
摘要:数学主观题自动阅卷的主要思想是计算学生答案和试题标准答案的相似度,类似于机器翻译中通过计算机器生成的译文与参考译文的相似度来评价译文的质量。本文基于两者之间的相通之处,提出了一种基于机器翻译评分指标BLEU的数学主观题自动阅卷方法,在高二年级数学真实考题上进行实验,准确率达到88.11%。
关键词:数学主观题 自动阅卷 文本相似度 BLEU
中图分类号:TP301.6 文献标识码:A
0 引言
在中小学的教学中,考试是教师了解学生掌握课堂知识程度的重要手段,其中主观题是必出考题。但由于通常情况下考试人数众多、频次又高,教师的阅卷工作量非常大,并且教师的状态极易影响阅卷结果。因此,利用计算机技术尽可能高质量地实现主观题自动判分,可以缓解人力的消耗,减少判卷质量的不稳定性,提高教学效率。
主观题的主要思路是计算学生答案和标准答案之间的相似度。目前己有的文本相似度的计算方法是将文本分为短文本和长文本。长文本通常是文档级别,其相似度是利用TF-IDF和VSM等统计手段得到的。短文本多为句子级别,具备同语稀疏、语义离散等特点,多采用相同字符计算、语料库或者知识库、语言学等方法。也有研究者利用深度学习中的CNN或者LSTM来计算文本相似度。
数学主观题是一种比较特殊的文本,其长度介于长文本和短文本之间,数学符号居多,语句较为单调,文本歧义较少,需要根据题目的具体特征制定针对性的文本相似度计算方法。本文考虑到数学主观题自动阅卷与机器翻译的评分过程极为相似,利用机器翻译的自动评价指标BLEU(Bilingual EvaluationUnderstudy)得分对学生答案和教师的多个答案进行相似度计算,再辅以线性函数进行拟合,实现数学主观题自动阅卷。十折交叉验证方法的实验结果显示,BLEU自动阅卷结果与人工阅卷结果相比,完全相等的占49.5,偏差分值为1的占39.6%,偏差分值为2的占7.9%,偏差分值为3的占3.0%.考虑到实际阅卷中,各教师间的判定会有一定的分差,因此我们认为偏差分值不超过1的都为判分准确,达到准确率88.11%。
1 相关工作
主观题阅卷的关键是文本的相似度计算。长文本通常由多个段落组成,可以计算文本间共现的字符串。也可以利用TF-IDF方法或者隐性语义标引(LSI)将文本内容的向量化[1,2,3],然后采用编辑距离、汉明距离、欧式距离、Jaccard相似性、余弦或者曼哈顿距离等来度量相似度。文献[4]利用Hash方法进行了降维。短文本为诸如论坛留言、微博、聊天记录等短小文本。其相似度可以通过比较文本间的公共词汇[5];还有语料库[6.7]方法或知识库[8.9.10]方法,通过语料库或知识库中学习到的规则来计算相似度。语言学方法计算词汇间的语义关系以及句子的语法成分[11];深度学习方法利用词向量、卷积神经网络、长短时记忆(LSTM)或注意力模型计算文本相似度[12,13,14,15]。
主观题阅卷方法中,英语写作试题可以从句法多样性和用词能力等多个方面评判文笔好坏[16,17]也有研究者采用词汇一语义技术针对短文本答案自动阅卷[18],需要词典具有较大的词汇覆盖量。对答案进行语法分析和语义分析的方法需要引入同义词词典[19]。模板方法需要考虑所有可能出现的正确或错误答案[20]。高思丹等提出了动态规划的相似度计算方法[21]。张添一等利用知网的词汇语义相似度计算方法[22]。张均胜等[23]采用人工制定文本相似标准的统计方法。刘逸雪等[24]将人工标准中的关键短语与LSTM相结合,实现学生答案和教师答案之间的文本相似度计算。
与上述方法不同的是,本文借鉴机器翻译中的BLEU[25]得分的方法来计算参考答案和学生答案的相似度,以此生成得分。BLEU是双语互译质量评估辅助工具,用来评估机器翻译质量,其设计思想是将机器翻译的结果与其相对应的几个参考翻译作比较,算出一个综合分数。这个分数越高说明机器翻译得越好。而数学主观题常常也是学生进行答题给出学生的结果,每道题教师常常会给出多种解法,所以可以把学生的答题结果看作机器翻译的结果,每道题的多个解法看作多个参考翻译,这样就可以利用BLEU来衡量学生答案和教师答案的相似度,完成数学的主观题阅卷。
2 主观题阅卷方法
2.1 基于BLEU的文本相似度计算
数学主观题的自动判分可以归结为标准答案和学生答案之間的相似度计算问题。如果学生答案文本和试题标准答案文本相同,则相似度为1;如果考生答案和试题标准答案的文本完全不同,则相似度为0;两者之间相似度越高,则考生得分越高。
数学主观题经常存在多种解题思路。例如考察立体几何的主观题,可以使用综合分析法,也可以采用向量法。学生的知识储备和逻辑组织能力不同,又导致简洁的方法和绕远路的方法都可以是正确答案。为此在主观题阅卷时要考虑到多种标准答案的评分。评分过程实际上是对考生答案和教师答案进行相似度计算的过程。这里采用BLEU来进行相似度计算。
BLEU是机器翻译系统中翻译质量的自动评价指标,计算机器翻译结果和多个人工参考翻译结果之间的n元文法匹配准确度,并且给了长度惩罚。虽然在机器翻译领域人们质疑BLEU得分和人工翻译评价不一定一致,但是BLEU得分毕竟反映了机器翻译结果和人工翻译结果之间的匹配程度,所以一直作为机器翻译自动评价的一个公认的主要指标。BLEU得分计算如下:
其中,pn是改良的n-gram的精度得分,wn是正向权重,Cm候选译文与参照译文匹配的n-gram词数,C为候选译文中匹配的n-gram词数。针对翻译译文长度比参考译文要短的情况,需要一个惩罚的机制去控制,即B尸的引入。在公式(3)中,c为机器译文的长度,r为参考译文的长度。
在自动阅卷中,我们可以把学生答案当所翻译结果,标准答案当做标准翻译结果,计算两者之间 BLEU值作为两者之间的相似度。通常BLEU使用4元文法,为了避免得分为0的情况,在这里使用了4元文法。得到BLEU得分后,只需要拟合出其与老师得分之间的函数关系,就可以根据BLEU得分预测老师得分,达到自动阅卷的目的。
2.2 二次函数拟合
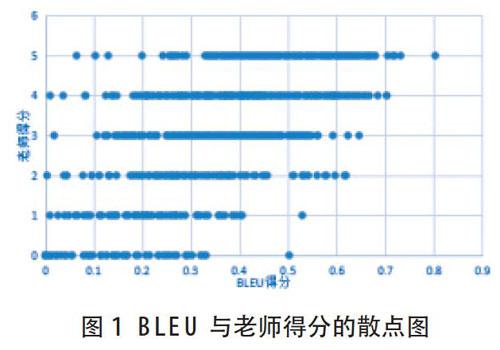
图1给出BLEU得分与老师实际得分之间散点图,可以发现BLEU得分与教师得分之间的关系很模糊。为了更好地拟合两者之间的关系,我们将对BLEU做公式(4)([x]表示对x做四舍五入处理)中的处理:
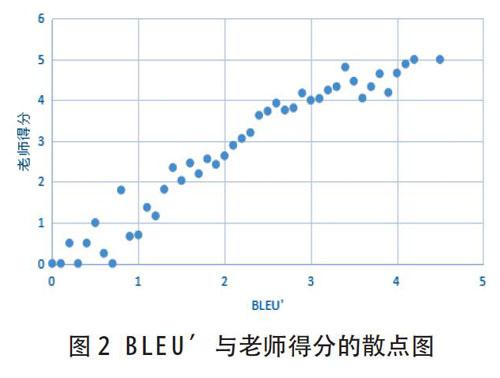
其中,如果在是十分位上四舍五入,只能得到6对数据,数据量太稀疏而不适合做拟合;在百分位和千分位四舍五入的预测结果不相上下,因此本文采用百分位上四舍五入的方法进行处理。图2给出BLEU与老师得分之间的关系。此时,两者之间的关系已经非常明了。
我们构建了二次函数来拟合BLEU'和老师得分之间的关系。由于老师得分多为整数,因此对拟合函数得到的预测值再取十分位上的四舍五入,作为最终的预测值。最后的计算方式如公式(5)所示。
老师得分预测=
其中α*为二次函数的系数。
3 实验与讨论
本文实验的目的是评价机器评分算法的性能,将机器评分结果与人工阅卷评分结果相比,评价机器评分结果的准确率。评价的指标是机器评分分值与人工阅卷分值之间的差距。评分分值偏差不大于1分,即认为评分结果准确。
实验数据同文献[16],为北京十一学校高二年级第二学期(2017年春季)期末数学考试的试题,其中的立体几何题目,共11小题。人工为每道题制定了多种解题思路和评分标准。
由于学生答题都是笔答,所以对考生答案采用文献[16]的线性规则进行了线性电子化。试题及教师答案的统计量,见表1。
将上述共1018个学生答案进行线性化处理,计算每道题的学生答案和其对应的多种解法的BLEU得分。
函数拟合采用了以Python为基础的Tensortlow,二次函数的拟合训练过程中使用的代价函数是最小二乘法,训练的轮数是1000轮。得到的计算结果见公式(6),拟合曲线,见图3。
老师得分预测
我们采用十折交叉验证法,按顺序每次取1/10的样本(101条)作为测试集,其他的BLEU得分-人工得分数据对作为训练集,进行函数的参数学习,根据学习到的参数和公式对测试集进行预测。最终取十份测试集阅卷结果的平均值用来衡量自动阅卷方法的有效性。结果,见表2。
评分结果显示,评分偏差不大于1的题目数量为89,占88.11%;而且没有出现偏差大于3的预测分数,说明BLEU得分可以很好地预测老师得分,而且偏差比较稳定。但是BLEU得分不能很好地抓取答案中的语义关系,只是一种显性相关性。这使得一些巧妙简洁的答案具有较低的BLEU得分,而冗长错误的答案有较高的BLEU得分,从而导致误判。因此,下一步可以考虑与语义相似度方法相结合,探索是否会达到互补的效果。
4 结束语
本文提出了一种基于BLEU的文本相似度计算方法用于数学主观题自动阅卷,并在11道高二年级数学期末考试的真实考题数据集上收集了1018道学生答案进行了实验,得分的准确率为88.11%。
本方法虽然没有用到语义信息,其中的四舍五入的方法也是启发式处理,但从最后的预测效果来看,还是很可观的。对于大批量考试阅卷工作来说,该方法大大减少了人工的工作量,因此具有较好的应用价值。在未来的研究工作中,可以再结合深度学习挖掘其中的语义信息和逻辑关系,在这样的基础上计算语义上的相似度。显性相似度和隐性相似度的融合可能会提升自动阅卷的准确率。
参考文献:
[1]L.Xu,D.Wang,and M.Huang,“Improved Sentence SimilarityAlgorithm based on VSM and itsapplication in Question AnsweringSystem.”Intelligent Computing andIntelligent Systems(ICIS),2010 IEEEInternational Conference on IEEE,2010,pp.368-371.
[2]孙宏纲,陆余良,劉金红,等.基于HowNet的VSM模型扩展在文本分类中的应用研究[J].中文信息学报,2007,21(G):101-108.
[3]Peter W.Foltz,W alter Kintsch,and Thomas K Landaue,“Themeasurement of textual coherencewith latent semantic analysis."Discourse Processes25.2-3(1998),pp.285-307.
[4]MosesS.C harikar.Sinilarity estimationtechniques from rounding algorithms.In STOC,pages 380-388,Montreal,Quebec,Canada,2002.
[5]刘宏哲.文本语义相似度计算方法研究[D].北京交通大学,2012
[6]Lin X,Wang D.Word semanticsimilarity research based on latentrelationships[C].InternationalSym posium on Instrumentation&Measurement,SensorNetwork andAutom atio n.2013:168-171.
[7]Islam A,Inkpen D.Sem antic textsin ilarity using corpus-based wordsimilarity and string similarity[J].ACM Transaction on KnowledgeDiscovery from Data,2008,2(2):1-25.[8]Xu LH,Sun S T,W angQ.Text sim ilarity algorithm basedon semantic vector space model[C]-Ieee/acis,International Conference onCompurer and Inform ation Science.IEEE,2016:1-4.
[9]Mihalcea R,Corley C,Strap parava C.Corpus-based and know ledge-basedmeasures of text sem antic similarity[C].Proceedings of the 21stN ationalC onference on Artificial Intelligence.Boston:AAAIPress,2006:775-780.
[10]刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002.
[11]李春梅,徐庆生.基于多特征的汉语句子相似度计算模型的研究[J].计算机技术与发展,2014(的:136-139.
[12]HuBaotian,Zhengdong Lu,HangLi,et al.C onvolutional neuralnetwork architectures for matchingnatural language sentences.Advancesin Neural Information ProcessingSystem s.2014.
[13]Wang Shuohang,and jing Jiang.Learning N atural Language Inferencewith LSTM.[C].Proceedings ofNAACL-HLT 2016,pages1442-1451.
[14]Ming Tan,Cicero dos Santos,X iangBingetc.Lstm-based deep learningmodelsfornon-facto id answerselection.[J].Computation and Language.
[15]Tim Rockt"aschel,EdwandGrefenstette,KarlMoritz Hermann,etc.R easoning about entaitn entw ithneuralattention[C].ICLR,2016.
[16]Rudner L,Gagne P.An overview ofthree approaches to scoring writtenessays by com puter[J].PracticalAssessn ent,R esearch&Evaluation,2001,7(26).
[17]Burstein J,Leacock C,Swartz R.Automated evaluation of essay andshort answers[C].Proceedings ofthe 5th International ComputerAssisted Assesm ent Conference.Loughborough:LoughboroughUniversity,2001.
[18]Barstein N J,Kaplan R,WolffS,etal.U sing lexical sem antic technicuesto classify free-responeses [C].Proceedings ofAritual M eeting ofthe Associatiion of ComputationalLinguistics.Santa Cruz:University ofCalifo to is,1996:227-246.
[19]Callear D,Jerram s-Smith J,Soh V.CAA of shortnon-MCQ answets[J]. Proceedingsofthe5th InternationalCAA Conference.Loughborough:Loughborough U niversity,2001.
[20]Mitchell T,RussellT,B room headP,et al.Towards robustcomputerized marking of free-text responses[C].Proceedings ofthe Sixth International ComputerAssisted Assessment Conference.Loughborough:LoughboroughUniversity,2002.
[21]高思丹,袁春風.语句相似度计算在主观题自动批改技术中的初步应用[J].计算机工程与应用,2004,40(14):132-135.
[22]张添一.基于文本相似度计算的主观题自动阅卷技术研究[D].东北师范大学,2011.
[23]张均胜,石崇德,徐红妓,等.一种基于短文本相似度计算的主观题自动阅卷方法,图书情报工作,2014(19):31-38.
[24]刘逸雪,卢雨轩,丁亮,汪星明.基于Bi-LSTM的数学主观题自动阅卷方法[J].管理观察,2018(2):109-113.
[25]KishorePapineni,Salin Roukos,ToddWard,and Wei-Jing Zhu,BLEU:a Method for A utom atic Evaluationof Machine Translation,Proceedingsof the 40th AnnualM eeting ofthe A ssociation for C 0m putationalLinguistics (ACL),Philadelphia,July2002,pp.311-318.
- Unit 6 A Special Machine Lesson 2 (一)
- “推门听课”如是说
- 浅议在生物教学中激发学生的学习内驱力
- 设情境抠细节多变化活运用
- 有效开发体育课程资源不断增强高寒地区学生体质
- 做快乐教育 享快乐人生
- 美国孩子书包里装着啥
- 外国孩子没那么好“混”
- 暑假,美国中小学教师怎么过
- 偷来的捐款
- 聊聊家访那些事
- 丰厚的文学积累与明晰的思辨能力成就高考作文
- 关于2015年哈尔滨市中考语文试卷“古诗词默写”部分的阅卷思考
- 穿越文言经典 找寻应对策略
- 2015年高考语文(新课标全国卷Ⅱ)语言运用
- 2015年高考语文(新课标全国卷Ⅱ)诗歌鉴赏试题部分浅析
- 2015年高考语文(新课标全国卷Ⅱ)文言文阅读试题分析及备考策略
- 班建小档案与班级责任意识
- “双向四环五步”课堂教学模式
- 以课例探究话题作文写作指导的教学思路
- 例谈语文阅读教学中“动态生成”的困惑及解决策略
- 关于教师的职业压力
- 新课程下初中省情教育功能定位与实施路径研究
- 同课异构 精彩纷呈
- “小组评价” 班级自我管理策略
- bungee jump
- bungee jumping
- bungee jumpings
- bungee-jumpings
- bunger
- bungest
- bunging
- bungle
- bungled
- bungler
- bunglers
- bungles
- bungling
- bunglingly
- bungs'
- bungs
- bung sth ↔ up
- bung-up
- bung²
- bung¹
- bunion
- bunions
- bunk
- bunked
- bunker
- 观赏玩味
- 观赏秀丽景色
- 观赏美景
- 观赏胜景
- 观赏自然景色
- 观赏节日所设的彩灯
- 观赏花卉
- 观赏花名
- 观赏街景的窗户
- 观赏风光
- 观赏风景
- 观赏鸟
- 观赏,玩赏
- 观赛
- 观过知仁
- 观通站
- 观阁
- 观阅
- 观阙
- 观阵
- 观隅反三
- 观雀
- 观音
- 观音佛
- 观音党