摘 要: 多表关联查询是进行数据挖掘与分析的有效技术手段。随着大数据时代的到来,当前的数据分析技术在进行海量数据多表联查操作时存在明显的性能瓶颈,为此提出一种基于MapReduce计算模型的多表联查算法UGS用以提升多表关联查询效率。实验表明,在海量数据背景下,该算法的查询效率明显优于大数据领域的SparkSQL,Hive及关系型数据库的MySQL。
关键词: MapReduce; 多表联查; 关联空间剪枝; Spark
中图分类号: TN911?34 文献标识码: A 文章编号: 1004?373X(2015)14?0081?04
在当今的生产生活中,围绕着每个人每件事都会产生大量的数据,而这些数据往往是分布在不同的数据文件中,想对这些数据进行处理分析就必然要用到多表联合查询,联合查询在实际的生产生活中非常有必要。当前的多表联合查询主要通过两种方式实现:一种是基于传统数据库的表JOIN方式,这种方式存在数据规模瓶颈问题,无法支撑大规模数据关联;另一种是基于大数据技术的多源数据融合[1]方式,虽然能够解决关联查询在数据规模方面的瓶颈问题,但在运行效率方面存在较大的优化空间,目前难以满足交互式查询需求。因此,针对当前多表关联查询领域存在的问题,本文提出了一种基于MapReduce计算模型[2]的新型多表联查方法;实验表明,在解决多表关联数据规模瓶颈的基础上,较当前大数据领域的多表关联模式能够显著提升运行效率。
1 相关工作介绍
当前多表关联查询主要借助2种方式实现:关系型数据库方式和分布式并行计算方式。下面通过一个关联查询实例对2种实现方式进行复杂性分析。假设2张待联查的表table1和table2,其中table1的数据量为C1条,table2的数据量为C2条。要求输出table1.Key =table2.Key的条件下2张表的所有行,即:“SELECT * FROM table1 INNER JOIN table2 ON table1.Key=table2.Key”。
1.1 关系型数据库的实现
传统关系型数据库的多表关联查询采用基于关联条件的集合相乘思路实现[3],针对table1的每行数据,在table2中对其关键字(Key)进行查找,如果找到满足条件的数据,那么把它们组合成一条新数据存储到结果数据集中。此时数据库需要处理的条数为C1C2,也就是说时间复杂度为O(C1C2)。在此模式下,两表规模均为10万条数据时其响应时间已经达到5 min以上,两表规模达到百万条时,运行2 h仍未得到结果。
1.2 分布式处理引擎的实现
分布式并行计算实现方式主要基于大数据技术体系中的MapReduce模式展开,目前方法主要有Hive[4],Spark[5]两种方式。
1.2.1 MapReduce编程模型概述
MapReduce编程模型以(Key,Value)元组为基本单位展开数据处理,整个处理过程分为Map、Reduce两个阶段:Map阶段处理输入数据并将处理结果基于Key值通过哈希计算映射到Reduce处理节点;Reduce阶段处理本地数据并输出结果。由于相同Key值的哈希计算结果是确定的,因此,每个Reduce处理节点上完整保存了该key值的所有数据,编程人员在只需在每个Reduce节点处理本地数据即可完成对全局数据的处理。
1.2.2 分布式处理引擎执行多表联查
Hive提供SQL查询接口,通过对用户输入的查询任务进行语法树解析,将SQL查询转化成Hadoop的MapReduce任务集,基于MapReduce展开数据处理[6],由于MapReduce存在中间数据磁盘读写瓶颈,从而在很大程度上限制了Hive的执行效率。Spark分析引擎针对Hadoop的MapReduce中间数据磁盘读写瓶颈基于内存计算展开优化,使得同样功能的任务在大部分情况下比Hadoop执行效率更优,Spark在执行多表关联查询时采用优化的笛卡尔积关联算法,虽然性能较传统的笛卡尔积有所优化,但是复杂度依旧为笛卡尔积的O(C1C2),并且空间复杂度为O(C1C2)。Hive在进行数据关联查询时,单作业单机数据规模超过2 000 000×10 000 000时,执行时间在1 min以上,存在较大的优化空间;Spark对Hive的执行过程进行了基于内存的执行效率优化,但关联计算过程存在内存占用不可控的问题,当单作业单机数据规模超过20 000 000[×]100 000 000时,会因内存溢出导致关联查询无法完成,数据规模相对较小时也存在一定的运行效率优化空间。
因此需要设计一种空间膨胀相对可控,并且时间复杂度更低的算法来提高海量数据多表关联效率,从而提升海量分析能力。
2 算法的设计与实现
2.1 算法思路
本算法主要借助MapReduce计算模型展开,在Map阶段,对各表记录添加来源标记,并将各表数据采用相同的散列算法进行映射分发,使各表相同的Key值被集中到相同的处理节点上;在Reduce阶段,基于各表标记进行关联结果筛选,本地化获取关联查询结果集。算法介绍如下:
算法名:UGS(Union Group and Segmentation)算法。
输入参数:参与关联查询的表路径及关联条件集,关联查询结果输出路径。
输出数据:关联查询结果。
执行步骤:在上述实例中,算法在集群上的执行过程如下:
(1) 在Map阶段通过数据格式变换,将参与关联查询的各表数据统一为相同格式。将联合查询条件中的Key单独抽取出来,其他数据存放在OtherRecord中,并添加标记以记录来源的TableID,Map阶段输出为 (Key,TableID,OtherRecord)。
(2) 在Reduce阶段,输入Map阶段的输出结果,对Key值相同的记录进行关联筛选,如果某个Key存在于所有表中,那么是1条或多条(可能存在1个Key在某一table下存在多行)有效的结果。并将结果按表格式处理后输出。
算法首先需要遍历数据,对每条数据通过Key计算出Reduce标识,Reduce端完成数据收集后,在每个Reduce内通过排序将Key相同的记录整合在一起然后进行检索条件的完备性判断。在这种计算模式下,假设有N张表参与联查,第i张表的数据量为[Ci],共有M个Map和R个Reduce参与并发计算。令[Sum= 1NCi],那么算法的期望时间复杂度为[O(SumM+SumR×log2SumR)],空间复杂度为O(Sum)。如在两表联查下,时间复杂度为[OC1+C2M+C1+C2R×log2C1+C2R],空间复杂度为O(C1+C2)。在最坏情况下,即多张表内的Key列所有数据只有一个相同的值X,那么此方法的结果会退化为笛卡尔积结果,时间复杂度会退化到[O(1NCi)]。但是,在实际条件下很难有这种情况发生,并且如果关键字完全相同,那么结果数据集的数据量为[1NCi]条,此次联查不论在任何方法下复杂度都不会小于[O(1NCi)]。可以看到,由于复杂度数量级不同,在表规模较大,并且关键字离散的条件下,本算法的执行时间相较于笛卡尔积优化算法会大幅缩短,并且很好地解决了空间膨胀问题。
2.2 基于Spark的算法实现
本文基于大数据分析引擎Spark展开算法实现,首先介绍Spark相关的几个概念和操作:
SparkContext:Spark程序的入口,可以在声明时定义各种系统参数,如集群主节点位置,单个任务使用的最大内存量,需要核心数等等。
RDD(Resilient Distributed Datasets):弹性分布式数据集,它是Spark系统提供的一种分布式内存抽象,可以支持基于工作集的应用,同时具有数据流模型自动容错,位置感知调度和可伸缩性的特点。它允许用户在执行任务时显示的将工作集缓存在内存中,后续的操作能够重用工作集,极大地提升了执行速度。
TextFile:读取本地或者分布式文件系统的数据并生成RDD。使用方法为RDD=sparkContext.textFile(FilePath)。其中FilePath为字符串类型,可以为本地文件路径或者hdfs路径。
union:将相同格式的两个RDD合并为一个,使用方式为RDD.union(OtherRDD)。
GroupByKey:是将数据按Key排序,并将相同Key的所有其他数据合并为一个List。使用方式为RDD.GroupByKey()。
算法实现如下:
输入:结果输出路径OutputPath,多张表详细信,每张表以(表路径,关键字列的列号)二元组形式描述。
输出:以文件形式返回分布式文件系统。
实现步骤:
(1) 读取数据并将每张表的数据处理为统一格式。使用Spark调用hdfs数据的系统接口TextFile从分布式文件系统中读取数据,对于每张表所对应的文件,生成文件的惟一标识(TableID)并添加到文件的每行数据之内,再通过Map操作处理为固定格式的数据,即RDD(String, (String, String)),存储的数据为(Key, (TableID, OtherRecord))。
(2) 将多张表的数据合并到一起。由于经过步骤(1)处理后数据格式相同,可以使用RDD的union操作来进行合并,这样合并后的数据可以使用Spark本身提供的方法GroupByKey来对数据进行处理。
(3) 使用GroupByKey将关键字相同的数据合并为一条记录。即将Key相同的数据行中的(TableID,Record)放在一个List下。
(4) 检索数据,剔除不满足条件的数据。对步骤(3)执行过GroupByKey操作的数据,对每一行数据根据用户需求的连接方式进行数据的整理删除,如INNER JOIN就是对每一个Key判断该Key对应的数据是否包含所有表的内容,如果是则是满足条件的结果,如果缺少某张表的数据,那么便不满足要求,对其进行删除操作。而LEFT JOIN和RIGHT JOIN等则只要存在指定表的数据就会被保留下来。
(5) 将符合条件的数据拆分还原。由于某些表中,相同的Key可能存在多条数据与之对应,需要将这种数据还原、补全成多条。如在在学校学生的数据库中,同一姓名“A”可能对应着多个学生,这样在与其他表进行以姓名为关键字的联查时,“A”的结果数据应该为多行,而由于GroupByKey操作会将这些数据化为1行,所以需要进行拆分,将之还原为多行“A”。而在实现上,对每行数据生成若干的ArrayBuffer,然后将这些ArrayBuffer进行全乘就可以获得拆分后的结果。
(6) 将最终数据存入文件系统中。
3 对比实验
实验环境:
集群硬件:5台实验机组成的集群环境,其中主节点拥有4核心16 GB内存,4台从节点拥有4核心4 GB内存,每个核心拥有3.4 GHz的主频。
软件部署:操作系统为Ubuntu 12.04;MySQL为MySQL Ver14.14 Distrib 5.5.29;Hadoop集群为Hadoop?2.2.0;Spark集群为Spark?1.1.0;Hive为0.12;Scala为2.10.4。
实验方案:本算法需要与现有的关系型数据库、传统分布式文件系统处理方案进行横向对比,在关系型数据库可接受的数据范围内,做出数据量从小到大的对比实验;并在数据规模较大的前提下,与SPARKJOIN[7]和Hive进行对比实验。
与关系型数据库对比实验:设计5组不同的数据规模的数据,每组数据由2张表构成。其中关系型数据库使用INNER JOIN命令进行查找。由于联查需要生成2个表条数相乘的中间数据集,所以在规模分别为10万条与100万条数据的两表进行联查时,会生成[1011]规模的数据,并在1 h内无法返回结果。故5组联查数据数据量分别为(1 000[×]1 000),(1 000[×]10 000),(10 000[×]10 000),(10 000×100 000),(100 000×100 000)。
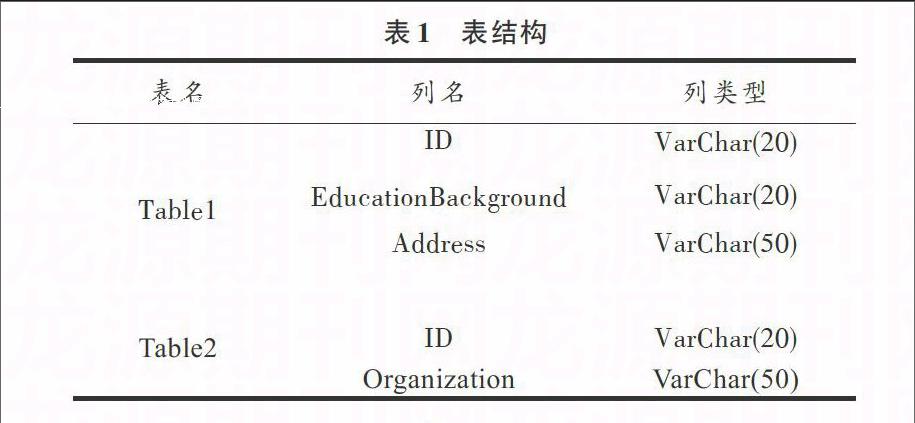
与传统分布式文件系统处理方案的比较:由于数据分发、I/O等条件的限制,分布式文件系统处理数据有一定的数据传递时间,所以在小规模数据处理方面,数据分析时间占比较少,所以需要在一定规模的数据下进行横向对比。因此设计5组数据进行对比实验。联查数据规模分别为(104[×]104),(105[×]105), (106[×]106),(106[×]107),(107[×]107)。2张表的格式如表1所示,其中待联查列均是ID列。
表1 表结构
3.1 UGS算法与常用关系型数据库比较
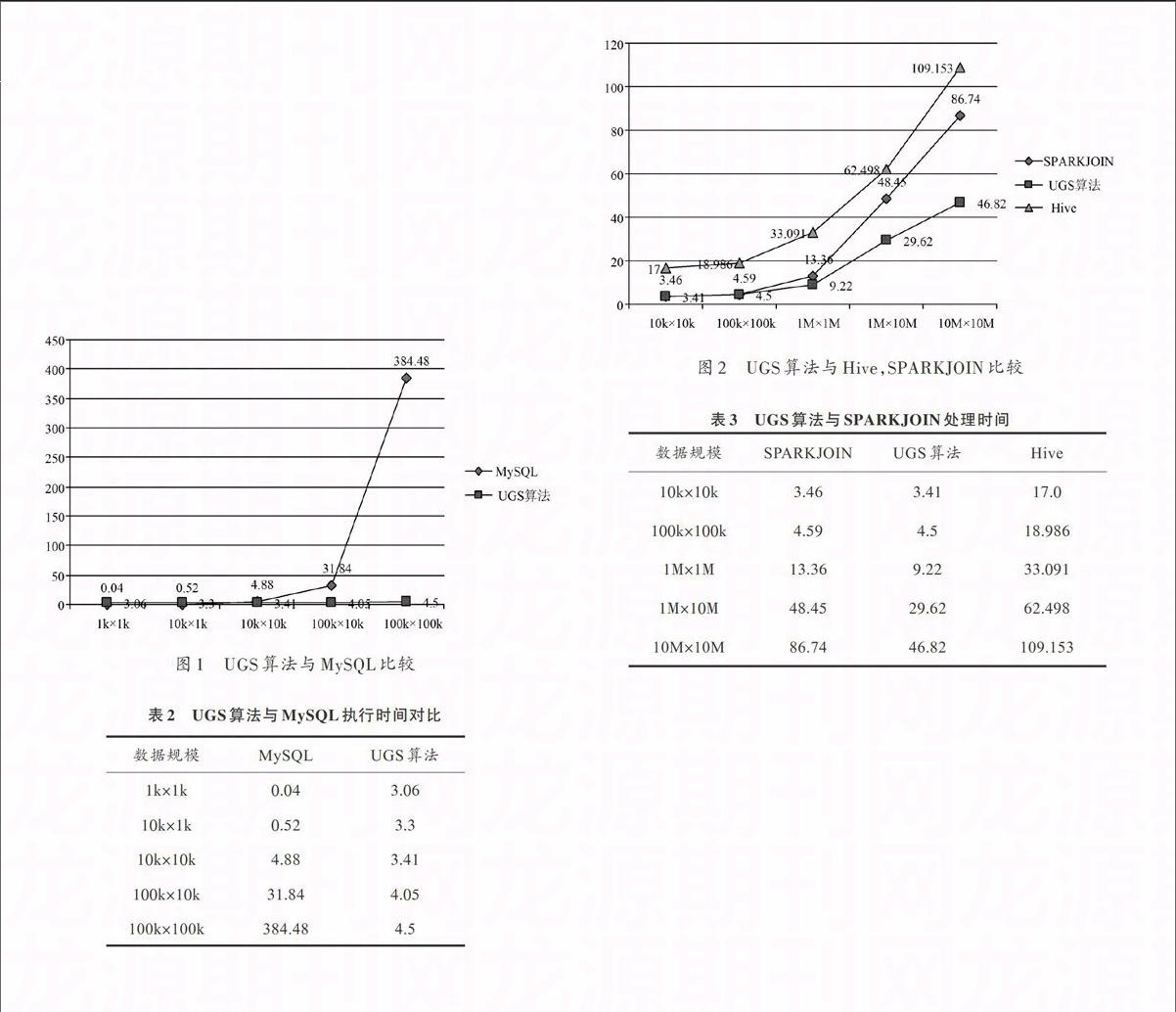
UGS算法与MySQL比较如图1所示。表2为UGS算法与MySQL执行时间对比。
可以看到,由于磁盘I/O、网络I/O、任务划分、数据分发收集需要占用一定时间,故在数据量较少的情况下,传统的关系型数据库仍有着较大的优势,但是在数据量增大时,中间数据集每增大10倍,关系型数据库所需处理时间都会增大约10倍,在对一张100 000条记录的表与1 000 000条记录的表进行联查时,MySQL运行了1 h仍未返回结果。而本文的UGS算法在数据量较小时,虽然也需要进行几秒的查询,但是增长稳定,在2张100 000条与100 000条的表进行联查时,效率比MySQL提升了将近100倍,在数据量继续增长的条件下,将会有着更大地提升。
图1 UGS算法与MySQL比较
表2 UGS算法与MySQL执行时间对比
3.2 UGS算法与其他大数据平台实现的比较
UGS算法与Hive,SPARKJOIN比较如图2所示。而对于传统的大数据方案,SPARKJOIN相对于Hive优化了任务分发收集等步骤,所以效率相差稳定为10~20 s之间,而UGS算法相对SPARKJOIN和Hive来讲,由于算法复杂度的优化,所以随着数据规模增大,处理效率相较于Hive和SPARKJOIN有着较大地提升。
3.3 UGS算法在多表联查下与当前大数据实现方案的比较
对于多表联查而言,由于UGS算法本身的复杂度为[O(SumM+SumR×log2SumR)],导致添加一张表所需的时间开销较少;而当前的大数据实现方案中,复杂度为[O(1NCiR)],每添加一张表复杂度都会提升一个数量级。所以在多表联查下,UGS算法相较于当前大数据实现方案优势更加明显。
图2 UGS算法与Hive,SPARKJOIN比较
表3 UGS算法与SPARKJOIN处理时间
对于3张数据规模均为1 000万条的表,以相同的Key列进行联查,SparkJoin使用了182.170 s得出结果,Hive使用了207.281 s获取结果,而UGS算法仅仅需要56.494 s就可以得出结果,可以看到由于增加表之后增加了任务的并发程度,并且更好的数据本地化降低了系统I/O开销,导致了处理时间相对于2张表联查增加了仅10 s。实验表明,在多表联查(表数大于等于3)的条件下,UGS算法相对于当前的大数据解决方案效率提升更高。
4 结 语
本文提出了一种基于MapReduce的多表联查算法用于实现海量多源数据的快速关联查询。实验表明,在数据量为10万条与100万条的两表联查中,UGS算法相较于传统关系型数据库有着7~8倍的提升,在每张表数据量均为100万条的两表联查中,相较于关系型数据库有着100倍的性能提升,随着数据量提升UGS算法的优势有着更明显的体现。
在基于大数据技术的实现方案比较中,当参与关联的单表数据规模达到1 000万级时,UGS相对于SPARKJOIN性能提升了约1倍,相对于Hive提升了1倍有余,并且随着数据规模增大、待联查表数量增多性能提升将更为明显。
参考资料
[1] WHITE T. Hadoop: the definitive guide [M]. 3rd ed. BeiJing: OReilly Media, 2013.
[2] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters [J]. Communications of the ACM: 50th Anniversary Issue, 2008, 51(1): 107?113.
[3] VARDI M. The complexity of relational query languages [C]// Proceedings of the fourteenth annual ACM symposium on Theory of computing. USA: ACM, 1982: 137?146.
[4] THUSOO A, SARMA J S, JAIN N, et al. Hive: a warehousing solution over a map?reduce framework [J]. Proceedings of the VLDB Endowment, 2009, 2(2): 1626?1629.
[5] ZAHARIA M, CHOWDHURY M, DAS T, et al. Resilient distributed datasets: A fault?tolerant abstraction for in?memory cluster computing [C]// Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation. [S.l.]: USENIX Association, 2012: 2?12.
[6] YANG H, DASDAN A, HSIAO R L, et al. Map?reduce?merge: simplified relational data processing on large clusters [C]// Proceedings of the ACM SIGMOD International Conference on Management of Data. New York: ACM, 2007: 1029?1040.
[7] LUO Yi, WANG Wei, LIN Xuemin. Spark: A keyword search engine on relational databases [C]// Proceedings of 2013 IEEE 29th International Conference on Data Engineering (ICDE). [S.l.]: IEEE, 2008: 1111?1118.
[8] CYGANIAK R. A relational algebra for SPARQL, HPL?2005?170 [D]. Bristol: Digital Media Systems Laboratory, 2005.
- “全等三角形”教案设计
- “光的折射”教案设计
- “‘1·3·3·4’课堂教学模式的理论与实践研究”课题方案
- Unit 2 How often do you exercise?
- 预防近视各国有妙招
- 近年中考英语单项选择题归纳总结
- 浅谈高中政治选修课程教材的开发
- 语文教学中新教师课堂导入设计存在的问题
- 校本教材在高中德育实践中的尝试体验
- “偷听”艺术运用的范例
- 青春期那些事儿(二)
- 珍视教育生活的每一天
- 当老师真好
- 浅谈话题作文的审题策略
- Unit 11 What time do you go to school?
- 《丰富多样的情绪》课堂实录
- 《Come and meet my family 》——Section B课堂实录
- “探究压力作用效果跟哪些因素有关”教学片段与反思
- “轴对称”教学设计
- 《子路、曾皙、冉有、公西华侍坐》教学纪实
- 《谈生命》教学纪实与反思
- 解密圆的移动
- 尺规作图三等分任意角(0°≤α≤180°)
- 谈化学试卷讲评课的教学
- 网络不良信息对我国未成年人成长的危害及对策
- activepartner
- actives
- active²
- active¹
- activism
- activist
- activists
- activities
- activity
- activity sampling
- activitysampling
- act of bankruptcy
- actofbankruptcy
- act-on
- act on behalf of sb/sth
- act on sth
- act on sth / act upon sth
- actor
- actor/actress
- actorish
- actorly
- actors
- actors'
- actorship
- actory
- 金黄鲜艳
- 金黛
- 金鼎
- 金鼓
- 金鼓喧天
- 金鼓声
- 金鼓振天
- 金鼓连天
- 金鼓震天
- 金鼓齐鸣
- 金鼙
- 金齑玉脍
- 金齑玉薤
- 金齑玉鲙
- 金齑雪脍
- 金齑雪鲙
- 金龙
- 金龙腾空
- 金龟
- 金龟婿
- 金龟子
- 金龟子的幼虫
- 金龟换酒
- 金龟换酒金鱼换酒
- 釓