摘要:
语料库语言学需要从大规模文本提取语言特征,通过量化分析研究语言规律。现有语料库工具过于注重索引和检索功能,无法开展涉及復杂统计的多因素分析。通过3个基于语料库的研究实例,探讨编程语言Perl和R在研究方法层面的应用。结果表明,Perl和R能够处理大规模文本,进行多变量统计与可视化分析,可以弥补现有语料库软件的不足,帮助研究者分析数据与验证假设,为后续定性研究奠定基础。
关键词:
语料库语言学;语料库工具;Perl;R
DOIDOI:10.11907/rjdk.172822
中图分类号:TP312
文献标识码:A文章编号文章编号:16727800(2018)001005303
Abstract:Corpus linguistics aims to find language patterns based on linguistic features extracted from largescale texts. However, current corpus tools are dedicated to developing concordance and search functions while lack of functions to perform multivariate statistical analysis. This paper illustrates with three case studies how programming languages such as Perl & R can be used in corpusbased linguistic studies. It is found that Perl can extract linguistic features from texts and organize them in formats that are amenable to statistical analysis in R. When combined, these two kinds of software can help researchers explore the linguistic data and validate search hypothesis in a more flexible way and complement the functions of readymade corpus tools.
Key Words:corpus linguistics; corpus tools; Perl; R
0引言
基于语料库的语言学研究需要借助工具处理大量文本文件,提取其中的语言特征进行统计分析。目前,语料库工具已由第一代单机版进化到第四代网络版,界面更加友好,运行速度更快,可以帮助研究者开展基于词表、搭配和主题词等功能的研究[12]。但现有工具过于注重检索和索引功能,无法处理涉及复杂数据的多变量统计问题,研究者仍需编写程序满足特定的研究需求。本文探讨如何用编程语言Perl和R解决现有工具面临的技术问题,帮助研究者开展基于语料库的量化实证研究。
1Perl & R简介
Perl的模式匹配功能强大,擅长从大规模语料中提取各种词汇和语法特征[3];R支持描述性、推论性和探索性统计以及数据可视化分析,在基于用法的语言学(usagebased linguistics)研究中应用广泛[4]。使用Perl & R开展量化研究涉及以下3个步骤:①建立子语料库。语料库通常包括丰富的元信息,如国别、区域、年代和文本类型等。Perl可以根据元信息从大型通用语料库提取文本,构建面向特定研究问题的子语料库;②检索语言特征。Perl可以从经过词性或句法标注的语料中提取词汇语法特征,构建特征矩阵;③进行统计分析。用R处理步骤②得到的矩阵,分析特征变量间的关系,并以可视化方式呈现结果。
本文通过3个案例说明如何结合Perl和R开展基于语料库的语言学研究。
2案例分析
2.1短语框架
在语料库语言学中,短语框架是指由两个以上词语构成,反复出现的连续或非连续词语组合[5]。Sinclair[6]将语言中的短语化倾向称为习语原则,是意义研究的基本单位。短语并不是完全固定的,在具体语境中,其内部会产生变化,例如4词短语框架“as * as the”中的 “*” 可由不同单词替换,如“as well as the”、“as far as the”和“as soon as the”等。
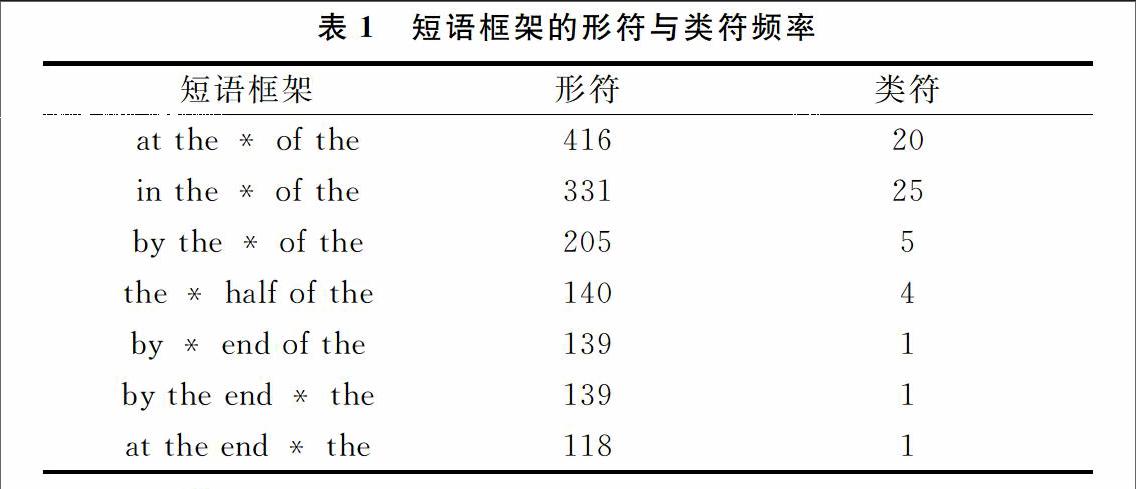
本案例考察BNC语料库国际事务类文本中3~6词短语框架的分布情况,只考虑框架内部的位置变化,一个n词短语框架包含n-2种类型,例如5词短语框架包括以下3种类型:A * C D E、A B * D E和A B C * E。具体研究步骤如下:①从BNC语料库选取有关世界事务的文本61篇,共2 325 465词;②提取子语料库中的连续n词序列,统计其频率和覆盖率。有些序列的频率虽高但覆盖率低,如“the labour league of youth”共出现18次,但只出现在1个文本中。本研究关注反映语体一般属性的n词序列,将覆盖率的值设定为大于等于5,排除类似上例话题性较强的专有名词;③从连续多词序列中提取多词短语框架,统计其形符和类符频率以及各框架槽位中的词汇分布。
如表1所示,短语框架的类符数差异较大,如“in the * of the”的种类最多,而“by * end of the”只有一种类型“by the end of the”。进一步分析后发现,“in the * of the”槽位中的词汇类型可分为以下3类:事件内容(如“in the hands of the”)、事件时间或地点(如“in the middle of the”、“in the center of the”)和事件叙述方式(如“in the case of the”)。本案例的统计数据只反映了短语框架的总体分布趋势,研究者还需借助索引行观察短语的具体语境,分析其意义和功能。
2.2语体变异
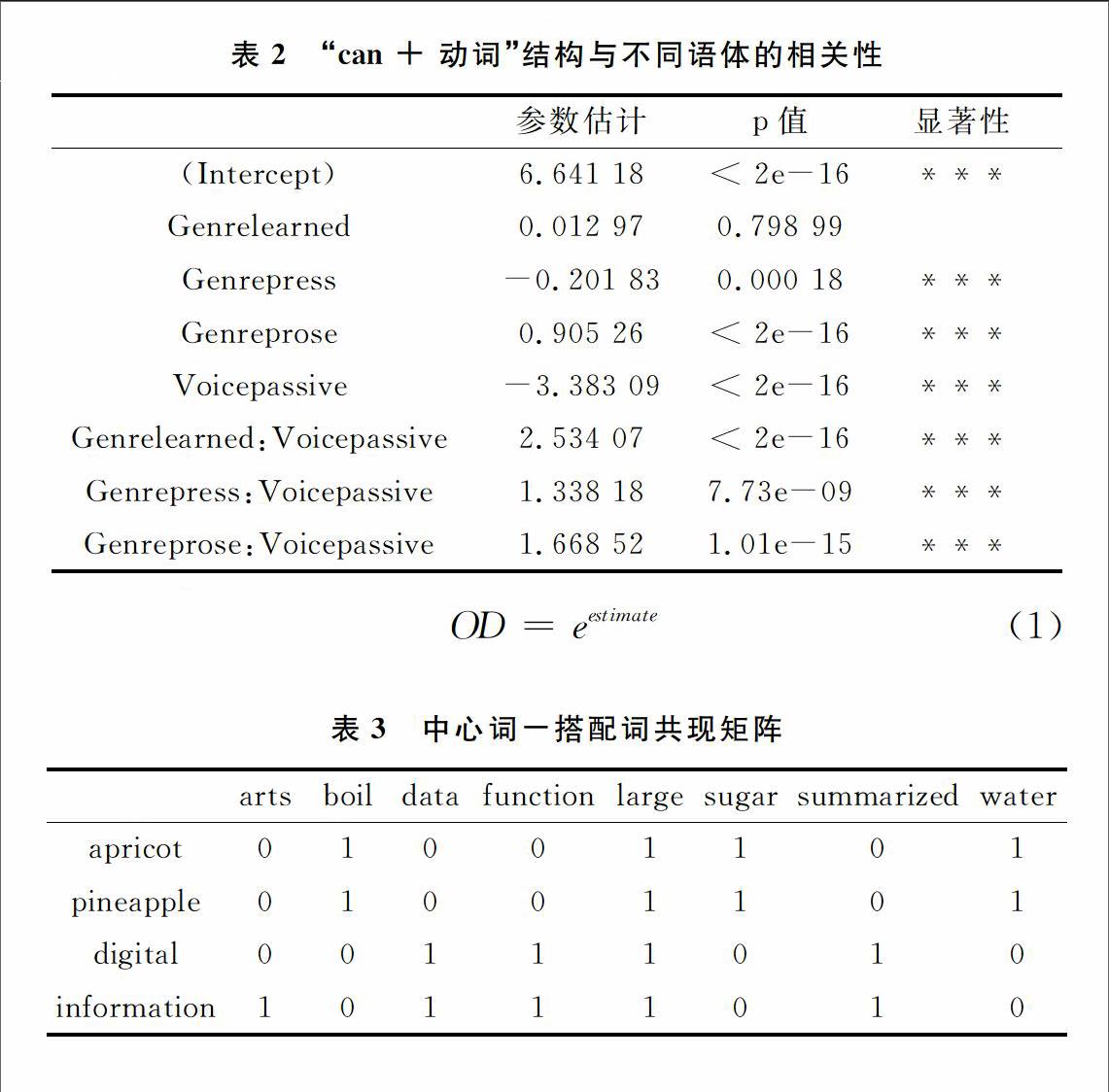
语体变异源于变异社会语言学,指语言随时间、地域、场合以及使用者年龄、性别和社会阶层不同而变化的现象。本案例研究英语情态动词“can”的后续实义动词语态在小说、新闻、通用和学术语体中的变化趋势,所用语料来自CRWON和CLOB语料库,共2 029 895词。本研究用Perl提取与“can”共现的实义动词,然后使用R的对数线性模型分析动词语态在各语体中的分布是否存在显著差异,得到表2所示的统计结果。
由表2可知,“can + 动词”结构的语态(Voice)与文本类型(Genre)显著相关。具体来说,与小说相比,新闻、通用和学术文体中动词被动与主动语气的比值分别上升了3.8、5.3和12.6倍,计算方法如式(1)所示。其中OD为比值比(odds ratio),本例中代表各语体被动与主动语气的比值,e≈2.718,estimate为表2 参数估计列的值[7]。
小说文本常用“can+主动语气”表明说话人的意愿,如“I know that I dont look old enough to handle this job but I assure you I can do it”;而学术文体在用can表达某一命题的可能性时,经常要隐藏事件的实施者,减少个人观点的表达,如“The actant analysis is a device that can theoretically be used to analyse any real or thematised action”。本案例说明除了对比不同语料间的词频差异外,语料库语言学研究还可扩展到语法层面,利用Perl和R提取语法结构,分析词汇与语法间的相互关系。
2.3词汇语义
基于语料库的词汇语义研究与搭配密切相关,与中心词共现的搭配词可以反映该词的语义特征,出现在相似语境的词汇意义也相似[8]。表3说明了如何利用搭配词分析中心词“apricot”、“pineapple”、“digital”和“information”之间的语义关系,表中数字代表中心词与搭配词的共现频率,用于构建描述词汇的特征向量[9],如f apricot = [01001101],f digital = [00111010]。
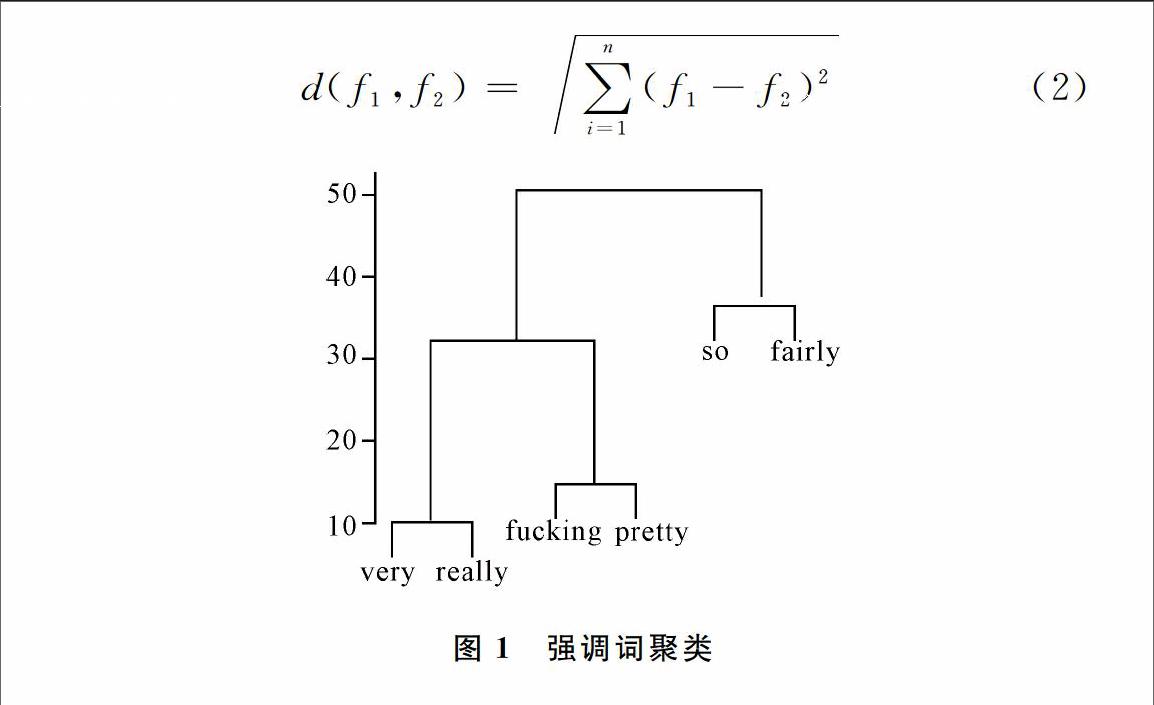
得到特征向量后,可根据式(2)计算向量间的欧几里德距离,建立词汇距离矩阵,然后使用聚类算法分析词汇的意义联系,从定量的角度验证人们对语言的直觉认识。
本案例聚焦程度副词“fairly”、“fucking”、“pretty”、“really”、“so”和“very”之间的语义关系。研究数据从BNC口语语料选取,共153篇,4 219 309词。具体步骤如下:从语料提取上述6个强调词所修饰的形容词,然后按表3格式输出搭配词的种类和频数,最后用R进行聚类分析。结果如图1所示,其中纵轴为词汇间的语义距离,如“very”与“really”之间距离最小,语义最接近。
图1强调词聚类
进一步观察发现,“very”和“really”的高频搭配词都是“good”和“nice”,两者合计占到各自搭配词总数的29.6%和27.6%;低频搭配词如“small”和“expensive”的比例也相似,均为0.1%左右,因此两者语义关系最近。另外,“so”的常见搭配是“funny”(6.5%)和“bad”(5.5%);“fairly”的高频搭配是“easy”(5.5%)和“good”(4.8%),虽然被归为一类,但由于距离较大,两者意义还是相差较远。聚类分析为研究词汇语义关系提供了新的视角,但也有其局限性。如“fucking”和“pretty”两词因为搭配词相似,在层级图上距离接近,但两词的使用可能与使用者性别有关,需要考虑更多变量加以区分。
3结语
从以上案例可以看出,Perl可以快速从大规模语料提取各种语言特征及其频率,构建词-词或词-文本共现矩阵,R擅长矩阵处理和统计分析。两者结合可以帮助研究者分析数据,初步形成研究假设,为后续定性研究奠定基础。需要注意的是,工具是研究的“利器”,但研究者还需学习语言学理论,专注语言层面的分析,扩展研究思路和视角。
参考文献:
[1]梁茂成.梁茂成谈语料库语言学与计算机技术[J].语料库语言学,2015(2):1525.
[2]许家金,吴良平.基于网络的第四代语料库分析工具CQPWeb及应用实例[J].外语电化教学,2014(5):1015.
[3]NUGUES P M. Language processing with perl and prolog,second edition[M].Berlin:Springer,2014.
[4]LEVSHINA N. How to do linguistics with R[M].Amsterdam:John Benjamins,2015.
[5]RMER U. Establishing the phraseological profile of a text type:the construction of meaning in academic book reviews[J]. English Text Construction,2010,3(1):95119.
[6]SINCLAIR J. Trust the text: language, corpus and discourse[M].London:Routledge,2004.
[7]AGRESTI A. An introduction to categorical data analysis,second edition[M].Hoboken,NJ:Wiley,2007.
[8]梁茂成.語料库语言学研究的两种范式:渊源、分析及前景[J].外语教学与研究,2012,44(3):323335.
[9]JURAFSKY D,MARTIN J H. Speech and language processing:an introduction to natural language processing[M]. Upper Saddle River,NJ:Prentice Hall,2009.
(责任编辑:何丽)
- 财税[2016]140号金融、房地产开发、教育辅助服务等增值税新政逐条解读
- 关于做好2016年油价调控风险准备金收缴工作的通知
- 关于进一步做好企业研究开发费用税前加计扣除政策贯彻落实工作的通知
- 集团化企业财务管理的探索与设计
- 基于保障房建设财务管理的问题及完善对策
- 关于军队财务管理内部控制的探讨
- 非理性财务行为对房地产企业营运资金管理的影响
- 审计视角下国企财务预算管理做法分析与阐述
- 权变理论下企业费用性项目预算管理研究
- 事业单位财会的精细化管理思路探究
- 论精细化财务管理在企业财务管理中作用
- 对企业全面预算管理探讨
- 企业预算控制存在的问题及对策探析
- 企业并购中的财务问题探讨
- 关于盘活财政存量资金的有效对策思考
- 论企业财务风险评价体系
- 基于大数据的企业财务管理创新研究
- 财务会计在企业管理中的地位和作用
- 强化预算执行进度管理,推进预算执行工作
- 医药批发集团IPO前期财务准备工作探讨
- 企业财务管理中金融工程的应用分析
- 加强集团化的财务管理工作的思考及建议
- 新常态下中小学财务管理存在问题及解决措施探究
- 浅析投资公司如何参与被投资企业的财务管理
- 基层事业单位财务监督存在的问题及对策
- intruded
- intruder
- intruders
- intrudes
- intruding
- intrudingly
- intrusion
- intrusional
- intrusions
- intrusive
- intrusively
- intrusiveness
- intrusivenesses
- intrusives
- in-trust
- intuition
- intuitionless
- intuitions
- intuition's
- intuitive
- intuitively
- intuitiveness
- intuitivenesses
- dip (from sth) (to/below sth)
- diphtheria
- 拘留逮捕
- 拘留,监控
- 拘确
- 拘碍
- 拘礼
- 拘礼之人,不可使应变
- 拘神遣将
- 拘票
- 拘禁
- 拘禁于囚车
- 拘禁于狱中
- 拘禁于笼中
- 拘禁管制
- 拘禁管束
- 拘禁美女
- 拘禁自己
- 拘窘
- 拘箝
- 拘管
- 拘籍
- 拘系
- 拘系押送
- 拘系罪人的绳索
- 拘系罪犯人的刑具
- 拘系马脚约束