代鹏
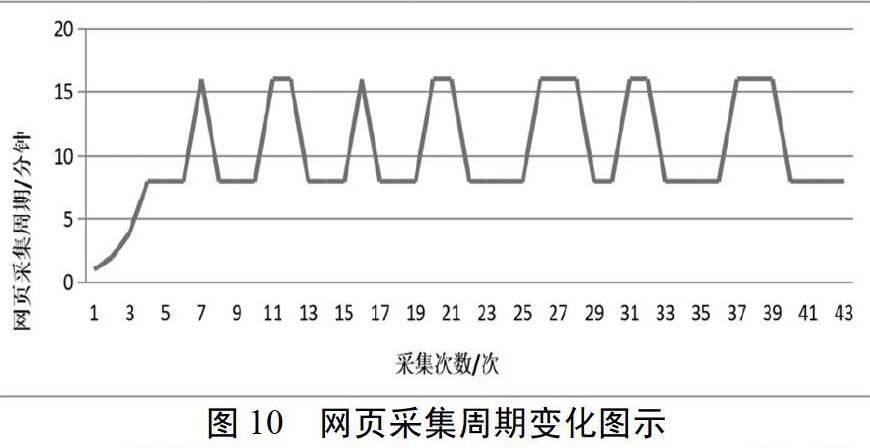
摘要:本文介绍了Nutch网络爬虫的系统架构和抓取网页信息流程,针对Nutch网页信息数据采集冗余的问题,引入了增量更新方法和适应性采集周期计算方法,首先使用Simhash算法和汉明距离计算出网页相似度,根据网页相似度计算出网页采集周期,然后根据此周期进行网页信息采集,在采集前根据网页元信息中的网页内容长度与网页最后更新时间的变化与否判断是否进行采集。实验结果表明,随着采集次数的增多,网页采集周期会在真实网络变化周期上下浮动,使得网页采集周期与真实网页变化周期之间较为接近,最终有效的减少了冗余的网页信息采集数据量,减轻了对网络环境的压力,实现了适应性的增量的网页信息采集过程。
关键词:计算机软件与理论;Nutch;Simhash;汉明距离;增量采集方法
中图分类号:TP311.5
文献标识码:A
DOI: 10.3969/j.issn.1003-6970.2015.11.025
0 引言
目前,互联网资源成指数级增长,仅就国内方面,根据中国互联网信息中心发布的数据,截至2014年12月,中国网页数量为1899亿个,年增长26.6%。面对如此庞大的网络资源,搜索引擎需要依赖于高效的网络爬虫进行网络信息采集。
网络爬虫的采集策略主要分为以下几种:基于整个Web的信息采集(Scaleble Web Crawling),增量式Web信息采集(Incremental Web Crawling),基于主题的Web信息采集(Focused Web Crawling),基于元搜索的信息采集(Metasearch Web Crawling),基于用户个性化的信息采集(Customized Web Crawling),基于Agent的信息采集(Agent Based Web Crawling)。随着网络资源的迅速增长,增量式的Web信息采集显示出越来越大的优势,相比其他的周期性全部采集的方式,可以极大的减少数据采集量和数据冗余。增量的网页信息采集技术成为获取网页信息的一种有效且必要的手段。
本文设计与实现了一种增量采集方法和一种计算网页采集周期的方法。通过使用Simhash算法与汉明距离计算出网页相似度,根据网页相似度计算出网页采集周期,在采集前根据网页元信息中的网页内容长度与网页最后更新时间判断是否进行此次采集,最后在Nutch网络爬虫基础上,实现了网页信息的增量采集功能。
1 相关技术介绍
1.1 Web网络爬虫
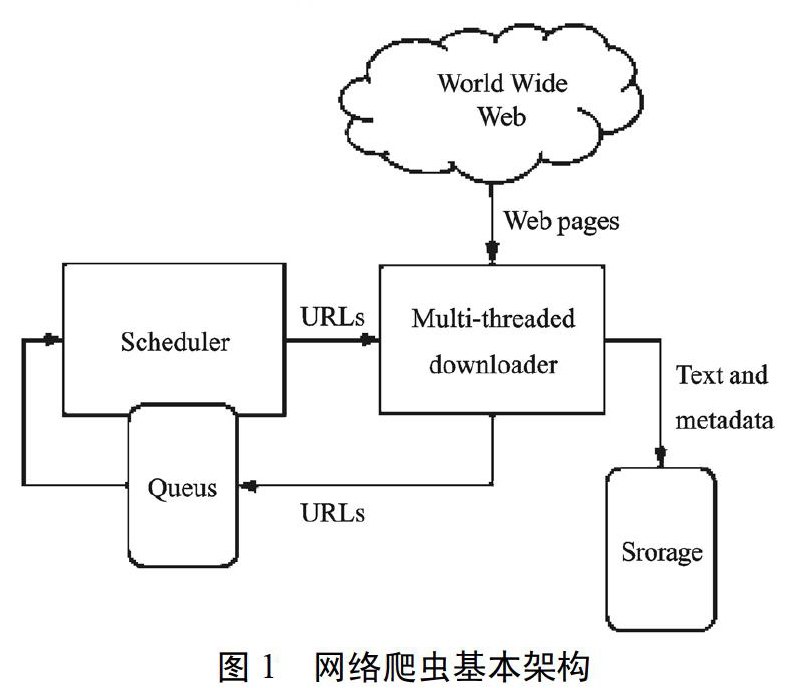
Web网络爬虫是一种自动的采集网页的程序,一个典型的爬虫从一组URLs开始,这组URLs称为种子地址,首先网络爬虫会从种子地址开始采集网页,然后将网页中地址解析出来放到待采集地址队列中,然后网络爬虫以某种顺序(深度优先、广度优先、优先队列等)从待采集地址队列中获取地址,然后重复上述过程。
如图l是爬虫的基本架构:
1.2 Nutch
Nutch作为当前最流行的开源爬虫之一,已经广泛应用于企业产品中,目前Nutch的l.x版本中,从1.3版本本身就主要只有爬虫功能。
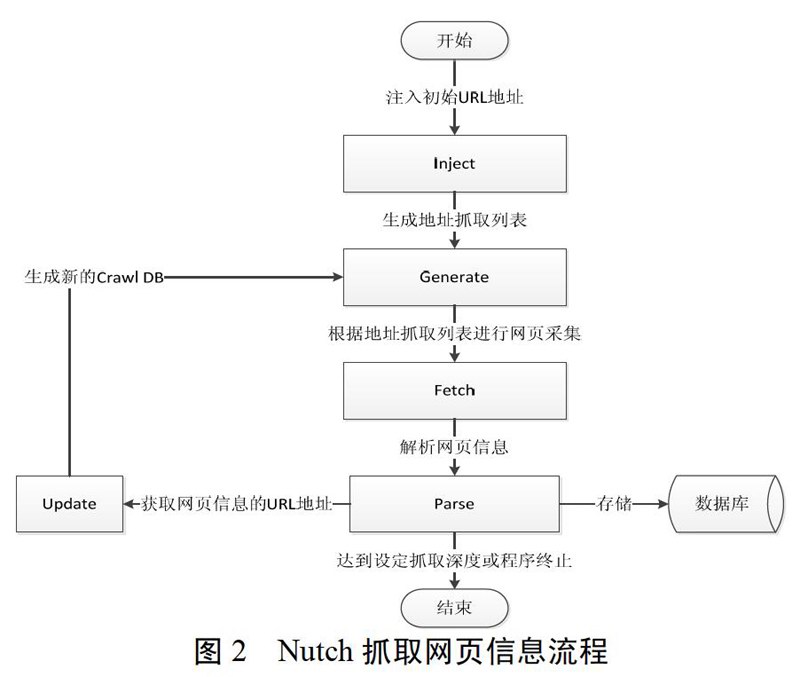
Nutch的具体工作流程如下:
1)将种子文件中的URL地址输入到Crawl DB中,作为采集的初始地址。
2)从Crawl DB中按照某种顺序获取下一次需要抓取的地址列表。
3)根据地址列表进行网页信息抓取。
4)解析网页信息。
5)更新Crawl DB库。
6)重复2-5步,直到达到抓取深度或终止程序。
具体过程如图2所示:
Nutch为了增强可扩展性、灵活性与可维护性,使用了插件系统,编写一个插件实际上是给已经定义好的扩展点增加一个或多个扩展,核心的扩展点有Parser、HtmlParseFilter、Protocol、URLFilter等。根据本文的需求,可以实现通过实Parser扩展点开发简单的插件,进行实验验证。
1.3 汉明距离
在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数,换言之,即将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:“1011101”与“1001001”之间的汉明距离是2。“Toned”与“roses”之间的汉明距离是3。
在下面的Simhash算法中使用汉明距离来判断网页之间的相似性。
1.4 Simhash算法
在传统的文本相似度比较技术中,典型的方法是将一篇文章的特征词映射到高维空间,即这篇文章的向量,然后计算出每篇文章的向量,根据向量之间的距离来判断文章的相似度。但这种方法存在一个问题,如果文章的特征词特别多就会导致整个向量的维度很高,使得整个计算的代价很大,而且这种方法需要对所有的文章进行两两比较,从而产生了非常大的计算代价。在少量的数据情况下,这种方法是可以接受的,但在大量的数据情况下,对于Google这种处理万亿级别的网页的搜索引擎是很难接受的,Google为了解决这种问题采用了基于降维思想的Simhash算法。
Simhash的主要思想就是降维,将高维的的特征向量映射成一个f-bit的指纹(fingerprint),通过比较两个文章的f-bit的指纹的汉明距离来确定两篇文章是否重复或者高度近似。
2 系统设计
针对本文的具体需求,结合Nutch系统,精简了其中的有关索引、反转链接的模块,在数据存储中添加了URL存储元信息,对Parser模块进行了重写,在Parser模块中主要添加了增量更新方法和网页采集周期计算的方法。最终设计的系统主要包含7个模块。
2.1 网页采集系统功能模块图
- 浅谈财务风险防范的战略预算管理评价与优化
- 浅析财务人员职业道德修养的重要性
- 研发支出资本化问题探讨
- 企业成本控制与优化研究
- 加油站建设投资风险分析及控制策略
- 推行精益生产 推动卓越绩效管理战略落地
- 试论成本控制在报社发行管理中的方法与对策
- 电力施工企业的项目成本控制优化论述
- 同步移送机构中的曲轴的制作加工工艺探讨
- 基于计量模型对人才竞争、制度竞争和城市经济发展三者关系的研究
- 浅谈环境设计中的装置艺术
- 如何加强企业党员干部廉洁自律的探索
- 探讨重视纪检监察工作在党建中的作用
- 新时期国企党建工作面临的挑战与对策
- 高速公路施工安全管理规范化的分析及对策
- 建设工程项目管理的风险分析及防范探讨
- 浅谈建设单位项目管理存在的问题及对策
- 探讨建筑工程经济成本管理的重点
- 如何做好新时期学校统计工作创新
- GM对CPI指数的影响因子分析
- 一种制造业与服务业人才流动的数据分析模型
- 浅谈事业单位绩效管理考核
- 人力资源管理中的资源管理
- 浅析传媒企业员工激励的影响因素及对策
- 浅谈提升基层职工教育培训质量
- householderships
- householdname
- household name
- household product
- householdproduct
- householdry
- households
- householdword
- household word
- household²
- household¹
- house husband
- housekeeper
- housekeeperlike
- housekeepers
- housekeeping
- housekeepings
- houselessness
- houselessnesses
- houseman
- houseman's
- housemanship
- housemen
- housemen's
- house music
- 信鸿
- 信鼓
- 信,国之宝也
- 俢甬
- 俣
- 俣俣
- 俥
- 俦
- 俦与
- 俦丽
- 俦亚
- 俦人
- 俦伍
- 俦伦
- 俦伴
- 俦侣
- 俦党侪类
- 俦列
- 俦匹
- 俦类
- 俦辈
- 俨
- 俨乎
- 俨乎其然
- 俨俨