王倩 杨洋 单晴雯 施运梅
摘要:学生管理工作中积累了大量的学生信息,有效地利用这些信息将会给学生工作带来极大的便利与帮助。以北京某高校计算机学院学生的信息为基础,利用决策树算法对已有学生的信息进行分类研究,并通过实例验证其可行性,开启学生工作新模式。
关键词:学生信息;数据预处理;决策树;预测;学生工作
中图分类号:TP311.51 文献标识码:A 文章编号:1009-3044(2018)06-0217-03
教育领域积累了大量的学生信息,例如成绩、文体科技活动参加情况以及毕业发展状况等信息,这些信息直接反映了学生在校的学习状态、性格特点甚至发展方向。对学生信息的分析能够指导教学,引导学生工作者工作的展开,对学生的培养和发展起到一定的辅助作用。
目前,对学生数据的利用主要是对学生成绩的简单分析,例如:对学生成绩计算平均学分绩点,排名划分等级线;对修课学分进行统计分析。这类基础分析主要依赖分析人的经验,而缺乏一个客观的广泛的评价标准,在实际中发挥的效用有限。数据挖掘技术能从大量看似无联系的数据发现有用的信息。高等大专类院校学生信息中包含大量有用的信息,对学习成绩、文体科技类竞赛参加情况以及毕业后发展走向进行挖掘能得到许多对学生工作以及就业指导决策有价值的信息。
在对与此相关的项目进行调研分析之后总结出,对于学生信息的分析,文献[1-3]只是停留在对学生信息某一方面的具体分析,没有对学生信息进行总体整合分析,这就有可能导致分析的不够全面对未来发展预测的不准确,并且在预测之后没有对预测的准确率进行估计,这种分析的方法不能确定预测的稳定性与准确性。
本项目将对北京某高校计算机学院学生的各项信息进行整合分析,从一个较为完整的角度通过学生的在校信息对学生未来的发展方向做以预测[5][6],并且对预测的准确率进行计算,以确保估计的可信度。下面将从学生信息收集与预处理、决策树的应用、结果分析以及结束语四部分来进行详细阐述。
1学生信息收集与预处理
本次研究以北京某高校计算机学院2016、2017届毕业生为主要分析对象,采集学生姓名、专业、学习成绩、就业单位以及是否参与过科研竞赛和社团等信息,该数据由学院毕业生指导教师、科研管理教师以及社团管理教师提供,从根本上保证了数据的准确性与可靠性。
收集到的数据大多是以Excel形式进行存储,这些表格在维度、标准上有较大的差异,因此需要对数据进行预处理:
1)数据清洗:通过填写缺失值,光滑噪声数据、删除重复数据、解决不一致性来“清理”数据;
2)数据转换:收集到的数据有一部分是和本项目是不相关,是冗余的,减少不相关数据对数据挖掘的影响是至关重要的。
3)数据规约:数据经过前面的步骤之后已经基本符合要求,但还需要经过规约对数据进行最后一步的规范,使数据量减少,让挖掘的工作量达到更高的效率。
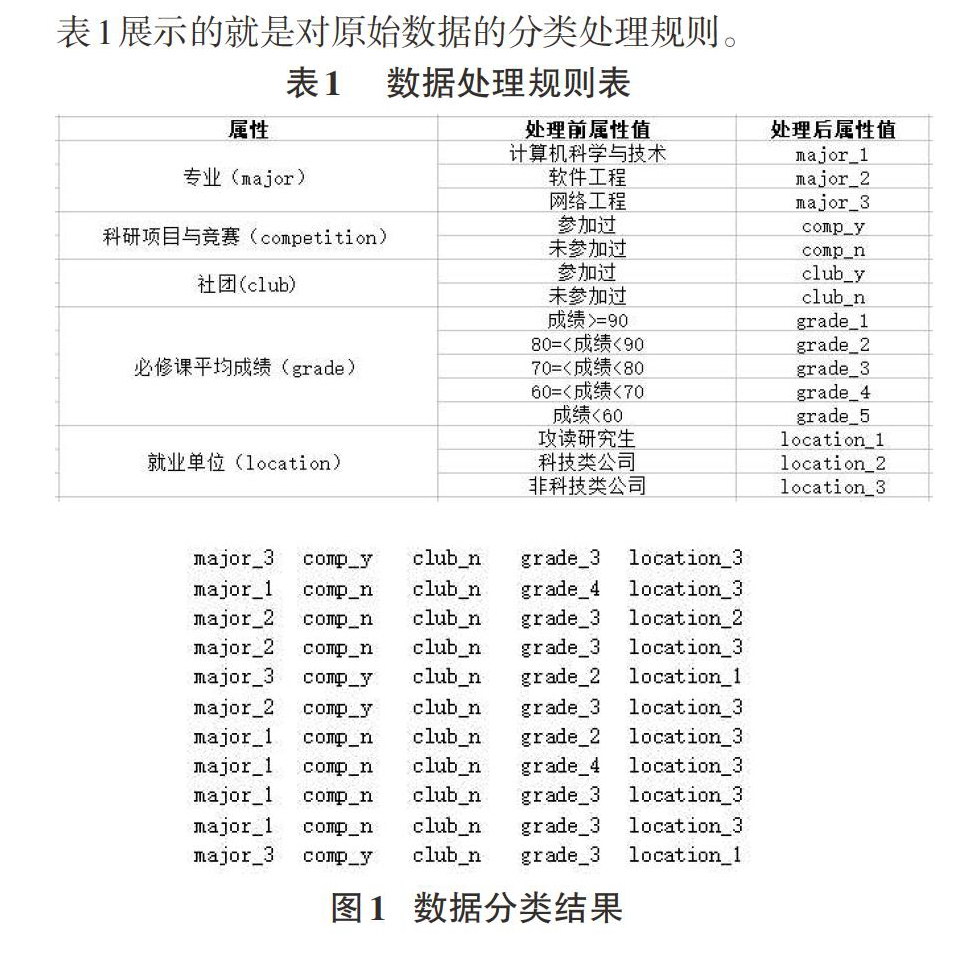
4)数据分类:数据的分类是为了算法能够更好地处理数据。学生的专业分为三种:计算机科学与技术、网络工程、软件工程,为了更为方便的表示,将计算机科学与技术设为1,软件工程设为2,网络工程设为3。成绩按照优秀、良好、中等、合格、不合格,对应为1、2、3、4、5五个等级。其他数据按照类似的方法进行整理。
按表1的处理规则对数据处理后,得到如图1所示的分类图:从左到右分别表示专业分类、竞赛、社团、必修课平均成绩、以及就业单位。
2决策树的应用
决策树算法是数据挖掘算法中一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。决策树的构造可以分为两部分,第一部分是构建决策树,即通过训练数据集产生符合实际需求的数据集,第二部分是通过对已经产生的决策树进行修剪的过程。主要是用训练数据集对决策树进行测试,将对预测结果平衡性的分枝减掉。
在本研究中决策树的应用主要思想是通过使用决策树算法对收集数据预处理后得到训练数据集进行分析建模,然后利用所见模型对未知数据进行预测。预测的好坏的衡量主要体现是预测的准确程度,因此在利用决策树实现分类预测功能的基础上,我们增加了获得预测准确率的方法,从而检验预测结果的准确程度。
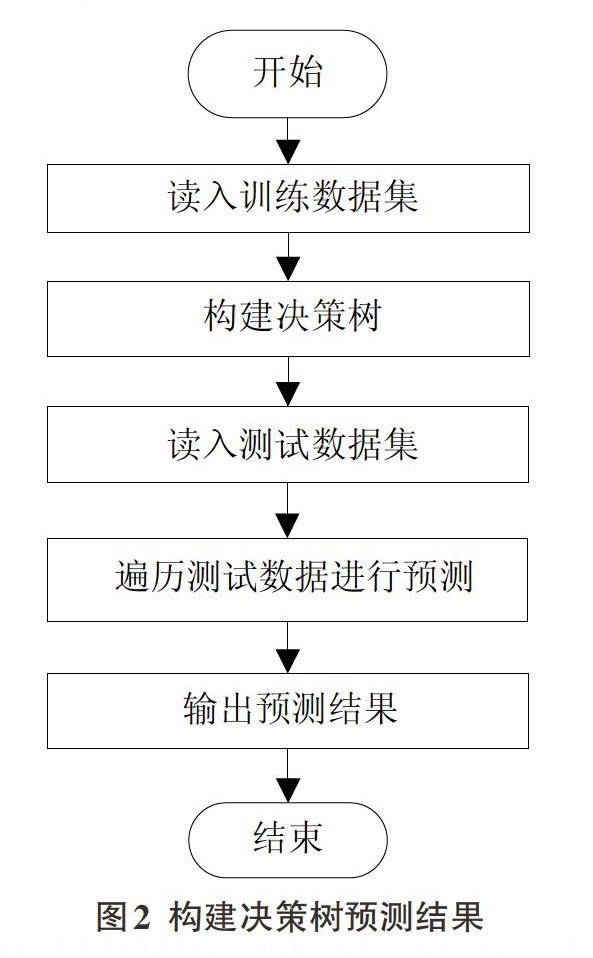
具体实现分为两个步骤,第一步是先将构建决策树的数据和预测数据导入并加载,调用weka jar包中的决策树算即i48算法形成决策树,然后会根据决策树的路径做出最优路径,遍历数据对数据进行预测,得到结果后将预测结果写到文件中,具体实现过程如图2所示:
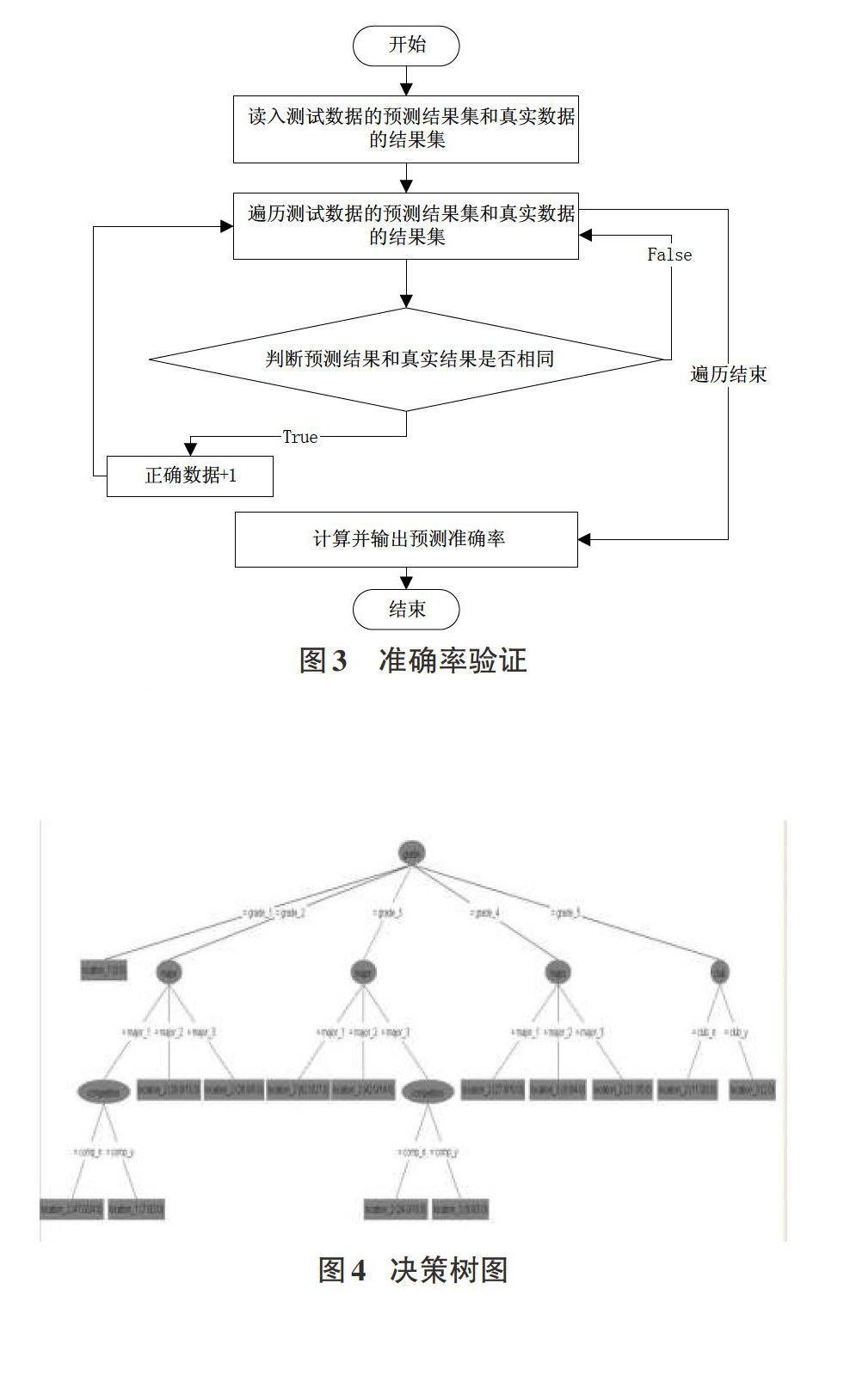
第二步是对决策树的准确率进行测试验证,从收集到的北京某高校计算机学院2016、2017届毕业生的数据即训练数据集中随机抽取部分数据作为测试数据,将构建决策树和测试数据导入并加载。通过i48算法构建好决策树,来预测测试数据结果,将测试数据结果和真实结果进行对比,统计预测结果准确数据个数和测试数据总个数,来得到准确率。具体实现过程如图3所示:
3结果分析
经过对预处理的数据决策树算法分析之后,得到如圖4的数据决策树,由此图可得出以下分类规则:
1)成绩>90的同学,将会选择攻读研究生;
2)成绩在80-90的同学,专业在计算机科学与技术且未参加竞赛的同学会选择科技类公司,参加竞赛的同学会选择攻读研究生而专业在软工和网工的同学则将会选择在科技类公司工作;
3)成绩在70-80的同学,专业在网工的同学且未参加过竞赛的同学会选择科技类公司作为发展方向,参加过竞赛的同学将会选择非科技类公司,而计算机科学与技术和软件工程的同学则更倾向于选择科技类公司。
4)成绩在60-70的同学,专业在计算机科学与技术和网络工程的同学会选择科技类公司,软件工程的同学会选择非科技类公司。
5)成绩在60以下的同学,参加过社团的同学会选择非科技类公司,未参加过社团的同学会选择科技类公司。
根据训练数据集中学生三种工作类型location_l:location_2:10cation3=51:82:199的比例随机选取测试数据集26条(如图4测试数据),使用上述方法,得到预测结果(如图5),最后一列即为预测的学生工作类型。将得到的预测数据结果(如图5)与真实数据(如图6)进行准确率的对比,准确率达到0.846,证明本研究具有较高的准确率和可信任度。
4结束语
本研究利用数据挖掘技术中的决策树算法对学生信息分析之后进而得到决策树模型,通过对模型得到的分类规则,实现帮助学工老师指导学生就业的同时,也帮助学生就业时对自己有一个较为准确的定位,帮助学校和学生树立责任意识和危机意识,实现各方努力,提高毕业生的实际就业问题。通过实践验证,本研究对学生就业具有一定的指导意义和实用价值,具有较高的准确率和可信任度,但由于目前收集到的数据有限,数据分布不均衡,使得结果预测仍有误差,提高结果预测的准确性将是笔者接下来的研究重点。笔者将收集更多样化的数据集,实践更多数据挖掘的分析算法,使研究成果更加具有实用性的价值。
- 园林工程设计与施工课改思考与探索
- 面向新经济的高职工科专业改造与人才培养探索
- 机械电子教学改革路径探索
- 发电厂及电力系统专业实训问题探索与研究
- 基于光机电一体化综合项目化实训教学探索
- 成本会计教学资源库建设的探索
- 高职物流信息技术专业建设的思考与探索
- 基于工作过程的高职学前教育专业项目化课程改革探索
- 艺术类大学生学习适应初探
- 高职院校流行体育选项课中实施分层教学的探索
- 高职《分析化学》教学中“问题教学”的探索
- 改进高职生物化学实验课教学的探索
- 泛在学习视域下高职数学移动学习资源的开发
- 中职数学生命化课堂的探索
- 高职院校“课程思政”改革的探索研究
- 慕课背景下现当代文学赏析的教学模式改革初探
- 塑造继续教育品牌核心价值路径研究
- 以世界技能大赛引领高职教学改革的研究
- 以德国为例探索职业教育发展优势
- 中、高职教育有效衔接运营机制构建研究
- 初探如何加快榆林职院职业教育发展
- 大学生体质健康现状及影响因素分析
- 二胎政策下女职工权益保护问题研究
- 刑事技术专业的现场勘查课程群的教学及实验实训体系研究
- 探究质谱仪模型在考查学生物理能力上的作用
- put your foot in it
- put your hand in your pocket
- put your hands together
- put your hand up
- put your heads together
- put yourself in sb's place
- put yourself out
- put yourself/sb forward
- reciprocity
- recircled
- recircles
- recircling
- recirculated
- recirculates
- recirculating
- recirculation's
- recirculations
- recitable
- recital
- recitalist
- recitalists
- recitalists'
- recitals
- recitals'
- recitation
- 信鸟
- 信鸥
- 信鸽
- 信鸽社
- 信鸽通讯
- 信鸿
- 信鼓
- 信,国之宝也
- 俢甬
- 俣
- 俣俣
- 俥
- 俦
- 俦与
- 俦丽
- 俦亚
- 俦人
- 俦伍
- 俦伦
- 俦伴
- 俦侣
- 俦党侪类
- 俦列
- 俦匹
- 俦类