江周峰 杨俊 鄂海红


摘要:在高校图书馆场景下,受限于图书特征信息的稀少,很难运用基于内容的推荐算法。本文针对图书馆推荐场景提出了一种结合社会化标签的基于内容的推荐算法。通过将图书的社会化标签与实体图书相结合的方式来补充图书的特征项。对于社会化标签中存在的标签模糊问题,本文在信息熵思想的基础上提出了一种模糊标签识别方法。对于识别的模糊标签,本文采用标签去除的方式来处理,以增加标签信息的可靠性。最后通过基于内容的推荐算法来测试模糊标签去除前后推荐的准确率,以此来判定模糊标签识别方法的准确性。实验结果证明,该模糊标签识别方法具有较好的准确性,可以较好的识别模糊标签。
关键词:推荐系统;社会化标签;模糊标签;基于内容的推荐
中图分类号:TP18
文献标识码:A
0 引言
推荐系统是实现个性化服务的重要手段,主要通过分析用户的历史行为记录得到用户的兴趣爱好,从而为用户推荐其需要的结果。如今,推荐系统已经应用在各行各业中,在大型电子商务系统以及社交网站中尤为常见。
目前,推荐系统在高校图书馆中的应用也较为普遍。关于高校图书的推荐目前大多采用协同过滤算法,这一点主要是因为用户的借阅记录比较易于获取。而协同过滤推荐算法倾向于推荐当前热门的图书,对于图书的覆盖不够全面,这就造成了很多图书不能够进入读者的视野。而基于内容的推荐拥有较为出色的覆盖率,但是受制于图书特征稀缺的问题,在高校图书馆中很难运用基于内容的推荐算法。以北京邮电大学图书管理系统为例,每本图书的特征不外乎作者、出版社等。本文提出了一种将虚拟图书与实体图书结合的方式来补全图书特征,即通过豆瓣图书的接口获得相关图书的社会化标签,以此作为图书的特征项。对于社会化标签中常见的标签模糊问题,本文利用信息熵的概念来衡量标签模糊度,并通过去除模糊标签的方式提高标签信息的可靠性。最后本文以基于内容的推荐算法为基础对标签模糊去除方法的有效性进行实验验证。
1 基于内容的推荐算法
1.1算法概述
基于内容的推荐是协同过滤技术的延续和发展,不过与协同过滤技术不同的地方在于基于内容的推荐对于用户和项目之间的评价信息的依赖程度变小了。这是因为对于项目与项目之间的相似度已经不依赖于用户的行为信息,而是只有项目与项目之间的内容有关。具体而言,这种推荐方式首先会确定用户之前喜欢的项目,然后利用项目与项目之间的相似度信息给用户推荐最为相似的项目。
对于基于内容的推荐系统其优点体现在如下几个方面:
由于计算项目之间的相似度只依赖于项目本身的特征,所以可以较好的规避冷启动问题。
一般系统过滤系统比较依赖于用户对于项目的打分,而这些打分通常比较稀疏,但是基于内容的推荐系统不受这方面约束。
对于推荐的结果可以有较好的解释,这点可以使用户对于当前推荐系统有信服感,体验感也会提升。
基于内容的推荐算法一般具有较好的系统多样性,对于系统中项目的覆盖率比较全面。
1.2算法设计
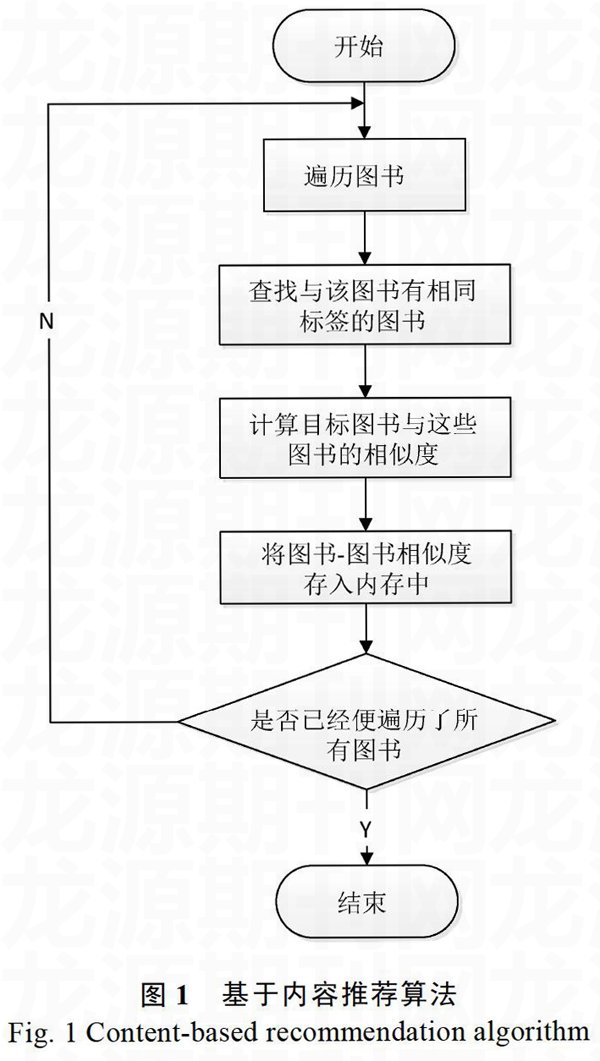
基于内容的推荐算法分为两部分,第一部分是计算相关项目的相似度,另外一部分是利用相似度进行用户对于图书的评分预测。关于图书——图书相似度的计算,其过程如图1所示。
根据流程图可知,我们首先获得图书的集合,遍历这个图书集合,对于每一本图书都与其他图书做相似度计算。关于图书一一图书相似度的计算,我们利用余弦相似度来计算,即式1。
评分预测模型如图2所示,其中b1、b2等表示用户借阅过的图书,B1、B2等表示与借阅图书相似的图书集合。此处我们需要对相似图书进行评分预测,进而根据预测评分为用户进行图书推荐。我们利用式2对相似读书进行评分预测,SUB表示用户U对于图书B的预测评分,B是相似图书集中的某本图书,Book即评分模型图中的借阅图书集合,RbB表示图书b和图书B的相似度。
通过这种方式计算用户对于所有相似图书的预测评分。
对这些图书按评分的高低进行降序排序,选取其中评分较高的图书进行Top-N推荐。
2 模糊标签识别研究
2.1信息熵
“熵”是德国物理学家克劳修斯在1850年创造的一个术语,他用它来表示任何一种能量在空间中分布的均匀程度。能量分布得越均匀,熵就越大。同理可知,信息熵可以用来衡量一个信息在各类资源中分布的情况。标签模糊简单来说就是一词多义,因此信息熵正好可以用来衡量标签模糊度。标签越模糊则代表该标签的信息熵越大,反之亦然。信息熵的衡量方法见公式3。
其中Cr表示出现过标签t的所有资源类,m(t)为标签t在全部资源类中出现的次数,m(c,t)为标签t在资源类C内出现的次数,m(c,t)/m(t)即表示标签来源于资源类C的概率。利用信息熵公式可以较好地衡量一个标签的模糊度,f(t)值反映了模糊度的大小,f(t)值越大则模糊度越大,反之则越小。根据信息熵的定义,我们知道如果标签t属于多个资源类,且在各个资源类中出现的次数越平均则f(t)值越大。当t只属于一个标签类时,可以知道f(t)为0。
在我们的社会化标签场景下,一个标签通常会标注多个资源类。然而,大部分标签虽然标注了多个资源类,但是其大部分都标注了某个资源类中的资源,那么这个时候该标签的模糊度不会太高。而有些标签在大部分资源类中出现的比重较为平均,那么该标签理应获得较高的模糊度值。如图3所示,标签t1在资源A和B中都出现了5次,标签t2在资源A和B中分别出现了8次和2次,根据公式3-2,我们可以计算得到标签t1的模糊度为1,标签t2的模糊度约为0.72。显然标签t1的模糊度较高,而标签t2很大概率上还是用于标注资源A的。该方法可以很好地反映社会化标签中各标签的模糊度。
2.2模糊标签识别方法
本文利用公式3-2进行模糊度识别处理。首先我们得构建标签一资源类矩阵WNM,具体见表1,其中N行代表N个标签,M行表示M个资源类,Wij表示标签Ti对于资源Sj的权重。模糊标签识别的准确性和资源分类的准确性有较大关系。如果某个资源归类到了错误的资源类就会导致标注了该资源的标签模糊度计算不准确。因而本文使用业界都认可的图书分类编号做为资源类别,即TP、TN等图书编号作为图书的类别,其中TP表示自动化技术、计算机技术。使用较粗的分类级别是为了更好地识别模糊标签。我们设定阈值α,如果某个标签的模糊度高于α,那么我们将该标签称为模糊标签。
输入:标签资源矩阵WNM,模糊度识别阈值α
输出:模糊标签集
处理步骤:
(1)从矩阵WNM中提取出所有的N个标签,记为T={T1,T2,…,TN};
(2)根据式4计算当前标签的模糊度。
(3)若所有标签都已计算模糊度,则退出循环;否则转到第2步选取下一个标签。
(4)模糊度值大于α的标签即为模糊标签,输出模糊标签集。
当计算出来模糊度标签过后,即可将这些标签删除。需要说明的是模糊度阈值α的设定还需参考具体的实验结果。
3 应用与评价
3.1数据说明
本文数据主要来源于两部分,第一部分是从北京邮电大学图书管理系统中的图书信息表中获取的图书基本信息,主要包括书名、作者、出版社、图书分类号等信息以及从图书借阅记录表中获取到的用户对于图书的历史行为记录信息。另外一部分是根据图书信息从豆瓣图书上获取的图书社会化标签信息。关于实体图书与虚拟图书相结合后的图书信息结构如表2示。
表中Tag代表获取到的社会化标签项,每个标签的格式为[标签名(权重)]。图书馆中共有图书40多万册,每本图书最多可以获取到50个社会化标签,其中有将近30%的图书可以获取到50个标签,也有一部分图书属于冷门图书,没有获取到标签。经统计每本图书约有26个标签项。
关于图书借阅记录表中的数据我们取2011年6月到2013年12月之间所产生的。借阅记录数据集中包含读者17407人,借阅事务1020672次。其中借阅446426次、续借132534次、预约14617次,其余的为归还与取消预约行为。我们会根据景民昌等提出的基于借阅时间评分的兴趣模型将这些用户对图书的借阅记录转换成用户对于图书的评分,此处不做具体说明。
3.2实验设计
我们采用基于内容的推荐算法对标签处理的效果进行评估,主要通过对模糊标签去除前后推荐算法准确率对比的方式来实现。首先我们根据公式4计算各个标签的模糊度值,选取合理的模糊度识别阈值进行模糊标签的去除。然后进行推荐效果的测试,评估标签模糊去除对于推荐效果的影响,进一步评估该模糊标签识别方法的准确性。
关于基于内容的推荐算法的实验步骤说明如下:
(1)计算图书-图书相似度矩阵;
(2)将图书借阅记录数据根据时间先后顺序按9:1的比例划分为训练集和测试集;
(3)根据训练集给用户推荐图书,根据测试集来评判推荐图书的准确率;
3.3结果评价
从图4可知,标签的模糊度值总体上来说较低,这和本文采用较粗的资源分类策略必不可分。在这种策略下,我们可以较为肯定地确认拥有较高模糊度值的标签就是需要处理的模糊标签。由图3可知,模糊度值为1的标签具有较为明显的二义性。此处我们将模糊度识别阈值a设为1,即模糊度值高于1的标签为模糊标签。将这些模糊标签归类到对应的模糊标签集中。接下来对模糊标签处理效果进行实验评估。
由推荐结果图5可以非常明显地看出,模糊标签处理操作对于提升推荐的准确率具有非常积极地作用。在推荐列表长度为1的时候,由于推荐总量较低,因而可以观测到较为明显的准确率差值。在这个点处理前的推荐准确率为13.37%,处理后的准确率为16.05%,提升了2.7%左右。通过实验分析可以知道本文中模糊标签处理方法具有较好的标签模糊去除能力。同时,由处理前的推荐准确率也可知道,将虚拟图书与实体图书相结合,的确可以为图书补充特征,使基于内容的推荐在图书推荐场景下得以应用。
4 结语
本文提出了一种将虚拟图书特征(图书的社会化标签)与实体图书相结合的方法来解决实体图书特征项稀少的问题,以此使基于内容的推荐在高校图书馆场景下得以应用。对于社会化标签模糊的问题,本文以信息熵的思想为基础提出了一种模糊标签识别方法,并通过基于内容的推荐算法来测试模糊标签去除前后推荐的准确率,以此来判定模糊标签识别方法的准确性。实验结果证明,模糊标签的去除对于提升推荐算法的准确率具有积极的作用,说明该模糊标签识别方法具有较好的模糊标签识别能力。
- 基于数据虚拟化技术的大数据资源中心建设
- 基于个性化推荐的选题系统的设计与实现
- 基于Android的老人智能监护系统的设计与实现
- 基于卷积神经网络的图像清晰度识别方法
- 改进模拟退火算法在TSP中的应用
- 大型综合单位UPS电源的选型配置与管理维护
- 基于CMMI的软件项目管理平台研究与设计
- 对《JSP程序设计》课程的教学改革研究和探索
- 基于改进Teitz—Bart算法的移动网络物流配送系统
- 融入企业应用及系统观的Java系列课程教学改革理念构建
- 数字三维皮影动画的设计与实现
- 基于Web的预算项目管理系统设计与实现
- 基于RS232C通信和以太网通信的称重管理系统设计
- 数据仓库下基于知识库的虚拟实验平台构建
- MVP模式在Alldroid中的应用研究
- AJAX技术在手势识别系统中的应用
- 3X+1问题中扩展Collatz模型的环结构研究
- 基于SAP2000的通信三管塔风荷载加载方法研究
- 对称正则长水波方程的畸形波解
- 基于IOS平台的拼图游戏开发
- 一种加权模糊C中心聚类新算法
- 基于微信平台的高职专业核心课程微平台设计
- Rosenbrock搜索法在聚类分析中的研究
- 云计算环境下的电子签名服务研究
- 自营电商在配送过程中的最小运费问题
- goof
- goof around
- goofed
- go off
- go off/go bad
- go off (on somebody)
- go off sb/sth
- go off somebody/something
- go off with
- go off (with sb)
- go off with sth
- go off with/walk off with
- goof/goof ball
- goof/goof up
- goofier
- goofiest
- goofily
- goofiness
- goofinesses
- goofing
- goof off
- goofs
- goofy
- goof²
- goof¹
- 塼
- 塽
- 塾
- 塾地
- 塾师
- 塾师的束修或幕宾的酬金
- 塾掌
- 塿
- 墀
- 墁
- 墁壁
- 境
- 境内
- 境内多沼泽之国
- 境内证券
- 境况
- 境况不好的人
- 境况和情味
- 境况和遭遇
- 境况好转
- 境况窘迫
- 境况逐渐好转或兴趣逐渐浓厚
- 境土
- 境地
- 境域