摘要:通过对资源调度策略的深入研究与分析,参考数据库领域的并发控制等技术,提出了基于资源预测的分布式调度策略。其在两级调度策略基础上提供了资源预测、优化冲突解决等新特性,以全方面提升MapReduce作业调度的并发性、动态性和可扩展性。
关键词:MapReduce;作业调度;Hadoop集群;粒度
中图分类号:TP301
文献标识码:A 文章编号:1672-7800(2015)003-0018-03
0 引言
Hadoop的最初几个版本都采用单独的、中央化的调度算法处理每一个作业。集中调度结构清晰、设计简单,能够完成批量作业的调度及资源分配任务。Hadoop也不断改进更新集中调度,现在常用的有先进先出调度、按需调度[1]、计算能力调度[2]和公平调度[3]等策略。集中式调度策略的资源利用率较低,本地性、可利用性和灵活性较差。更为关键的是当集群机器数量足够大(1 000以上)时,全局的作业调度和资源分配方法很容易成为系统瓶颈,这在实际线上系统中被多次证明过。
为解决集中调度问题,出现了两级调度。两级调度器有一个全局的资源管理器,视为第一级调度,与之对应的各计算框架的内部调度器视为第二级调度。两级调度将集群资源(如服务器)划分为互不重叠的区间,每个区间至多允许一种计算框架的调度算法(如FIFO调度、公平调度等)。两级调度允许并行调度任务,因为每个区间互不影响。两级调度器仍保留一个经简化的中央式调度器,但调度策略下放到各个应用程序调度器完成。这种调度器的典型代表是Hadoop YARN[4]和Apache Mesos[5]。
两级调度使用分配插件作出分配决定,这极大提高了灵活性,用户可以根据不同需求加载不同的分配模块。两级调度采用操作系统容器技术隔离资源(CPU、内存等),采用分布式进程方法调度任务,这需要系统足够高效和健壮。为避免资源浪费,两级调度提供过滤机制,允许框架只接收节点列表中的节点或资源剩余量大于某一既定值的节点。整个集群的实时资源使用情况对两级调度的各个框架是透明的,因此两级调度的任务分配不能根据系统资源使用情况实时调整,这存在作业间资源相互干扰的风险。
1 基于资源预测的资源调度策略
1.1 调度策略设计
为了克服双层调度器的缺点,本文提出了全新的分布式动态调度策略,以期解决现存调度策略和新一代两级调度策略中的问题,最大限度地提升资源利用效率并缩短平均作业处理时间。基于资源预测调度SPR(Scheduling based on Prediction of Resource)将双层调度器中的集中式资源调度模块简化成一些持久化的共享数据(状态)和针对这些数据的验证代码,而这里的“共享数据”实际上是整个集群的实时资源使用信息。
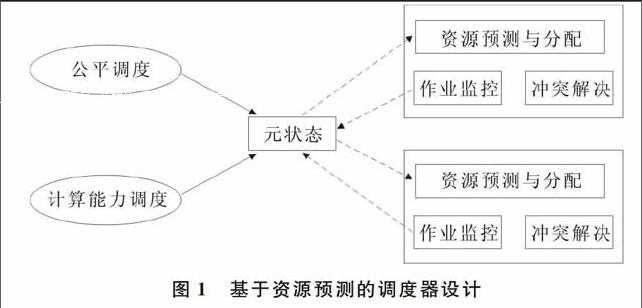
针对资源冲突和预测问题,SPR只在元状态中维护应用程序(作业)的优先级,而资源检测、限制、预测等作业分布在各个数据节点进行。其中,为更好地利用资源,增加了资源预测模块,该模块用于预测应用作业的资源占用量,并在允许范围内进行预留。此功能可以帮助系统更好地查看当前资源使用情况,并且根据检测结果作出相应预测与调整,最大限度地提高系统资源利用率。具体设计如图1所示。
1.2 资源预测
在MapReduce中,使用进度分来监控每个任务运行时的进展情况。在Map阶段,其代表了Map任务的输入数据部分;在Reduce阶段,其代表了被Reduce任务处理的中间数据部分。因此,在Map或Reduce阶段的所有任务执行相似的操作,每个任务消耗的资源量与输入数据成正比。换句话说,每个任务消耗的资源量与任务的进度分成正比。根据资源缩放因子的不同,任务完成时间有如下调整:如果资源缩放因子大于1(资源增多),任务完成时间会减少;如果资源缩放因子小于1(资源不足),任务完成时间会增多;如果资源缩放因子等于1,任务完成时间不变。本文提出两种方案作为资源预测机制。
资源预测负责为运行的任务构建可预测的资源使用及分配模型。本文介绍两种方案:第一种方案称为回归,采用统计回归模型为下一轮任务分配预计的资源;第二种方案称为统一,其收集过去一段时间内所有任务的资源使用情况并据此计算任务的平均资源占用情况,将该平均值作为下一轮任务预期的资源分配值。
回归方案确定分配给每个运行时任务的资源数量,并且考虑了典型MapReduce环境中可能遇到的问题,如节点异构、 负载不平衡、网络阻塞、节点宕机等。回归方案包含两个阶段:第一阶段输入给定任务进度分的时间序列,并根据任务生命周期的时间段运行情况输出预期的任务完成时间;第二阶段将给定任务过去多个时间段资源分配状态的时间序列作为输入,输出统计资源模型并产生预计的下一时间段资源分配情况。在任务生命周期的每个时间段,其预计完成时间由第一个阶段计算完成,然后第二阶段评测资源分配需求以满足目标完成时间。资源预测的伪代码如下:
算法1:资源预测计算。
输入TSusage并发任务资源占用情况的时间序列、TSprogress任务tid的进度得分时间序列、资源R、并发资源分配Rcur、评估方案(统一或回归),将TSusage和TSprogress分解成相等长度的时间窗口(W = {w1,w2,...wt})。
针对每个时间窗口wi:如果分配方案为“统一”(UNIFORM),计算同一时间段内所有任务和之前时间窗口w1...wi-1内作业的平均资源占用情况Rmean;否则如果分配方案为“回归”(REGRESSION), 通过基于进度分的模型获得期待的任务tid完成时间,利用线性回归模型计算期待的下一时间窗口资源分配值;返回资源缩放因子α。
算法2:给任务动态分配资源。
输入资源类型R(CPU或内存)、并发分配Rcur、任务ID(tid)、当前时间点ecur、资源缩放因子α,利用算法1计算预计的资源分配Rest。
如果Rest>Rcur,
给任务tid动态增加(α>1)资源R,大小为Rest-Rcur;
如果Rest
否则在当前时间窗口继续使用现在的资源分配Rcur。
统一方案基于直观的任务公平资源分配原则,以降低运行时任务资源占用变化并保证在预测的时间范围内完成任务。每个Map/Reduce任务的资源授权被设置为与同一作业中独立Map/Reduce任务的平均资源占用值。尽管如此,在实际应用中由于负载不平衡等原因,该方案可能无法很好地执行。统一方案的优点是非常简单而且资源消耗少。
1.3 冲突检测与解决
分布式动态调度SPR支持两种冲突检测方式:机器粒度和资源粒度(CPU等)。
对于事务,本文支持两种类型粒度:全部事务和自增事务。全部事务是原子的,全部事务可以支持群组调度或那些必须在其它作业完成后才能执行的作业调度;自增事务模式下,任何单一任务—资源分配都可以独立于其它分配而成功或失败,只有当任务—资源分配事务中没有任何冲突时,事务才算成功。
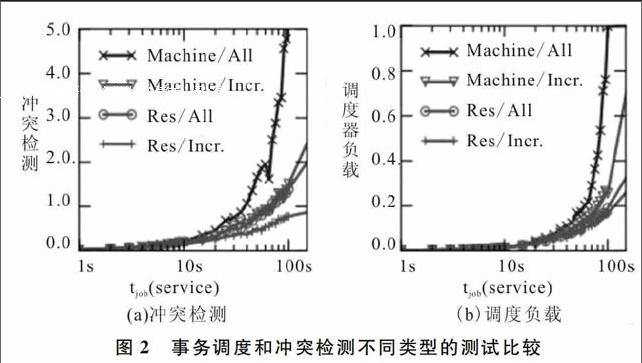
资源冲突检测和事务粒度都会导致附加的冲突和更高的调度器负载,图2是对Hadoop集群进行冲突检测及事务功能的监控情况。
如果打开全部事务调度,在资源粒度冲突检测模式下所有作业的调度器负载只有少量增加,但是冲突概率增加了一倍多,从而导致错误概率相应提高。因此该选项仅适用于作业级别。机器冲突检测粒度的效果更差,冲突概率和调度器负载均大幅增加。所以对递增事务粒度进行默认设置可得到最好效果。
2 新调度器评估
2.1 评估环境
虚拟集群具有方便扩展、平台无关、移植性强等特点,所以将Hadoop集群部署在虚拟云环境中。虚拟集群由6台ESX虚拟机及一台vCenter机器组成,其中每台ESX虚拟机配置8核、64位、2.6GHz英特尔Core处理器,16GB内存,1TB SATA硬盘和4个千兆以太网卡。本文测试中创建24个Linux服务器(每台机器配置2核、2.6GHz处理器, 4GB内存,250GB硬盘和千兆网卡),运行Hadoop 2.4.0。vCenter提供资源管理、动态分配及迁移等技术,以保证虚拟机集群的稳定性。
采用的作业主要有以下4种:①排序:排列20GB的随机文本内容;②单词计数:在20GB 维基百科文本内容中计算单词出现频率;③正则表达式:在20GB维基百科文本内容中寻找符合随机正则表达式的单词;④分布式Web服务器:在Hadoop集群上搭建分布式Web服务器,利用Hadoop处理服务数据。
这些作业根据流行程度而被选取,其中前3个代表了批量作业(短作业),最后1个代表了服务作业(长作业)。并且这些任务分别代表了不同类型的负载,排序和正则表达式是CPU和IO资源敏感型作业,单词计数是CPU限制作业。
2.2 并发测试
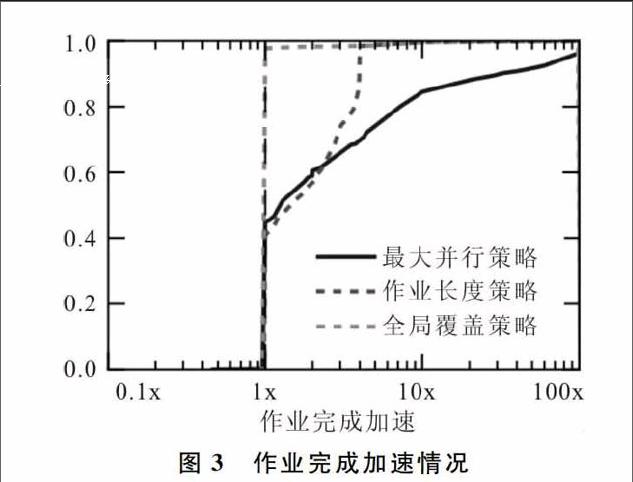
通过对Hadoop集群运行情况的追踪,评估了资源分配策略,从而认为50%~70%的作业可以从加速使用机会资源中获益,更大的加速效果会在后期予以显现。因为这虽然是一个简单的线性模型,但至少可以加速80%。在本次测试中利用最大并行策略,加速了3~4倍。
尽管最大并行策略取得了显著效果,但相关作业大小同样做得很好,它只需构建极少的MapReduce工作线程。全局负载策略在规模较小的、资源未被过度使用的集群中表现的与最大并行策略一样好。具体情况如图3所示。
为Hadoop作业分配资源会提高集群的资源使用率并可以使作业尽早完成,然后所有作业占用的资源会被释放。该方式会影响集群资源利用的变换情况,如图4所示。
为了做该项测试,MapReduce调度器需要能够看到集群的整体状态。相似的论证可以在特殊的高限制、高优先级作业的调度器上实施。调度需要决定合适的机器以及在只有少量可抢占资源时如何更好地配置新作业。该调度器非常适合这些工作,原型证明,向该调度器添加相应功能非常容易。
3 结语
最近有研究基于估测的作业完成时间动态调整资源分配的调度技术,不同类型的资源调度策略也被提出,但这些工作并没有定位Hadoop中调度问题的基础性原因,如静态、粗粒度资源分配等。当前的Hadoop调度器在执行作业时并不是资源敏感的。本文提出的调度策略能够从根本上解决这些问题。此外,还有很重要的一点,本文的调度策略是在作业运行期间评估资源需求,而不是根据提前分配的作业优先级来固定分配资源。
暴露全部集群状态信息给调度器与暴露最大限度的信息不同。编程语言和操作系统团体正在重新考虑将应用级调度作为通用线程和进程调度器的候选项,单一、全局的操作系统调度器在可扩展性、灵活性等方面无法满足现代多核任务的需求。
将来需要在提供全局保证(公平、饥饿避免等)方面进行研究,因为集中控制可以使工作变得更简单容易,而且通过某些技术可以降低长决定时间时相互干扰的影响。对于本文调度策略可控制的系统资源是CPU和内存,希望接下来可将磁盘和网络情况纳入进来,从而更全面地控制资源分配。此外,也需要在更大规模的Hadoop集群中测试本文调度策略的性能,并进行改进更新。
参考文献:
[1] Hadoop on demand scheduler[EB/OL].http://hadoop.apache.org/docs/stable1/hod_scheduler.html.
[2] Hadoop capacity scheduler[EB/OL].http://hadoop.apache.org/docs/stable1/capacity_scheduler.html.
[3] Hadoop fair scheduler[EB/OL].http://hadoop.apache.org/docs/stable1/fair_scheduler.html.
[4] YARN[EB/OL].http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YARN.html.
[5] HINDMAN, BENJAMIN, KONWINSKI, et al. Mesos: a platform for fine-grained resource sharing in the data center[J]. InUSENIX NSDI, 2011:22-22.
(责任编辑:黄 健)
- 广东技校学生复工忙 防疫物资供应有保障
- 【浙江省技工院校战疫实录三】有序助力复工复产 疫情防控保障措施得力
- 【浙江省技工院校战疫实录二】教职工“疫”呼百应下企业 “智”助复产有作为
- 【浙江省技工院校战疫实录一】万余学生“挑大梁” 企业复工“加速度”
- 用技能支援企业复工复产
- 浅谈文秘人员沟通能力的提高
- 在职业学校开展球类专项教学的可行性分析
- 浅析中职体育教学对学生心理健康的影响
- 数控程序辅助编辑器在数控加工编程教学中的应用
- 浅谈班级微信公众号在班主任工作中的应用
- 企业新型学徒制人才培养模式下的高职教学管理体系
- 关于管办评分离背景下人才培养质量评价体系的研究
- 高职院校工程造价专业优秀工匠培养途径的研究
- 浅析基于核心素养的中职外贸专业课考试命题改革
- 职业院校审计基础课程改革探索
- 藏区职业教育转型升级中若干问题的思考
- 职业道德教育走出窘境的对策
- 对中职学生“底层”心态的几点思考
- 技能大赛与中职学生就业创业能力培养的研究
- 教育科研顶层设计助推中职学校发展
- 以信息化建设推进职业教育现代化
- 浅谈职业教育学生服务意识的培养策略
- 精冶巧匠深耕耘“玉林技工”谱华章
- 重庆市艺才技工学校:“授渔工程”技能脱贫成就出彩人生
- 赏识约束双教育 立德树人重养成
- unused to
- unusedto
- unused to sth
- unused²
- unused¹
- unusefulnesses
- unushered
- unusual
- unusuality
- unusually
- unusualness
- unusualnesses
- unusurped
- unusurping
- unutilitarian
- unutilizable
- unutilized
- unvacant
- unvacantly
- unvacated
- unvagrant
- unvagrantly
- unvagrantness
- unvagrantnesses
- unvague
- r2013010010002171
- r2013010010002172
- r2013010010002173
- r2013010010002174
- r2013010010002175
- r2013010010002176
- r2013010010002177
- r2013010010002178
- r2013010010002180
- r2013010010002181
- r2013010010002182
- r2013010010002183
- r2013010010002185
- r2013010010002186
- r2013010010002189
- r2013010010002191
- r2013010010002193
- r2013010010002194
- r2013010010002195
- r2013010010002196
- r2013010010002197
- r2013010010002198
- r2013010010002200
- r2013010010002201
- r2013010010002202