集过程包括实验系统的配置、实验地点的选取、预实验的实施及问题处理、实验后期数据鉴别等。传统的田野调查多选取在安静的普通房间内,用录音笔等方式录音,对录音质量的控制并不严格,效果也差强人意。为此,为了保证语音样本的准确性,解决数据失真的问题,笔者所在课题组通过与景宁电视台合作,使用技术最新的录音棚进行录音,声卡采用Sound device USBPre2,话筒采用头戴式指向性话筒AKG C520,极大地控制了噪音。此外,我们还采用了高速摄像头、呼吸带等作为采集系统,采集发音时面部嘴唇和表情、呼吸韵律节奏等信息。这样,便于语言档案的采集、管理和开发,能够使数据达到高保真、高清晰的多模态效果。
(四)语言档案管理
为了能够集成化管理语料,我们设计了一系列的语音文件命名规则。每个文件的名称由性别(男M、女F)、年龄(老年E、中年M、青年Y)、录音时间(年、月、日)、类型(字A、词B、句C、段落D)、发音人编号(001、002……)等组成,如编号“MY20150123A”的文件,想要表达的是发音人是一位男性,青年人年龄段,录音时间是2015年1月23日,单字音,编号是002。这样,录制的每一个文件都有自己的名称,调取和保存较为方便,有利于信息处理。
(五)语言档案分析
大规模的录音采样完成后,需要对数据进行处理,以提高数据库质量。每次录音完毕后,都由畲话母语者检验录音文件是否正确,进行检查和补录。在技术上,需要处理噪声,如过长的静音段、咳嗽声等。之后将录音导入到南开大学研发的电脑语音分析系统“桌上语音工作室”的软件中,进行测算和统计作图。以声调为例,需要得出发音字的基频图,调整曲线然后进行统计,将数据加入声调格局,最后用语音分析软件画出声调格局图,如图2所示。其结果主要用于语音识别、语音合成等。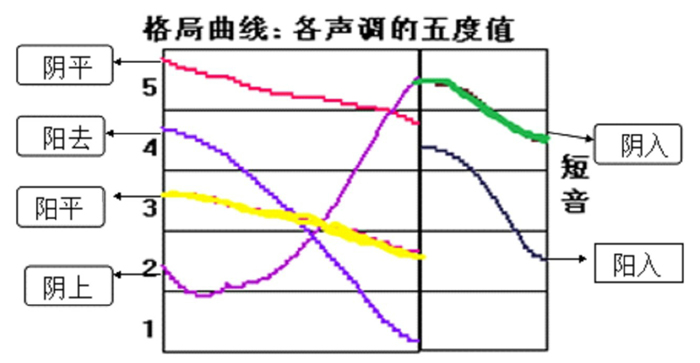
三、多模态语言档案数据库的基本结构及主要功能
多模态语言档案数据库主要由三个子数据库组成,即语音子数据库,图像、视频子数据库以及文本子数据库。
1.语音子档案库用于存放畲话的语音信息及其属性、链接等。语音信息主要指字、词、句、段落的发音,也包括连读变调以后的发音。语音特征信息包含了音系特征、字音特征和语调特征等。通过比较,可以较好地看到畲话与其他语言或方言之间的联系与区别。语音数据库主要包括字音库、词音库、句音库和语篇音库等。
语音子档案库主要用来检索,目前可以提供文本(包括汉字、国际音标、汉语拼音等)的检索方式。同时,以畲话的语音为检索条件,可以迅速找出调类、调型、变调、韵律等语音特征,有效实现普通话与畲话之间的双向匹配。通过控制搜索条件,点击语音库里的字、词、句、段落,便可以听到不同发音人的原生态发音信息。逐步采用智能化检索功能,与用户进行交互。检索结果可以进行二、三次检索。
2.图像、视频子档案库用于存放与语音信息相匹配的图像、视频信息。它是一个集成化的系统,用户点击语音信息时,旁边就会出现发音人发音时的脸部、体态图像与视频等。而这些基于现代信息技术对方言的原始记录语言档案,能够原汁原味地呈现方言的语言内涵,避免在保存过程中出现失真的情况,最大限度地实现对语言档案的整理、开发、利用和保护。
3.文本子档案库主要用于存放畲话的字、词、句、段落等文本信息及其属性、链接等。具体包括字库、词汇库、句库、段落库等。对各部分的语音材料进行文本转写,与语音数据库同步呈现在屏幕上,实现三个子数据库数据的平行呈现。
以上三个语言子档案库是一个集成化的系统,在各自独立的基础上又存在密切联系,构成新的语言档案库格局。除了在线学习以外,三个语言子档案数据库也提供下载服务。用户可以将检索的结果下载,输出语言数据的统计结果,也可以下载语音文件等。
*本文为教育部人文社会科学研究青年基金项目“景宁畲话的语音格局研究”(项目编号:14YJC740071)和浙江省社科联研究课题“景宁畲话的声调格局研究”(项目编号:2014B154)的阶段性成果之一。
参考文献:
[1]徐越.“浙江方言音档”的构建及预期价值[J].浙江档案,2012(1):39-42.
[2]洪拓夷.汉语方言语音数据库建设构想[J].图书情报工作,2009,53(5):83-86.
[3]石锋,冉启斌,王萍.论语音格局[J].南开语言学刊,2010(1):1-14.
[4]高原,顾明亮等.多用途汉语方言语音数据库的设计[J].计算机工程与应用,2012,48(5):118-120.
[5]陈子丹,郑宇,武泽淼.我国少数民族濒危语言建档的几点思考[J].档案学通讯,2016(4):92-96.
[6]张芳霖,汤晓良,谢雨菲.我国方言档案式保护的SWOT分析[J].北京档案,2016(2):27-28.
作者单位:中国计量大学
