陈道蓄

在道路网络中确定起点到终点的最短路径,可以抽象为一个有向图模型。图中每个节点表示一个“路口”,对任意节点u,v,存在uv-边当且仅当从u到v有“路段”直接相连(当中没有其他路口)。也可以建立无向图模型,则任一条边对应于双向可通行的路段。其实这样的模型并不限于道路交通问题,从本专栏前面的文章中读者已经看到许多与交通运输无关的问题都可以抽象为图模型,“最短路径”在不同应用中可能背景意义不同,但确定最短路是大量基于图模型的应用问题求解中的一个基本环节。
● 用广度优先搜索(BFS)算法求解
先来考虑有向图模型上一种最简单的情况:假设每个路段长度均为1,那么,从u到v最短路的长度即为所有uv-路中包含的边数的最小值,也称为从u到v的距离。
设想房间的角上有个水龙头,其所在位置是房间地面最高点。地面高度向房内其他地方极其平缓地均匀下降,将龙头开到适当大小,水会在地面以扇形缓缓漫开。如果像动画片一样间隔固定时间段记录漫水区域的边界,看到的将是一道道大致平行的弧形曲线,它们反映了边界上的点与水龙头位置的大致距离。
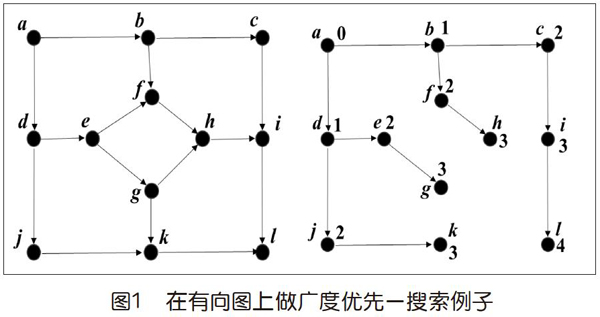
在图中遍历所有节点常用算法包括“深度优先(DFS)”与“广度优先(BFS)”。本专栏在前面讨论走迷宫和调度问题时,都采用了深度优先算法。从上面的比喻很容易想到:考虑点与点的距离时该采用广度优先算法。事实上,在本专栏在前面讨论图的连通性时,简单地用到了广度优先(尽管我们没有提到这个名词)。图1给出一个简单的例子,指定a为起点,则广度优先搜索生成的BFS树可能如图1中右图所示。
右边结果图中每个节点名称旁标的数字表示从起点a到该点最短路的长度。在广度优先搜索过程中,距离a较远的节点被发现的时间一定晚于较近的节点。
这个例子显示了广度优先搜索过程与最短路径的关联。由此在每条边长度均为1的假设下,我们可以用广度优先算法解最短路问题。
为了体现前面的比喻中漫水区前缘均匀推进,算法用队列Q放置当前已经“看见”并等待处理的顶点。队列“先进先出”的特性恰好符合均匀推进的需要。每个节点有两个参数:d表示从起点到该点的距离,初始值为∞;p表示在生成的BFS树中该点的“父节点”,初始值为nil。算法过程如下页图2所示。
广度优先搜索算法对图中每个节点只“发现”一次,在搜索所有节点的邻接表过程中每条边只处理一次,因此算法的时间复杂度为O(m+n)。读者不妨用前面的例子模拟一下队列操作的全过程,这样对广度优先算法会有更清楚的理解,并能理解为什么算法结果是正确的。严格的正确性证明可以基于队列操作用数学归纳法,有兴趣的读者可以参阅文献[1]。
在实际应用中要求每条边长度为1是不合理的。根据应用的含义,我们给每条边指定一个确定的数值,这称为“权”,相应的图称为“(带)权图”。显然图2所示的BFS算法不能用于带权图。解题时可以考虑一种重要的思路——问题规约。我们会想当前的问题是否可以改造成我们已经解决的某个问题,利用那个问题的解得到当前问题的解。那么我们是否能将带权图规约为BFS可以处理的图呢?如果权值均为正整数,这非常简单。对应输入的任意图G(每条边有正权值),我们按照如下方式构造图G:G的节点集与包含G中所有节点;对应G中每条边e(假设权值是k),在G中用一条长度为k的有向通路替换,通路的端点即G中边e的端点,方向保持一致。通路中的k-1个中间节点是G中没有的。G中的边没有权值。读者很容易证明,基于BFS算法对G的计算结果可以得到原问题(对带权图G)的解。
为什么这个方法不适用?如果我们问:BFS算法的复杂度是线性的,现在还是吗?读者是否能回答?
顺便提一个问题:深度优先算法中先被发现的节点一定比后发现的“后裔节点”更晚关闭(回溯),这就需要采用“后进先出”的栈结构;但大家在本专栏前面讨论走迷宫或调度问题的DFS过程中并没有看到明确地使用栈结构,这是为什么呢?
● 带权图的最短路算法
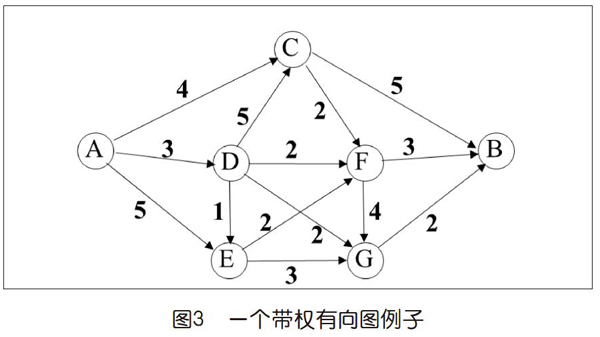
可以将带权图理解为输入除了上述的G和s外还包括一个函数w,其定义域为图中的边集,值域通常是数集。简单说每条边有个确定的数值,其应用含义可以是相应路段的长度、运输成本、通过时间等(在与道路交通无关的应用中也可以是其他任意合理解释)。一条通路的权值定义为它包含的所有边的权值之和,因此,最短路问题就是找出总权值最小的路径。注意,如果图中s可以通达某个总权值为负值的回路,“最短”就无意义了。本文假设所有边的权值均非负。图3是一个带权有向图的例子。
假设我们需要计算图中从节点A到B的最短路,最“朴素”的贪心策略不能保证找到正确的解。假如从A开始我们始终选择“当前”顶点所关联的权最小的边前行,结果是A-D-E-F-B,路径长度为9。但是路径A-D-G-B长度为7(这确实是最优解)。
有一种方法可以保证找到最优解。用S[v]表示从A到v最短路的长度,从终点“反推”,可得:
1. S[B]=min{S[C]+5,S[F]+3,S[G]+2},注意这个式子的形成规则
2.? S[G]=min{S[D]+2,S[E]+3,S[F]+4}
3.? S[F]=min{S[C]+2,S[D]+2,S[E]+3}
4.? S[C]=min{4,S[D]+5}= 4
5.? S[E]=min{5,S[D]+1}
6.? S[D]=3
從下往上逐次代入,很容易得到:S[B]=7。这就是最优解。我们可以将S[v]看作待解问题的子问题。如果子问题S[u]的计算需要用到子问题S[v]的结果,就说前者“依赖”后者。(这个依赖关系本质上与本专栏前面讨论的调度问题中涉及的一样,不是吗?)这个方法称为“动态规划”。动态规划需要计算所有的子问题,似乎会导致指数级的复杂度。但是如果能够仔细地对所有子问题排序,保证被依赖的一定会先计算,并且能设计一种可以快捷地存取子问题解的方法,那么就可能设计出非常有效的算法。因此,动态规划是一种很重要的算法设计方法。在本专栏2020第9期的《投资组合问题》一文中用的也是动态规划方法(见参考文献[2])。
现在我们来介绍非常著名的Dijkstra算法。Dijkstra算法用非常简单的贪心策略的“形”,包裹了动态规划算法保证正确的“魂”,却又针对问题的特征,避免了烦琐的子问题定义与结果存取,采用逐个为图中节点加标号(在算法执行过程中,标号的值即从起点到该节点当前已发现的最短路径长度值,尚未“被发现”的节点标号值为“无穷大”)的方式计算从起点s到图中所有其他节点的最短路长度(也称距离)。因为算法计算的是从特定起点到其他所有点的最短路,所以通常称为“单源最短路算法”。
为了使读者更容易理解Dijkstra算法,我们把前面关于水龙头的比喻放在图模型的背景下重新表述一下:往一张宣纸上缓缓地泼墨,首先将起点s覆盖,然后在算法控制下逐步扩大“墨点”覆盖范围。在任一特定时刻,墨迹覆盖区域有一个边界。如果采用上面讨论动态规划时的说法,界内的点u相应的子问题S[u]已解;从加标号的角度说,界内节点的标号已经固定,不会再被改变,这就是从s到该点最短路的长度值。另一方面,与边界内任一节点相邻的外部点是“当前可见”的。
每次扩大“墨点”总是选择尚未被覆盖但“可见”的节点中标号最小的。开始时s标号为0,其他节点标号均为∞。每當一个节点v被覆盖(从s开始),与其相邻的点u的标号将更新为min{u原标号值,v标号值+w(vu)},其中w(vu)是vu-边的权值。任何可见但尚未被覆盖节点的标号在每次循环中均可能被改变,这取决于是否发现了从s到该点的更短的路径(可以比较一下动态规划过程)。当全部节点均被覆盖时算法终止。
若图中节点数为n,则上述“墨点扩散”通过n-1次循环完成,图4针对前面的例子,给出前4次循环形成的“墨迹”边界示意。每次循环确定一个节点的“固定”标号,操作序列为:A(0),D(3),C(4),E(4)。已覆盖的点在图中用黑体字标注标号,注意,E的标号在D被覆盖时由5更新为4。本文中算法在标号值相等时按照节点名字母顺序执行。目前,B,F,G也均“可见”,因此均具有有限标号值。注意,随着F与G先后被覆盖,B的标号值还将更新两次,最终达到7。
从上面的描述中读者应该很容易理解Dijkstra算法的基本逻辑:通过一个循环过程,以尽量减小已有标号的方式将所有节点的标号固定下来,最终达到从s到各节点的最短路长度值。对初学者而言,最难理解的地方可能在于:每次扩大“墨迹”新覆盖的节点究竟是如何确定的。当然在每次循环中,在所有可见的节点中找出最小元素,这显得有些笨拙,因为可见的节点数可能接近n。
在描述Dijkstra算法之前,我们先来介绍一种对算法设计非常有价值的思维方法——数据抽象。为了解决单源最短路问题,我们希望每次循环中从“可见”的节点中选择标号值最小的。假设这些节点以某种形式存放着,有一个节点选取操作,总是返回其中标号值最小的元素,那么算法层面的考虑就很简单了。至于怎么能实现这一点,到编程时再考虑。这就称为“数据抽象”,显然它可以使我们在设计算法时避免编程细节的纠缠,聚焦于解题逻辑。
数据抽象在编程实践中常以抽象数据类型的形式体现。对这个例子而言,人们常用的是“最小优先队列”(priorityQ),它按照key的值定义“优先级”,出队列总是“优先级”最高的元素。这里key即标号值,小的优先。注意,一般的队列可以认为是“优先队列”的特例,key为进队列时间,时间值小的优先。key的值可以设置,也可以修改。
我们建立一个最小优先队列类型的对象PQ,其元素为图G中所有“可见但标号尚未固定”的节点(也就是“紧邻墨迹区”的外部节点)。我们需要该结构提供如下操作:
◇ create(): 创建最小优先队列类型的对象
◇ enqueue(PQ,v,key):节点v进队列PQ,其键值置为key
◇ dequeue(PQ): 从队列PQ中出一个元素,一定是队列元素中key最小的(之一)
◇ decreaseKey(PQ,v,key):将已经在队列PQ中的对象v的键值降为key,在算法过程中,当从s到已被发现但尚未完成的v找到一条更短的通路时,需要这个操作
基于优先队列的Dijkstra算法过程见图5。过程中假设抽象数据类型priorityQ已定义。本文中不讨论其实现。用二进堆(binary heap)实现的细节可参考文献[1]。Python语言中提供的class为抽象数据类型实现提供了方便。有兴趣的读者不妨试一试,并在此基础上编写完整的解单源最短路问题的程序。
下页图6显示上述过程前6次循环执行效果。最后一次(第7次)只会将B点置为黑色。
Dijkstra算法的正确性基于论断“第k+1次循环即将开始时,有k个节点状态为“black”,此后这些节点的标号不会再更新,且其值为从s到这些点各自的最短路长度”。这个论断可以通过对k用数学归纳法证明。初略地看,算法执行n次循环,每次循环最多从n个节点中选标号的最小值。在加标号过程中每条边也只需检查一次。这是一个O(n2+m)算法,m表示图中的边数。读者已经看到利用优先队列,不需要每次遍历查找最小元素,但每次进出队列操作后维护优先队列的特性(即出队列的一定是优先级最高的元素)需要代价。精心设计的实现方法可以使Dijkstra算法的时间复杂度达到O(nlogn+m),对应用中比较普遍的非稠密图(边数只是节点数的常数倍,而非平方数量级),这显然好于O(n2)。
● 负权值的影响
输入中不能含有总权值为负的回路,这很容易理解。但前面特别说明不能有负权值的边,这要求更高,这是为什么呢?
前面介绍过“问题规约”的思路。读者可能会想到如果输入中包含负权值的边,我们是否可以通过规约的方式消除负权值?原图中所有负权值一定有绝对值最大的,如t。假如将所有边的权值均加t,那就没有负权值了。下页图7是一个带负权值的图的例子。
- 浅谈对高热惊厥患儿的护理
- 浅析影响机织纺织品起毛起球的主要因素
- 中国数字成语与日语四字熟语的对比研究
- 浅谈规模化养猪场中的猪病流行特点及防治
- 网红现象背后的文化特质探析
- 新型多功能焊工培训焊接工装架
- 某型发动机压气机盘榫槽拉削工艺改进
- 金工实习中数控车床对刀方法探讨
- 加强建筑电气工程施工中细节管理
- 浅谈建筑工程施工技术创新
- 精细研究,细分层系,努力提高樊15块质量开发效益
- 市政道路路面结构及路基设计
- 小学数学教学中渗透数学思想方法的探讨
- 谈小学数学情境与趣味教学
- 基于核心素养的小学数学教学设计例谈
- 大学数学教学中导入概念和结论的策略
- 高中数学学困生的成因与转化对策探究
- 学生数学实践能力的培养策略探析
- 新课程背景下初高中数学衔接的实践反思
- 基于“互联网+”的高职数学教学方法研究
- 小学数学教学生活化的有效策略
- 新课改下小学数学教学方法的创新分析
- 教学情境下小学数学的激趣策略分析
- 浅谈小学数学后进生转化的策略
- 浅谈新课标下如何提高高中数学教学的有效性
- dear
- dearer
- dearest
- dear jim/sarah etc
- dearly
- dearmoney
- dear money
- dearmoneypolicy
- dear money policy
- dearness'
- dearnesses
- dearness's
- dear old... / dear little...
- dears'
- dears
- dear sir/sirs/sir or madam
- dearth
- dearths
- dear²
- dear³
- dear¹
- death
- deathbed
- deathbeds
- deathbenefit
- 宪宪
- 宪属
- 宪师
- 宪度
- 宪廑
- 宪律
- 宪恩
- 宪意
- 宪慈
- 宪批
- 宪政
- 宪断
- 宪曹
- 宪术
- 宪极
- 宪治
- 宪法
- 宪法大纲
- 宪照
- 宪眷
- 宪矩
- 宪祖
- 宪禁
- 宪秩
- 宪章