语音情绪识别技术在载人航天领域的应用
刘洋 秦海波
【摘要】在航天飞行环境应激因素的影响下,航天员容易出现烦躁、焦虑、紧张、低警觉等情绪改变,这些改变会在语音中有所体现,通过语音情绪识别技术可以监测航天员的情绪变化。基于载人航天应用的实际需求,本研究建立了应激情绪语料库,并通过特征提取、高斯混合模型(GMM)方法搭建了语音情绪识别模型和软件平台,对该模型下语音情绪识别准确度进行了验证。
【关键词】语音 情绪 识别 载人航天 GMM
【中图分类号】R853 【文献标识码】A
【DOI】10.16619/j.cnki.rmltxsqy.2018.17.008
航天飞行环境中存在着诸如密闭、限制、超重、失重、高工作负荷、高风险和睡眠剥夺等应激因素,在这些因素的影响下,航天员容易出现烦躁、焦虑、紧张、低警觉等情绪改变,进而影响航天员的工作效率,甚至会危害其身心健康、导致操作失误,影响任务的顺利完成[1]。因此,人的因素已经被普遍认为是制约未来航空、航天飞行任务的重要因素,而应激情绪又是其中的关键。
言语作为人们交流的最主要方式,既包含语义信息内容,也包含了说话人的情绪、情绪状态,即言语表情。言语的语义、韵律等各层次都能反映个体内心的情绪状态。高工作负荷、紧急状态、噪声、振动、超重、失重等应激因素引起的烦躁、焦虑、紧张等应激情绪,也会在语音中有所体现。如果能够通过语音及时客观地监测航天员的情绪状态变化,地面心理支持人员就可以有针对性地给予航天员心理支持和疏导,从而降低负性情绪带来的不良影响。
本文对当前载人航天领域语音情绪识别的研究进展,基于高斯混合模型(GMM)方法搭建语音识别模型,以及该语音情绪识别准确度验证等进行了介绍。
语音情绪识别原理
人们的语音信息不仅包含了语义信息,同时也携带了情感信息,不同情绪下的语音信号特征参数存在差别。如一个人愤怒时,讲话的速率会变快、音量会变大、音调会升高等,此外已经研究验证语速、振幅、基频和共振峰等参数特征,均与情绪变化有关系。通过数据处理,将能够反映情感变化的语音参数从语音中提取并量化出来,构造这些参数与情绪分类的函数。
语音情绪识别分为两个步骤,一是模型的训练,通过对情绪分类已知的语音特征分析,提出有效的参数和权值,构造语音情绪数据的判别分类模型,常见的语音情绪识别方法有神经网络法、隐马尔可夫模型(Hidden Markov Model,HMM)法、高斯混合模型(Gaussian Mixture Model, GMM)法等。神经网络法是较早用于语音情绪识别中的一种方法,通过对基本情绪类别进行分析,得出了高兴等正面情绪和烦躁等负面情绪识别的难易程度,但识别率较低,平均识别率只有50%;HMM法由于采用短时时序特征,受到文本信息变化的影响较大,例如,共振峰是一种常用的语音情绪特征,但是受到音位信息影响严重;GMM法是近年来说话人识别和语种识别中比较成功的方法,能够拟合任意的概率密度函数分布,建模能力强,但其对训练数据依赖性较强。二是利用所建立分类器模型进行语音情绪识别。这个过程如图1所示。
载人航天环境下语音情绪识别研究进展
相比实验室环境,载人航天实践中存在着噪音和失重等因素的干扰[2],航天飞行下语音情绪识别需要对相应的因素进行研究。针对航天噪声,需要针对性涉及方法进行端点检测及降噪处理。载人航天器噪声主要来源为环控生保系统,噪声频带集中于200~500Hz、2000~2100Hz和3800~4100Hz三个窄带内。李皖玲等使用了对相应频带的噪声直接过滤,使用相邻频带的语音信息相关性对过滤掉的频带进行数据回填的方法,取得了很好的效果[3]。针对失重等因素,高慧等通过对72h心理隔绝及睡眠剥夺实验,密闭舱60d实验,以及头低位60d模拟失重实验的语音特征研究发现,在应激环境下,烦躁情绪与基频变化具有一致性,音节时长、短时能量的变化与时间节点有关[4]。高慧等采用基于Teager能量算子的非线性特征,运用HMM技术,对实验获取的平静—烦躁情绪平均识别率为98.6%[5]。
高斯混合模型
高斯混合模型(GMM)法是近年来说话人识别和语种识别中比较成功的方法,能够拟合任意的概率密度函数分布,建模能力强。GMM是M成员密度的加權和,可以用如下形式表示:
情绪语音数据库建立
人类声音中蕴含的情绪信息,受到无意识的心理状态变化的影响,以及社会文化习惯导致的有意识的控制。对自然语音情绪识别的研究不适合采用表演数据,需要通过诱发(Induced)的方式采集自然度较高的数据。

本项目采用计算机游戏进行情绪诱发,通过游戏中画面和音乐的视觉、听觉刺激,提供一个互动的、具有较强感染力的人机交互环境,能够有效诱发出被试的正面与负面情绪。特别是在游戏胜利时,被试由于在游戏虚拟场景中的成功与满足,被诱发出喜悦等正面情绪;在游戏失败时,被试在虚拟场景中受到挫折,容易引发烦躁等负面情绪;在游戏过程中,一些具有挑战性的游戏情节往往能引发被试的应激情绪。
在游戏前,让被试平静地读出指定的文本内容,录制平静状态的语音。在每次游戏失败后,要求被试说出指定的文本内容,录制负面应激情绪状态的语音。在游戏进行到一半时,暂停游戏,要求被试用说出指定的文本语句内容,录制语音。为了便于对数据进行检验,在每次录制情绪语音后,让被试填写情绪的主观体验,在实验结束后,根据被试的情绪主观体验表,剔除主观体验与诱发目标情绪不一致的语音数据,必要时进行适当的补录。为了保证所采集的情绪语料的可靠性,对采集的语音情绪数据进行了主观听辨与评选,每句样本由10名未参与录音的人员进行评测。
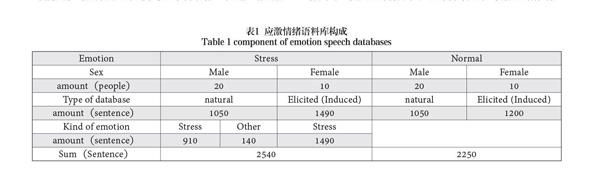
针对在长期载人航天环境以及其它类似的高强度特殊作业环境中面临的实际问题,选择了具有实际应用价值的语音情绪,采集了“烦躁”或“应激”情绪状态下的语音情绪数据,建立了一个中文的实用语音情绪数据库,即应激语料库。如表1所示。
语音特征提取、软件编制
通过文献和经验,我们采用了74个指标作为语音情绪研究的特征指标(feature),具体包括语句发音持续时间、语速等时间相关参数;平均振幅、最大振幅、基音相关参数、平均基音频率、最大基音频率、基音变化率等能量相关参数;第一共振峰均值、最大第一共振峰、第一共振峰变化率等共振峰相关参数[7]。
在Windows7与Microsoft Visual Studio 2008环境下,采用标准的C++语言编制软件,编制了用于情绪语音分析的基本函数库,包括了一部分常用的信号处理、矩阵计算、参数估计、概率统计、语音信号处理、文件输入输出等功能,软件具有单个语音文件的读入功能、批量识别、时域波形显示、频谱图显示、播放语音文件、长时段语料分割、模型训练、情绪识别等功能。
验证试验

为了保证程序模型的准确和实用性,验证试验材料采用了与模型建立不同的标准语料,分别从中文标准库(CASIA汉语情绪语料库)和德文标准库(Berlin Database of Emotional Speech)进行筛选,把情绪种类已知的应激语料与平静语料混合(4:1,总数100句),令识别模型自动检出平静和应激的语句数目,结果发现:应激和平静两种语料的识别率之和为100%。程序运行结果稳定,软件计算过程正确。
通过比对,该模型对德文标准库应激情绪的识别率为91%,中性情绪识别正确率为60%,总识别正确率为85%,总识别错误率为15%;对中文语料库的应激情绪识别率为86%,对中性情绪率为55%,总识别正确率为78%,总识别错误率为22%。
结语
在总结近年来国内外自动语音情绪识别研究的基础上,我们研究了针对非特定说话人、非特定文本的语音情绪识别算法,并且开发了基于高斯混合模型的语音情绪识别软件。语音情绪识别对于航天员情绪监测具有重要的意义,由于GMM存在对训练样本依赖性,在后续应用中可以通过对特定人语音样本的学习,提高实际应用的准确性。同时也可以考虑结合多模态的语音情绪识别,进一步提高准确率。
(本文系中国航天医学工程预先研究项目成果,项目编号:2014SY54A0001)
注释
[1] 秦海波、白延强、吴斌等:《载人航天飞行中的情绪研究进展》,《航天医学与医学工程》,2012年第25卷第4期,第302~306页。
[2] 高慧、周笃强、黄端生:《噪声对说话人语音的影响》,《航天医学与医学工程》,1999年第12卷第1期,第72~75页。
[3] 李皖玲、梁吴迪、张天湘:《基于隐马尔可夫模型的语音识别技术在载人航天器上的应用》,《航天器环境工程》,2013年第30卷第4期,第441~445页。
[4] 刘志刚、黄端生、郑素贤:《头低位卧床模拟失重对汉语语音特征的影响》,《航天医学与医学工程》,2000年第13卷第3期,第171~173页。
[5] 高慧、陈善广、安平等:《模拟航天环境下一种应激情绪的语音识别研究》,《航天医学与医学工程》,2010年第23卷第4期,第248~252页。
[6] 高慧、苏广川、陈善广:《不同情绪状態下汉语语音的声学特征分析》,《航天医学与医学工程》,2005年第18卷第5期,第350~354页。
[7] Sreenivasa Rao Krothapalli, Shashidhar G. Koolagudi, Emotion Recognitionusing Speech Features, Springer, 2013.
责 编/马冰莹
【摘要】在航天飞行环境应激因素的影响下,航天员容易出现烦躁、焦虑、紧张、低警觉等情绪改变,这些改变会在语音中有所体现,通过语音情绪识别技术可以监测航天员的情绪变化。基于载人航天应用的实际需求,本研究建立了应激情绪语料库,并通过特征提取、高斯混合模型(GMM)方法搭建了语音情绪识别模型和软件平台,对该模型下语音情绪识别准确度进行了验证。
【关键词】语音 情绪 识别 载人航天 GMM
【中图分类号】R853 【文献标识码】A
【DOI】10.16619/j.cnki.rmltxsqy.2018.17.008
航天飞行环境中存在着诸如密闭、限制、超重、失重、高工作负荷、高风险和睡眠剥夺等应激因素,在这些因素的影响下,航天员容易出现烦躁、焦虑、紧张、低警觉等情绪改变,进而影响航天员的工作效率,甚至会危害其身心健康、导致操作失误,影响任务的顺利完成[1]。因此,人的因素已经被普遍认为是制约未来航空、航天飞行任务的重要因素,而应激情绪又是其中的关键。
言语作为人们交流的最主要方式,既包含语义信息内容,也包含了说话人的情绪、情绪状态,即言语表情。言语的语义、韵律等各层次都能反映个体内心的情绪状态。高工作负荷、紧急状态、噪声、振动、超重、失重等应激因素引起的烦躁、焦虑、紧张等应激情绪,也会在语音中有所体现。如果能够通过语音及时客观地监测航天员的情绪状态变化,地面心理支持人员就可以有针对性地给予航天员心理支持和疏导,从而降低负性情绪带来的不良影响。
本文对当前载人航天领域语音情绪识别的研究进展,基于高斯混合模型(GMM)方法搭建语音识别模型,以及该语音情绪识别准确度验证等进行了介绍。
语音情绪识别原理
人们的语音信息不仅包含了语义信息,同时也携带了情感信息,不同情绪下的语音信号特征参数存在差别。如一个人愤怒时,讲话的速率会变快、音量会变大、音调会升高等,此外已经研究验证语速、振幅、基频和共振峰等参数特征,均与情绪变化有关系。通过数据处理,将能够反映情感变化的语音参数从语音中提取并量化出来,构造这些参数与情绪分类的函数。
语音情绪识别分为两个步骤,一是模型的训练,通过对情绪分类已知的语音特征分析,提出有效的参数和权值,构造语音情绪数据的判别分类模型,常见的语音情绪识别方法有神经网络法、隐马尔可夫模型(Hidden Markov Model,HMM)法、高斯混合模型(Gaussian Mixture Model, GMM)法等。神经网络法是较早用于语音情绪识别中的一种方法,通过对基本情绪类别进行分析,得出了高兴等正面情绪和烦躁等负面情绪识别的难易程度,但识别率较低,平均识别率只有50%;HMM法由于采用短时时序特征,受到文本信息变化的影响较大,例如,共振峰是一种常用的语音情绪特征,但是受到音位信息影响严重;GMM法是近年来说话人识别和语种识别中比较成功的方法,能够拟合任意的概率密度函数分布,建模能力强,但其对训练数据依赖性较强。二是利用所建立分类器模型进行语音情绪识别。这个过程如图1所示。
载人航天环境下语音情绪识别研究进展
相比实验室环境,载人航天实践中存在着噪音和失重等因素的干扰[2],航天飞行下语音情绪识别需要对相应的因素进行研究。针对航天噪声,需要针对性涉及方法进行端点检测及降噪处理。载人航天器噪声主要来源为环控生保系统,噪声频带集中于200~500Hz、2000~2100Hz和3800~4100Hz三个窄带内。李皖玲等使用了对相应频带的噪声直接过滤,使用相邻频带的语音信息相关性对过滤掉的频带进行数据回填的方法,取得了很好的效果[3]。针对失重等因素,高慧等通过对72h心理隔绝及睡眠剥夺实验,密闭舱60d实验,以及头低位60d模拟失重实验的语音特征研究发现,在应激环境下,烦躁情绪与基频变化具有一致性,音节时长、短时能量的变化与时间节点有关[4]。高慧等采用基于Teager能量算子的非线性特征,运用HMM技术,对实验获取的平静—烦躁情绪平均识别率为98.6%[5]。
高斯混合模型
高斯混合模型(GMM)法是近年来说话人识别和语种识别中比较成功的方法,能够拟合任意的概率密度函数分布,建模能力强。GMM是M成员密度的加權和,可以用如下形式表示:
情绪语音数据库建立
人类声音中蕴含的情绪信息,受到无意识的心理状态变化的影响,以及社会文化习惯导致的有意识的控制。对自然语音情绪识别的研究不适合采用表演数据,需要通过诱发(Induced)的方式采集自然度较高的数据。
本项目采用计算机游戏进行情绪诱发,通过游戏中画面和音乐的视觉、听觉刺激,提供一个互动的、具有较强感染力的人机交互环境,能够有效诱发出被试的正面与负面情绪。特别是在游戏胜利时,被试由于在游戏虚拟场景中的成功与满足,被诱发出喜悦等正面情绪;在游戏失败时,被试在虚拟场景中受到挫折,容易引发烦躁等负面情绪;在游戏过程中,一些具有挑战性的游戏情节往往能引发被试的应激情绪。
在游戏前,让被试平静地读出指定的文本内容,录制平静状态的语音。在每次游戏失败后,要求被试说出指定的文本内容,录制负面应激情绪状态的语音。在游戏进行到一半时,暂停游戏,要求被试用说出指定的文本语句内容,录制语音。为了便于对数据进行检验,在每次录制情绪语音后,让被试填写情绪的主观体验,在实验结束后,根据被试的情绪主观体验表,剔除主观体验与诱发目标情绪不一致的语音数据,必要时进行适当的补录。为了保证所采集的情绪语料的可靠性,对采集的语音情绪数据进行了主观听辨与评选,每句样本由10名未参与录音的人员进行评测。
针对在长期载人航天环境以及其它类似的高强度特殊作业环境中面临的实际问题,选择了具有实际应用价值的语音情绪,采集了“烦躁”或“应激”情绪状态下的语音情绪数据,建立了一个中文的实用语音情绪数据库,即应激语料库。如表1所示。
语音特征提取、软件编制
通过文献和经验,我们采用了74个指标作为语音情绪研究的特征指标(feature),具体包括语句发音持续时间、语速等时间相关参数;平均振幅、最大振幅、基音相关参数、平均基音频率、最大基音频率、基音变化率等能量相关参数;第一共振峰均值、最大第一共振峰、第一共振峰变化率等共振峰相关参数[7]。
在Windows7与Microsoft Visual Studio 2008环境下,采用标准的C++语言编制软件,编制了用于情绪语音分析的基本函数库,包括了一部分常用的信号处理、矩阵计算、参数估计、概率统计、语音信号处理、文件输入输出等功能,软件具有单个语音文件的读入功能、批量识别、时域波形显示、频谱图显示、播放语音文件、长时段语料分割、模型训练、情绪识别等功能。
验证试验
为了保证程序模型的准确和实用性,验证试验材料采用了与模型建立不同的标准语料,分别从中文标准库(CASIA汉语情绪语料库)和德文标准库(Berlin Database of Emotional Speech)进行筛选,把情绪种类已知的应激语料与平静语料混合(4:1,总数100句),令识别模型自动检出平静和应激的语句数目,结果发现:应激和平静两种语料的识别率之和为100%。程序运行结果稳定,软件计算过程正确。
通过比对,该模型对德文标准库应激情绪的识别率为91%,中性情绪识别正确率为60%,总识别正确率为85%,总识别错误率为15%;对中文语料库的应激情绪识别率为86%,对中性情绪率为55%,总识别正确率为78%,总识别错误率为22%。
结语
在总结近年来国内外自动语音情绪识别研究的基础上,我们研究了针对非特定说话人、非特定文本的语音情绪识别算法,并且开发了基于高斯混合模型的语音情绪识别软件。语音情绪识别对于航天员情绪监测具有重要的意义,由于GMM存在对训练样本依赖性,在后续应用中可以通过对特定人语音样本的学习,提高实际应用的准确性。同时也可以考虑结合多模态的语音情绪识别,进一步提高准确率。
(本文系中国航天医学工程预先研究项目成果,项目编号:2014SY54A0001)
注释
[1] 秦海波、白延强、吴斌等:《载人航天飞行中的情绪研究进展》,《航天医学与医学工程》,2012年第25卷第4期,第302~306页。
[2] 高慧、周笃强、黄端生:《噪声对说话人语音的影响》,《航天医学与医学工程》,1999年第12卷第1期,第72~75页。
[3] 李皖玲、梁吴迪、张天湘:《基于隐马尔可夫模型的语音识别技术在载人航天器上的应用》,《航天器环境工程》,2013年第30卷第4期,第441~445页。
[4] 刘志刚、黄端生、郑素贤:《头低位卧床模拟失重对汉语语音特征的影响》,《航天医学与医学工程》,2000年第13卷第3期,第171~173页。
[5] 高慧、陈善广、安平等:《模拟航天环境下一种应激情绪的语音识别研究》,《航天医学与医学工程》,2010年第23卷第4期,第248~252页。
[6] 高慧、苏广川、陈善广:《不同情绪状態下汉语语音的声学特征分析》,《航天医学与医学工程》,2005年第18卷第5期,第350~354页。
[7] Sreenivasa Rao Krothapalli, Shashidhar G. Koolagudi, Emotion Recognitionusing Speech Features, Springer, 2013.
责 编/马冰莹
