[摘 要] 应用学习向量量化LVQ神经网络方法,以近期14个数据作为财务危机预警建模样本和测试样本,建立了财务危机的预警模型,经过对样本的反复训练和学习,得到了较好的预测结果?研究结果表明:LVQ神经网络是一种非线性映射模式,在指标间相关度较高?呈非线性变化,或数据缺漏不全等情况下仍可得到比较满意的结果,因此是一种比较理想的预测方法,具有广泛的适用性和较高的推广价值?
[关键词] 财务危机;预警;学习向量量化LVQ神经网络方法
[中图分类号]F232;F275[文献标识码]A[文章编号]1673-0194(2009)02-0031-02
一?引 言
财务失败又称为财务困境或财务危机,最严重的财务危机就是企业破产?当一个企业无力履行合同?无力按时支付债权人利息和偿还本金时,该企业就面临财务失败?事实上,企业陷入财务危机直至破产是一个逐步的过程,大多数企业的财务失败都是由财务状况异常到逐步恶化,最终导致财务失败或破产的?因此,企业的财务失败不但具有先兆,而且是可预测的?目前我国金融银行业的竞争日趋激烈,正确地预测企业财务失败对于保护投资者和债权人的权益?对于经营者防范财务危机?对于政府管理部门监控上市公司质量和证券市场风险,都具有重要的现实意义?当前被广泛研究并应用于财务失败预测的模型主要有统计模型和人工智能模型两大类?传统的统计模型包括多元判别分析模型(MDA)和对数回归模型(Logistics Regression)等,这两者也是应用最为广泛的模型?统计模型最大的优点在于其具有明显的解释性,存在的缺陷在于其过于严格的前提条件?如MDA要求数据分布服从多元正态分布?同协方差等;对数回归模型虽然对数据分布的要求有所降低,但仍对财务指标之间的多重共线性干扰敏感,而现实中大量数据分布都不符合这些假设前提,从而限制了统计模型在这一领域中的应用?
二?问题描述及LVQ网络的适用性
随着信息技术的发展,人工智能和机器学习的一些分类和预测的算法也被引入到金融信用风险评估领域中来,主要包括人工神经网络和决策树的方法?决策树是一种自顶向下的分类方法,它通过对一组训练样本的学习,构造出决策型的知识表现?决策树具有速度快?精度高?生成模式简单等优点,但是这种归纳学习的方法容易造成模型的过度拟合,而且当问题复杂时,决策树的解释性也会降低?人工神经网络具有良好的容错性?自适应性和很强的泛化功能?现实世界中的企业财务失败预测问题往往非常复杂,企业的各项财务指标之间相互影响,呈现出复杂的非线性关系,而神经网络正是处理这类非线性问题的强有力的工具,近年来开始被引入金融信用风险评估领域中?尤其是基于神经网络的企业破产预测方法逐渐显示出它的优越性,已经开始成为新的研究热点,应用的模型也从主要以BP网络为主逐渐扩展到其他类型的网络,本文尝试利用以竞争神经网络为基础的学习向量量化LVQ网络,基于我国上市公司的实际数据对财务失败进行预测?
三?数据样本的收集
本例采用的用于构建破产预测模型的财务数据全部来自我国上市公司的真实数据,其中选取的财务破产公司是指在连续2年内被股市特别处理(ST)的公司,同时依据行业分类选取该行业的其他公司为正常公司,以财务状况异常最早发生日为基准日,选取这些公司在基准日前2年的财务报表数据?共选取了102家财务状况异常公司,481家正常公司(不同年份的同一家公司也认为是不同的公司),共583家公司来构建样本的集合?出于篇幅的原因,这里选用了其中的8个非ST公司和6个ST公司的样本?
这里把所有样本数据分成两份,分别是训练集和测试集?已有研究表明,在分类模型的建立过程中,如果训练集合中两类样本数据的数量相当,则所建模型具有较强的健壮性,因此这里的训练集由相同数量的两类样本构成(ST和非ST公司分别是5个样本)?测试集中ST和非ST公司样本分别是1和3个,用于测试在训练集上构建的LVQ网络模型的预测精度?
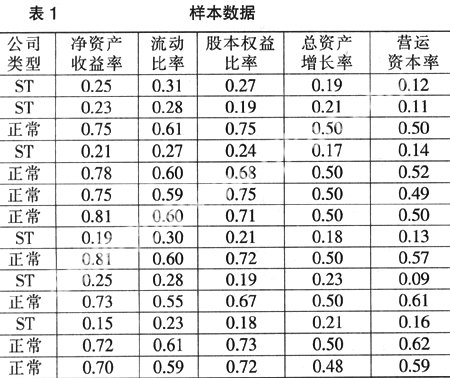
特征选择是模式识别分类问题中的关键步骤,综合考虑覆盖面和计算量的问题,这里选择了最能反映公司财务状况的5个财务指标:净资产收益率?流动比率?股本权益比率?总资产增长率和营运资本率?样本数据如表1所示?
四?LVQ神经网络建模与测试
由于所有数据都已经在[0,1]中,所以对于表1中的数据,无需进行归一化处理,可直接投入训练及测试?
这里利用前5个ST公司的样本和前5个正常公司的样本作为网络的训练样本,后1个ST公司和后3个正常公司的样本作为网络的测试样本?
首先,创建一个LVQ网络:
net=newlvq(minmax(p),8,[0.5 0.5]);
其中,p为训练样本中的输入向量,8表示网络的竞争层神经元的数目,[0.5 0.5]表示输入样本中属于第1类的数据占50%,属于第2类的占50%,学习算法learnlv1?由于竞争层神经元的数目可以影响网络分类性能,因此需要通过不断实验进行选择?
接下来利用训练样本对网络进行训练:
tc=[1 1 2 1 2 2 2 1 2 1];t=ind2vec(tc);net=train(net,p,t);
其中,tc为输入向量所属的类别,ST公司用1表示,正常公司用2表示?函数ind2vec将类别向量转换为网络可用的目标向量?网络的训练结果为:
TRAINR Epoch 0/100
TRAINR Epoch 2/100
TRAINR,Performance goal met.
网络经过2次训练后,误差就达到了要求?
对网络进行模拟,检验网络是否对训练数据中的输入向量进行了正确的分类?
y=sim(net,p);yc=vec2ind(y);
输出结果为:yc=1 1 2 1 2 2 2 1 2 1
yc=tc,可见网络的分类是正确的?
接下来对网络进行交叉检验,即利用网络队训练样本以外的数据进行分类:
tc_test=[2 1 2 2];y_test= sim(net,p_test);yc_test=vec2ind(y_test)
y_test为网络测试样本中的输入向量,tc_test表示输入向量的类别?输出为:
yc_test=2 1 2 2
yc_test= tc_test,可见网络对输入向量进行很好的分类?
主要参考文献
[1] 朱顺泉. 管理科学研究方法——统计与优化应用[M]. 北京:清华大学出版社,2007.
[2] 飞思研发中心. 神经网络理论与Matlab 7实现[M]. 北京:电子工业出版社,2005.
- 王建新 填补丝路考古空白的中国人
- 刘永好搭乘“一带一路”航船远行
- 青山绿水 风景怡人 故乡滋味 别样乡愁
- 榆阳区李家沟村“第一书记”刘宏德“扶贫记”
- 黄龙县交通局践行“两学一做” 争做先进典型
- 富平高新技术产业开发区标准厂房隆重招商
- 强力推进精准扶贫 实现如期摘帽目标
- 小核桃撑鼓农民腰包
- 古丝路上的水烟作坊
- 创新发展“一带一路”战略
- 百年口岸霍尔果斯
- 速度与激情
- 阿拉山口的创业者
- 阿拉山口 迎风舞动的戈壁新城
- 风动阿拉山口
- 习近平的“一带一路”足迹
- 构建“一带一路”金融生态体系
- “一带一路”战略与南方丝绸之路经济大走廊构想
- 陕西打造“丝绸之路新起点”战略实现路径
- 构建“唐蕃古道”经济带设想
- 亚投行:有志者事竟成
- 丝路申遗的跨国行动
- 泰国搭上“一带一路”的中国快车
- 海上丝绸之路的“泉州味道”
- “一带一路”的陕西脚步
- necessitate
- necessitated
- necessitates
- necessitating
- necessitations
- necessitative
- necessities
- necessity
- neck
- neck and neck
- necked
- necker
- neckers
- necking
- necklace
- necklaced
- necklaces
- necklacing
- neckless
- necklike
- neckline
- necklines
- necks
- necktie
- necktieless
- 阿q正传
- 阿q精神
- 阿sir
- 阿丈
- 阿上
- 阿世
- 阿世取容
- 阿世媚俗
- 阿世媚俗悦世徇俗
- 阿世徇俗
- 阿世盗名
- 阿主
- 阿九孟康
- 阿二吹笙
- 阿二当郎中
- 阿二(方言,指痴呆、懒散的男子)吃面
- 阿二满街串
- 阿二炒年糕——吃力不讨好
- 阿二钓黄鳝——不上钩
- 阿亚库巧战役
- 阿从
- 阿们
- 阿伏伽德罗
- 阿伏伽德罗常数
- 阿众