王非


摘要:微博作为社交网络的典型应用,每天都有新的富含情感的新词涌现,面向微博短文本的情感新词发现研究成为自然语言处理领域一个新的研究热点。本文提出了一种基于重复串统计的方法抽取候选词串,使用广义后缀树抽取所有可能的候选词串。然后利用本文提出的相关统计特征:候选词串的互信息与邻接信息熵等对候选词串进行筛选,实现新词过滤。
关键词:微博;新词发现;新词过滤;后缀树
中图分类号:TP311
文献标识码:A
DOI: 10.3969/j.issn.1003-6970.2015.11.002
0 引言
微博的出现为自然语言处理提供了新的研究领域,并提供了大量新形式的评论文本,传统的文本分析大多着眼于提取新闻文献等格式规范的文本的核心内容及主题上,但对微博这种长度较短,情感强烈,话题单一的短文本,需要通过新的技术手段去了解其关注的内容和倾向。考虑到本论文意图从微博数据中进行新词识别,而微博数据本身口语化、事件新颖化的特点导致没有较为合适的训练语料能够支持统计模型的训练,故本论文采用基于重复串统计的方法抽取候选词串。由于候选子串集合中存在大量的非词垃圾串,本论文采用语言特征与统计特征相结合的方法实现对候选新词集合中的垃圾串过滤,检测新词。
1 相关工作
目前对于新词发现的研究主要分为基于规则与统计方法。基于规则方法其主要思想是根据新词的构词特征或外型特点建立规则库、专业词库或模式库,然后通过规则匹配发现新词。郑家恒等人使用构建规则以发现新词,用新词的构词知识建立新词识别的构词库,同时考虑到互联网用词特点构建了特殊构词规则库。统计方法一般通过抽取候选词串,计算其内部聚合度,在此基础上,寻找聚合度最大的字符串组合。Peng等完全采用了统计方法,将分词和新词发现统一考虑,使用融合了词汇特征和领域知识的CRF模型抽取新词。同时将发现的新词加入到词典中用于提升模型的识别效果。Liu等采用左右信息熵和对数似然比确定词语边界从而抽选候选新词。林白芳等基于词内部模式结合互信息、IWP(Independent Word Probability,独立成词概率)和位置成词概率等统计量提取新词。Li等学者利用词频、成词率等特征训练SVM模型,从分类角度考虑新词识别。
2 新词发现
本文中使用的数据集包含1000万条中文微博,它不是针对某一种或多种产品评论的集合,而是包含广告、个人评论、日常心情倾述、生活琐事记录等,是真实微博的一个缩影。且该数据集只包含微博内容,不含诸如作者、发布时间等信息。
本文对于新词的定义为:
(1)微博新词从词典参照的角度看,是指在1千万条微博中出现且有一定的使用频次、未在老词典中出现的具有基本词汇(老词典中的词)所没有的新形式、新词义或新用法的词语。
(2)对只出现在微博用户名中的词即“@”之后的词,即使确系新词,考虑到无上下文环境支持从而给新词识别带来的困难,也不视为新词。
(3)不在老词典中且有新的词义的词(如“三儿”,“杯具”),标记为新词;在老词典中的词,即使有了一些新的含义(如“土豪”),也不算新词。
2.1 语料预处理
由于微博是一种极其活跃且口语化的语言,微博数据通常比较简短且含有较多的无关数据内容诸如用户名、转发等,所以对于新词的抽取我们只限定在微博内容上。首先对大规模语料集进行预处理,由于不考虑话题中和@用户名后存在的新词,故将微博中的标点符号、#话题#、@用户名、转发//等去除。然后去除数据集中所有非汉字字符,并在原字符位置填补特殊分隔符。
数据集的数据格式为:
例:
预处理后的数据为:
例:感谢店主为大家送上温暖毛衣哦用城市生活联名卡会不会有什么给力优惠呢
2.2 提取候选词串
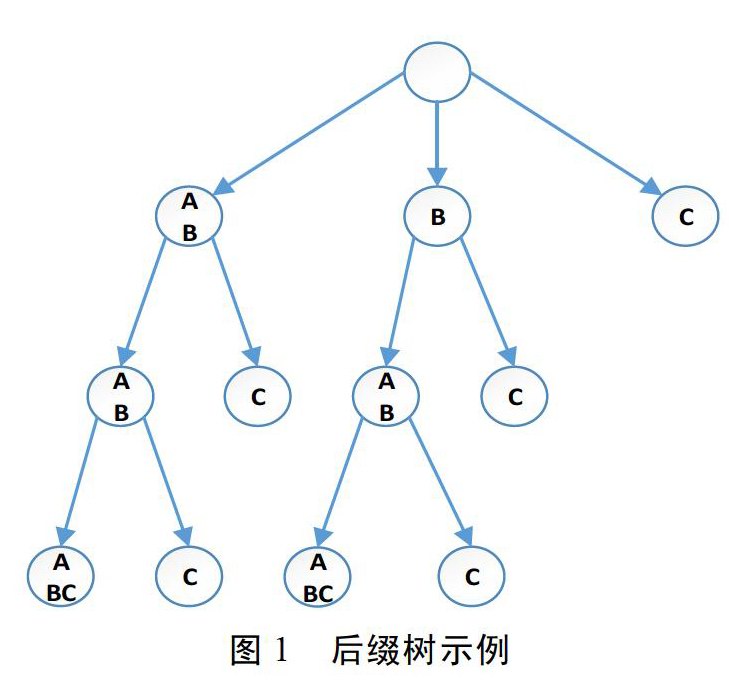
本文采用基于重复串统计的方法抽取候选字符串,并使用广义后缀树的数据结构存储微博,以便进行快速的字符串查找操作和相关字符串的统计。在介绍广义后缀树的构造方法前,首先给出后缀的定义。给定长度为n的字符串S=S1S2…Si…Sn$(1≤i≤n),$符号表达字符串的结束,子串S[i:n]=SiSi+1…Sn$称为字符串S的后缀,一般将空字符串$也算作后缀,S[i:n]即为起始位置为i的后缀。需要明确的是,后缀树是针对一个字符串构建的,而广义后缀树是针对一个字符串集合构造的。对于字符串集合T={T1,T2…,Tn}的广义后缀树,其本质是一个压缩字典树,包含了T中每一个字符串的所有后缀。
图l为字符串“ABABABC”的后缀树,图2为字符串集合{“ABCA”,“BCA”,“ABA”}的广义后缀树。
构建广义后缀树的第一个线性时间算法最早由Weiner于1973年提出,另外一个不同但空间效率更高的算法是由McCreight于1976年提出的。1995年,Ukkonen给出了一个概念上完全不同的线性时间构建算法,该算法不仅允许后缀树的在线构建,而且更容易理解。
构建后缀树的伪代码描述如下:
1.Update(新前缀)
2.{
3.当前后缀=激活节点
4.待加字符=新前缀最后一个字符
5.done=false:
6.while(!done){
7.if(当前后缀在显式节点结束){
8.if(当前节点后没有以待加字符开始的边)
9.在当前节点后创建一个新的叶节点
10.else
11.done= true:
12.} else {
13.if(当前隐式节点的下一个字符不是待加字符){
14.从隐式节点后分割此边
15.在分割处创建一个新的叶节点
16.else
17.done= true:
18.if(当前后缀是空后缀)
19.done=true:
20.else
21.当前后缀=下一个更短的后缀
22.}
23.激活节点=当前后缀
24.}
3 新词过滤
3.1 基于词频与词典的过滤
根据本文对新词的定义,从词典参照的角度看,新词是指在1千万条微博中出现且有一定的使用频次、未在老词典中出现的具有基本词汇(老词典中的词)所没有的新形式、新词义或新用法的词语。对于微博这类规模较大且内容具有集中性、引导性的数据,新词作为低频词出现的概率很小。故本文首先对候选新词进行基于词频的初步过滤,设定阈值,只保留词频大于阈值的候选字串。根于已有的老词典,再过滤掉在老词典中出现的词语,这些词语不被认为是新词。
3.2 基于统计特征的过滤
互信息(Mutual Information)在信息论中是作为衡量两个信号关联程度的一种尺度,后来引申为对两个随机变量间的关联程度进行统计描述。在本文的定义中互信息可以看作是已知字串W1的信息后对于字串W2的不确定性的减少量,即二者共同含有的信息量。
字串W1与W2的互信息定义为:
I(W1;W2)=log[P(W1,W2)/p(W1)p(W2)] (1)
P(S1,S2)为字串S1S2在语料中出现的概率,P(S1)、P(S2)分别为字串S1,S2在语料中出现的概率。互信息反映了相邻字串之间结合的紧密程度。当I(S1,S2)大于给定的阈值时,我们认为S1、S2以较高的可能性构成一个词语。
信息熵是信息论中用于度量信息量的一个概念,左右信息熵是指多字词表达的左边界的熵和右边界的熵。它用来判断候选新词W的左邻字符与右邻字符的不确定性,左右熵越大、不确定性越高,候选新词的左右搭配越丰富,即越可能成为新词。左右熵的定义如下:
4 结束语
对实验结果进行分析,会发现诸如“给我来一”这类词语,本身左熵满足阈值,由于右邻字符有“碗”、“个”等,所以所计算的右熵也会比较高,达到阈值,根据规则也会被误判为一个词语。同样的道理,诸如“了不少”这类词语,左熵也会比较高,所以也会误判为是一个词语。但为了更大程度上保留新词,阈值选取人为的调低。因此加入了前缀、后缀率这两个统计量对这种偏差进行校准。
本文针对大规模微博短文本提出了一种基于重复串统计的无监督方法抽取微博中出现的新词,并提出了一种语言规则与统计特征相结合的新词过滤方法来筛选候选新词。该方法能够用于更新已有老词典,提高中文分词的准确率,同时也可用于网络舆情分析与监控。
- 基于信息技术培养学生空间想象能力
- 初中语文教学中存在的问题和解决策略刍议
- 《动物游戏之谜》教学设计
- 高中信息技术教学中分组合作学习的应用探讨
- 信息技术与学科融合
- 小学数学低年级概念教学浅谈
- 新形势下幼儿园后勤精细化管理的探索与实践
- 小学班干部权力异化问题的分析与阐述
- 高中地理教学中如何培养学生的读图能力
- 激发学生学习数学的兴趣
- 谈谈如何在初中语文教学中培养学生的创新能力
- “数形结合”在小学低段数学教学中的应用
- 向着未来生长
- 运用现代信息技术优化数学课堂教学
- 探究对话教学在小学数学教学中的应用
- 关于高中信息技术教学中分组合作学习的探究
- 在初中汉语文教学渗透多元化教学策略的思考
- SPOC在实验教学中的应用
- 游戏教学法在小学数学教学中的应用
- 估算意识在小学数学教学中的培养
- 培养学生数据分析观念,提高学生数学素养
- 数形结合在二次函数学习中的应用例谈
- 微课在高中化学教学中的实践应用和思考
- 童话教学模式在小学语文教学中的运用
- 浅谈小学语文游戏化教学
- filamentoid
- filamentose
- filamentous
- filaments
- file
- fileable
- file cabinet
- filecabinet
- fileclerk
- file clerk
- filed
- file manager
- filemanager
- filer's
- filers
- files'
- files
- fileserver
- file server
- filet
- fileted
- fileting
- filetransfer
- file transfer
- filets
- 辚
- 辚轹
- 辚辚
- 辚辚作响的战车
- 辚辚火驭
- 辛
- 辛丑条约
- 辛亥广州起义
- 辛亥革命
- 辛伤
- 辛切
- 辛刻
- 辛劳
- 辛劳与奋战
- 辛劳之事
- 辛劳之状
- 辛劳勤苦
- 辛劳忙碌
- 辛劳操持
- 辛劳汗多
- 辛劳痛苦
- 辛劳的一生
- 辛劳费
- 辛劳,劳苦
- 辛勤