摘要摘要:对用户多账户检测识别是信息整合研究目标之一。针对目前用户识别技术普遍存在的准确率低和局域性问题,提出了基于交叉配血的多账户识别模型。该模型要求根据用户行为相似度和语义相似度绘制出多个账户的关系图,然后利用交叉配血原则来平衡语义和行为,在配置信息的协同下,对语义行为模型进行一致性识别。要求用户多个账户互相匹配以提高识别率,通过交叉匹配降低假种子账户对结果的影响。实验证明该算法大大提高了识别准确率。
关键词关鍵词:交叉配血;账户识别;语义分析;用户相似度
DOIDOI:10.11907/rjdk.162322
中图分类号:TP302文献标识码:A文章编号文章编号:16727800(2017)001000105
0引言
互联网中存在大量重复的用户身份信息[1],以国外知名网站Twitter、Facebook为例,约有47%的用户拥有超过一个应用账户,整合这些重复用户信息很有意义,对网络应用中的多账户进行判定[2]并整合,能够帮助网络服务提供商全面了解用户,从而提供更好的个性化服务。从网络安全角度鉴别用户多账户,能够协助网络安全管理者发现虚假或不法身份[3],保护用户权益。
为了整合用户信息,首先需要对用户进行身份识别、判定。影响网络用户身份识别的特征值主要有:配置信息、好友圈、行为和语义[4]信息等。目前识别方法主要有两种:①基于用户档案判定[5]的用户识别。该方法针对账户公有属性进行判定,然而账户公有属性相似度很大,导致准确率极其低下;②基于好友关系的多账户识别。该方案依据账户公共好友进行识别,但是多个账户并不拥有共同的好友圈,这严重影响识别准确度。
目前用户识别检测处于快速发展阶段,许多学者对传统用户识别进行了改进,例如周松松等[6]提出了基于URL的相似度会话识别方法,通过对URL的处理进行用户检测;业宁等提出一种Web用户行为聚类算法,通过对Web日志的处理,提取用户的访问行为。这些基于用户日志和URL的方法,在一定程度上改善了识别的准确率,但同时也引入噪声,没有充分利用用户行为,忽视了用户的语义。
为了提高用户多账户识别准确率,本文提出了基于交叉配血原则的用户身份同一性[7]判定方法。通过对行为和语义进行交叉匹配,生成准确的种子用户,进而进行综合判定识别。
交叉配血最初来源于生物学,其原理是将献血人的红细胞和血清分别与受血人的血清和红细胞混合,若无凝集反应说明两血型相合,反之不相匹配。依据上述方法可以解决脏血问题,从而保证安全输血。
交叉配血识别模型设计:①将各个账户的行为看作红细胞、语义看作血清,分别与其它账户进行交叉匹配;②把匹配度最高的账户作为种子用户进行下一轮测试,从而识别出用户所有账户。
在交叉匹配前需要对账户的行为、语义进行处理,识别处理过程如下:①采用矩阵聚类算法对用户行为相似度进行度量;②采用GVSM 的语义相似度算法对用户语义进行分析;③构造行为-语义加权无向图;④结合用户的配置相似度并按照交叉配血原则对用户行为-语义进行识别,从而得到准确的用户组。
1基于交叉配血算法的行为-语义识别
1.1多账户识别模型
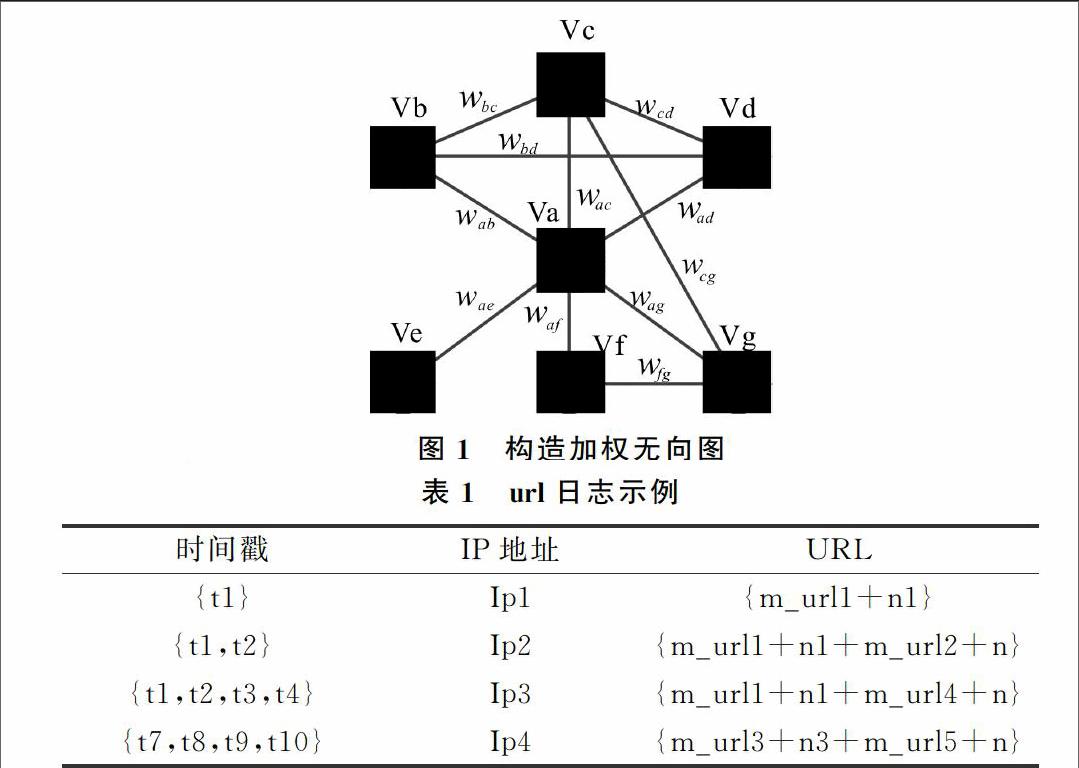
定义1:多账户识别模型: 通过用户行为和语义相似度构建交叉配血的多账户识别模型G=
根据行为、语义相似度构建无向图,行为、语义都存在噪声干扰,为防止噪声影响实验结果,经过大量实验分析,本文采取9%为行为噪声,14%为语义噪声。根据选定噪声阈值构建加权无向图,大于阈值的为有效信息,通过计算多个顶点相似距离从而得到账户相似度。
其中,Wij表示用户i和用户j的相似度,作为权值参与相似计算。
1.2用户行为相似度识别分析
用户的行为特征主要表现在时间和空间上,时间特征包含每次浏览页面的时间及有向路径[8]的浏览时间,空间特征包含页面的浏览顺序和点击信息等浏览行为。本文主要根据账户的访问日志和登录日志提取时间和空间特征值,通过对两个特征值进行聚类分析,得出各账户之间的行为相似度,如表1所示。
行为识别步骤:①通过用户访问模式分析得到账户时间特征值;②基于用户浏览相似度矩阵的聚类算法得出用户行为相似度。
用户访问模式[9]的访问路径包含超链接,用户点击链接访问网站。如果不同账户有相同的访问顺序,就意味着用户访问行为有一定的相似性。这是一个抽象的用户访问,可以被视为知识一致性页面,通过路径聚类[10]找到用户的访问行为,每个集合代表一类用户访问模式的相似路径。通过处理Web用户找到访问模式和用户行为偏好,用户访问行为偏好不仅反映在浏览网页的路径上,而且反映在用户访问Web页面的时间上。因此,通过挖掘用户的访问时间,可以分析多个账户的行为时间特征,得到各账户的时间特征值。
1.2.2基于用户浏览相似度矩阵的聚类算法
基于用户浏览相似度矩阵的聚类算法中,L=
定义1:用户浏览行为:用于记录用户浏览页面留下的信息,如公式(1)所示:
M=
其中,lm_userid=UserIDm,lm∈L,lm_ip=IPm,n≥1,hits代表了用户浏览lm_userid页面的次数。
定义2:网站模型G: 网站的拓扑结构可以看作是一个有向图,如公式(2)所示:
G=
定义3:urlID-UserID关联矩阵Mm×n:根据有向图G的节点集N可以得到所有网站的url,从相应的节点属性设置Np可以获得每个节点的标识和相应值的访问,可以创建urlID-UserID的相关矩阵Mm×n,如式(3)所示。
Sij是用户访问页面的数量,i是用户j访问页面的時间,每一列向量M[ ,j]表示用户j访问该网站的所有页面;每一行向量M[i,]意味着访问页面i的所有用户。行向量反映了用户的类型,描述了用户个性化的访问子图,列向量代表网站结构,包含用户常见的访问模式[11]。通过测量每一个行向量和列向量的相似性可以直接得到相似度。
Hij=0,表示用户没有访问的页面,Hij =1,表示用户j访问了i页面,Hij =2,用户j对i页面非常感兴趣,i是阈值(根据聚类情况而定)。
定义5:相似性sim(pi,pj):假设pi和pj是两个m维空间向量,pi=(ai1,…,aik …,aim),pj=(aj1,…,ajk …,ajm), 1
1.2.3算法步骤
1.3用户语义相似度识别
定义6:语义相似度:当两个元素(文字或者符号)具有某种特征时,则定义它们是相似的,可以用sim(x,y)(0≤sim(x,y)≤1)表示两个元素x、y的相似度。
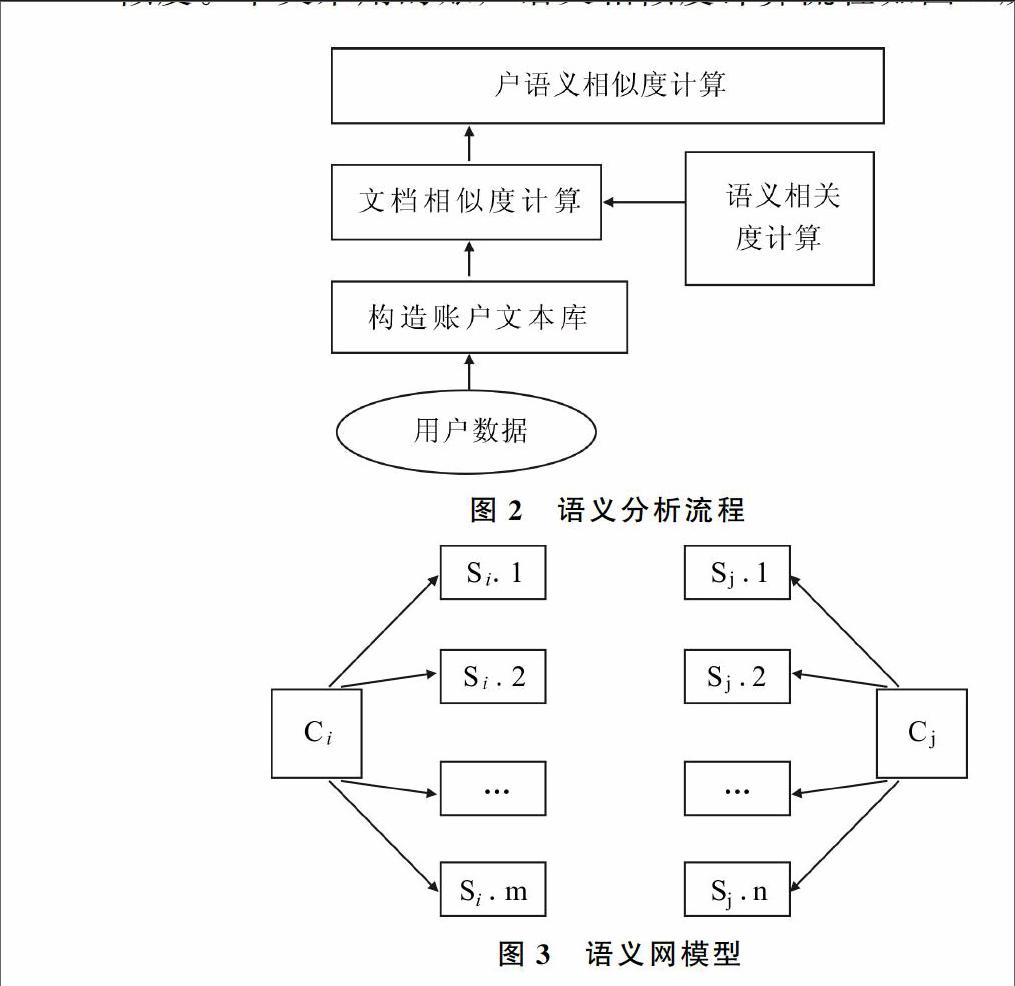
每个用户都有自己的语言表达特点,使用独特的叙述方式、频用词汇、断句方式、标点符号等;通过分析每个账户发表的评论、帖子、回复信息等,从而分析账户的语义相似度。本文采用的账户语义相似度计算流程如图2所示。
图2语义分析流程
采用基于GVSM 的语义相似度算法计算多个账户的语义相似度,通过构建语义网计算两个词的关联度,从而计算两个词的相似性。语义相关度 SR(Semantic Relatedness)表示两个词的相似性,采用语义网络建设模式,将每种类型的边赋予权值,权值越高说明两个词的关联度越高。
其中,si. m和sj . n分别是ci和cj的词义,m是ci的词义数,n是cj的词义数。
基于GVSM的文本相似度[12]计算模型:
R(ci,cj)=SR(ci,cj)·( si. m, si.n,O)
其中,SR(ci,cj)表示语义相关度,O是词库,本文定义文本向量,增加了ci、cj在文本Wk中的权值,定义如下:
Wk(ci,cj)=(tf-idf(ci,Wk)+tf-idf(cj,Wk))
·R(ci,cj)(6)
由文本向量构造GVSM模型,两个账户的语义相似度可以定义为:
sim(Wk,Wp)=
∑ni=1∑nj=1wk(ci,cj)·wp(ci,cj)∑ni=1∑nj=1wk(ci,cj)2×∑ni=1∑nj=1wp(ci,cj)2(7)
1.4行为-语义加权无向图模型构建
定义7:配置相似度(PAS):给出两个用户:v0∈V0和v1∈V1,v0和v1的配置文件,分别表示属性向量P0={f0i}mi=0(p0∈P0)和P1={f0j}nj=0(p1∈P1),p0和p1的配置属性相似度PAS(p0, p1)=H(Sp0,p1)∈[0,1],其中Sp0,p1是记录向量的相似字段,H是C4.5分类决策树算法模型。
为了把配置文件的属性与用户账户联系起来,本文采用账户亲密度(UC)函数来衡量两个账户之间的亲密程度,采用账户的距离(UD)函数[13]衡量两个账户之间语义和行为的差异性。如果两个账户邻接账户的相似度越大,那么它们的相似度就越高。
定义8:(User Closeness(UC) ):给出两个账户va , vb∈V和一个账户vm,其中vm与va和vb都相似,Fm代表va和vb邻接顶点的集合[14],a是a的邻接顶点,b是b的邻接顶点,UC函数表示两个账户的邻接账户权重和越大,两个账户越相似。
UC(va,vb)=w(va,vb)*
1-2(∑fm∈Fmw(va,vm)*w(vb,vm))∑a′∈Faw(va′,vm)+∑b′∈Fbw(vb′,vm)(8)
w(va,vm)表示邻接两顶点的路径权重。
为了避免噪声的影响,本文舍弃了部分相似账户,但并不说明它们两个不相似,如果它们的邻接顶点相似度很高,证明两个账户很近,也就是说,它们之间的距离是接近的(语义和行为达到平衡)。定义账户距离(UD)函数如下:
定义9:(User Distance (UD) ):给出两个不相邻账户(va∈V,vb∈V )和一个与va,vb都邻接的账户vm,那么va 和vb的距离可以表示为:
UD(va,vb)=∑fm∈Fmw(va,vm)*w(vb,vm)deg(Fm)(9)
deg(Fm)表示邻接顶点集合个数。
定义10:用户环绕分数(USS):给出一个用户v∈V,那么v的环绕分数USS的计算公式如下:
USS(v)=∑s∈SseedUC(v,s)*ηvs
UD(v,s)*ηv-s(10)
其中,η是增量系数,“”表示两个账户之间直接邻接,“-”表示不直接相连。
定义11:用户关系相似分数(URS):给出两个用户v0∈V0和v1∈V1,v0和v1的关系相似度计算公式如下:
URS(v0,v1)=∑s∈Sseed*
UC(v1,s)*ηv0sandv1s
(1-UD(v1,s))*ηv0sandv1-s
(1-UC(v1,s))*ηv0-sandv1s
UD(v1,s)*ηv0-sandv1-s(11)
定义12:用户匹配分数(UMS):给出两个用户vselect∈V0和v∈V1,vselect和v的配置文件是pselect∈P0和pv∈P1,vselect和v的UMS定义为:
UMS(vselect,v)=PAS(pselect,pv)*|Sseed|+
URS(vselect,v)(12)
其中,|Sseed|为识别的种子账户。
1.5账户选择及交叉匹配过程
账户选择过程分为3步:
(1)每次迭代的第一步均从行为图或语义图中选择一个账户,选择用户基于以下两个规则:①如果两个账户的配置文件具有很高的相似度,那么它们很可能是相同用户;②USS分值最高的用户更可能是匹配的,应该被选中。基于上述规则生成候选账户。
(2)计算每个账户(行为/语义)的USS。
(3)对行为和语义选出的用户进行排序,最高的作为下一组候选用户匹配,过程如下:在有一个候选人用户v后,需要匹配v用户,首先,需要从行为图或语义图确定候选用户vselect,利用交叉配血方法计算最匹配的用户,然后返回UMS分值最高的账户。
算法2:当得到匹配用户vmatched时,将这个用户作为一个新的候选用户,然后通过UserMatch方法得到一个新的匹配候选人v′matched。如果v′matched恰好也是vselect ,则意味着 vselect的最佳匹配的确是vmatched,也就是说这是一个稳定的匹配;如果Va、Vs是一组稳定匹配,那么Va和Vs是相似的两个账户,否则将用户vselect放进不匹配的数组,重置vselect和vmatched进行下一次迭代。如果没有新的种子用户,也就是所有的用户都已经参与匹配,则终止迭代过程,从而得到相似账户组。
2实验
2.1实验环境及数据
实验环境配置:使用Java语言,实验机器采用2G内存、500G硬盘,操作系统是Windows XP。
为了验证本文所提出方法的有效性,实验设计了5个对比。为了保护用户隐私安全,本文实验数据来自Twitter和Facebook公布的匿名数据集,由于系统数据庞大,实验仅采取2013-2014年部分区域网络内用户日志作为实验数据,共得到1 678 156条记录,经过数据清洗,删除一些gif、jpg等非文本记录,最终
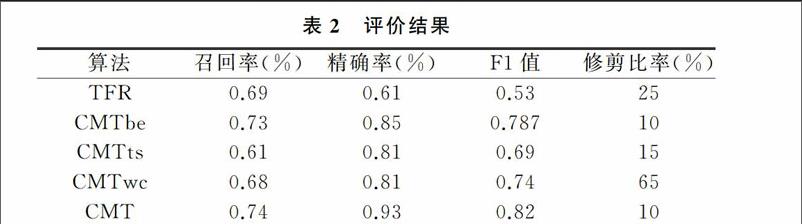
得无论是TFR算法还是基于单个行为或语义的算法,虽然可以实现比较高的精确度,但却导致召回率和F1值比较低。所有版本的CMT比TFR拥有更高的F1值,CMTwc算法效果要比CMTbe差,事实上这些算法包含了很强的修剪过程,因为没有交叉配血过程提供一个严格的条件,会有很多错误的种子用户作为结果影响实验精确度,所以必须以牺牲精确度为代价获得较高的召回率。
根据上述比较,可以看到CMT大多数版本拥有很高的召回率,这也意味着交叉配血策略行之有效。CMT除了CMTts外都有较高的性能,CMTwc通过很强的修剪过程来平衡召回率和精确率。在所有算法中,CMT性能最佳,这表明结合配置文件和行为语义是有效的方法。
实验2:为了验证种子用户数量对不同算法F1值的影响,针对上述实验数据集,采用不同算法分别选取1 000~4 000个种子用户进行实验,实验结果如图5所示。
由图5可知,随着种子数目的增加,CMT和TFR的F值都会相应递增,当增加到一定数量后递增速率会变缓从而达到稳定。CMT算法随着种子用户数量的增加始终比TFR拥有较高的F值,说明CMT算法在处理大量用户数据时更为准确。
实验3:为了更加清晰展示实验结果,生成如图6所示各个系统性能损耗对比,它展示了5个系统在用户识别上的性能。采用传统的方式来计算相似度,虽然不需要处理用户的行为信息,但复杂的关系网使其效率很低。而交叉配血算法提高了識别率,稳定性也是最强的。本文提出的按照交叉配血原则来计算用户多账户相似度,大大提高了识别效率,降低了系统开销。3结语
为了解决用户多账户识别问题,本文提出了一种新颖的交叉配血策略。结合配置文件属性、用户行为和语义信息,在CMT中使用交叉配血策略,用于检测种子用户,不仅降低了计算成本,还避免了复杂的修剪过程,提高了实验的准确性。实验证明该方案提高了识别算法性能和准确率。
图6算法实现效率对比
参考文献参考文献:
[1]ZHOU XIAOPING. Crossplatform identification of anonymous identical users in multiple social media networks [J].IEEE Transactions on Knowledge and DataEngineering,2015, 28(2):411423.
[2]YE NA, ZHAO YINLIANG, DONG LILI,et al. User identification based on multiple attribute decision making in social networks [C]. IEEE China Communications,2013:3739.
[3]兰丽辉,鞠时光,金华. 社会网络数据发布中的隐私保护研究进展[J].小型微型计算机系统,2010,31(12):23182323.
[4]L ZHIQIANG, S WERIMIN, Y ZHENHUA.Measuring semantic similarity between words using wikipedia [C].2009International Conference on Web Information Systems and Mining,2009:251255.
[5]MOHTASSEB H ,AHMED A. Twolayer lassification and distinguished representations of users and documents for grouping and authorshipidentification [C]. Intelligent Computing and Intelligent Systems, 2009:651657.
[6]周松松,马建红.基于URL的相似度会话识别方法[J]. 计算机系统应用,2014,23(12):191196.
[7]业宁,李威,梁作鹏,等.一种Web用户行为聚类算法[J].小型微型计算机系统,2010,25(7):13641367.
[8]MARISA GUTIERREZ,SILVIA BTONDATO.On models of directed path graphs non rooted directed path graphs[J]. Graphs and Combinatorics,2016,32(2):663684.
[9]SMITA NIRKHI.Comparative study of authorship identification techniques for cyber forensics analysis[J].(IJACSA) International Journal of Advance Computer Science and Applications,2013,4(5):299320.
[10]WANG WEN QI,IANGLIA FUZZY.Clustering algorithm based on weighted index and optimization of clustering number[C].the series Advances in Intelligent Systemsand Computing,2014:349359.
[11]BONCHI F, GIANNOTTI F. Web log data warehousing and mining for intelligent Web caching[J].Data and Knowledge Engineering,2001,39(2):165189.
[12]劉东,吴泉源,韩伟红,等.基于用户名特征的用户身份同一性判定方法[J].计算机学报,2015,38(10):20282040.
[13]R ZAFARANI,H LIU.Connecting users across social media sites: a behavioralmodeling approach [C]. Proc.of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD13), 2013:4149.
[14]孙琛琛,申德荣,寇月,等. 面向关联数据的联合式实体识别方法[J].计算机学报,2015,38(9):17391754.
- 公共关系学课程深度学习模式的实践与研究
- 广播电视编导专业实践教学模式探索
- 基于问题导向的研讨式教学模式探索
- 浅谈电视专题节目的编辑与策划
- 浅谈真人秀节目的寓教于乐
- 策划让《政风行风热线》类节目常听常新
- 从“六度分隔”理论看记者找寻有效采访对象的策略
- 电视民生新闻如何提升传播力
- 媒介融合环境下电视民生新闻的创新
- 城市家风文化的活化与传播
- 浅析新传播环境下的党报评论选题策划
- 乡村振兴战略背景下的乡镇综合文化站传播机制构建
- 微博热点事件网民评论中客体的泛化研究
- 运动健身类微信公众号的传播效果影响因素探微
- 融媒体时代VR电影的应用及发展探究
- 社交媒体“转发抽奖”传播中的议程设置研究
- 新媒体环境下广告二次传播的嬗变
- 大数据智能传播中的算法歧视及其治理路径
- 从相加到相融:纸媒品牌影响力重构的路径选择
- 以用户思维推进传统媒体转型
- 媒介融合背景下地方党报公信力提升策略探析
- 浅议高校媒体融合发展破局之策
- 智媒时代文史类内容产品的新机遇
- 田野审视与时代解读:全球语境下的传统文化讲述
- 新时代教育题材电视剧的叙事研究
- infrastructural
- infrastructure
- infrastructures
- infra-structure's
- infrequency
- infrequency's
- infrequent
- infrequently
- infringe
- infringed
- infringement
- infringer
- infringers
- infringes
- infringing
- in front
- in-front
- in front/in the front
- in-front-of
- in front of
- in front of/ahead of
- in-full
- in full
- in-full-swing
- in full view of
- 河同水密,各不相瞒
- 河吞大
- 河唇
- 河图
- 河图之灵
- 河图洛书
- 河圖
- 河坝
- 河坝钓鱼——干扯
- 河坡沿儿
- 河埠
- 河堤
- 河堤决口
- 河堤溃破泛滥
- 河堤,堤堰
- 河塘
- 河外星系
- 河套
- 河女
- 河女之章
- 河姆渡遗址
- 河委
- 河宗
- 河尾
- 河山