

摘要: 随着移动互联网技术的发展,像拍照赚钱等自助式劳务空间众包平台变得日益盛行。该文通过给出的拍照任务数据,分析得到商品的任务定价规律,找出任务未完成的原因,再通过比较原标价方案,给项目设计出一个合理的任务标价方案。
Abstract: With the development of mobile Internet technology, self-service labor crowdsourcing platforms like photo-making earn money become more and more popular. Through the given camera task data, the article analyzes the task pricing rules of goods, finds out the reason of the task is not completed, and then designs a reasonable task price plan for the project by comparing the original price plan.
关键词: 拍照赚钱;任务定价;多元线性回归;聚类分析;0-1检验;二元Logistic回归
Key words: take pictures to make money;task pricing;multiple linear regression;cluster analysis;0-1 test;binary Logistic regression
中图分类号:F272.1;F224 文献标识码:A 文章编号:1006-4311(2018)19-0085-06
0 引言
“拍照赚钱”是当下使用互联网来完成指定任务从而获得酬劳的新兴服务模式,同时带给公司与客户之间的合作新机遇。用户对道路两旁街景、店铺,或是某种商品上架的拍摄,并且成功上传图片,就可获得对任务所标定的佣金。用户也可以承包某个区域,也就是说,这个区域的拍照任务联合在一起拍摄,这样也会得到已经标定的对应佣金。随着互联网的普及越来越大,用户的创新创业热情以及能力蕴藏着巨大能量和价值,劳务众包平台能大大降低调查成本,打破传统企业创新来源的局限,在范围内寻求各用户创意支持,增加大众的积极性,充分运用公众的智慧,同时有效保证了拍照数据的真实性,缩短了拍照的调查周期。
APP对任务的合理标价以及拍照商品的位置和会员信息等是任务完成情况的重要要素。会员离拍摄商品距离远,定价不合理等,都会导致拍摄任务完成情况不佳,而会员的地理位置、预定任务开始时间、预定限额、信誉值也对任务的完成情况有重要影响[1]。
“拍照赚钱”模式的发展合理有效的扩大了电商的营业范围,逐渐形成了一个全新的“无形商品”电子商务运营模式。这种模式迅速的崛起,但是理论研究明显落后于社会实践要求导致这种众包平台在进一步的发展中明显受阻[2,3],所以建立众包平台的出价是一种新兴的服务标价模型,它的建立大大丰富了服务标价理论,具有十分强劲的理论实践意义。
1 指标体系的构建
针对真实生活场景,根据深圳和广州地区某一任务的任务及会员信息(任务信息包括:任务位置(GPS)、任务标价、任务执行情况。会员信息包括:会员位置(GPS)、预订任务限额、预订任务开始时间、信誉值)探讨影响“拍照赚钱”任务定价的因素,给出从区域位置问题、用户收益问题、人力问题三个维度探讨拍照任务定价因素。
1.1 潜在价格影响因素分析[4]
对众包平台软件任务进行分析,从区域位置问题、收益问题、人力问题三个维度提出5个可能影响软件众包价格因素的潜在因素。各个因素的度量方法及统计描述属性如图1所示。
1.2 聚类分析
对样品和指标(变量)进行分类主要采用聚类分析法,而求取样品以及类之间的距离有多种方法,其中主要使用欧式距离和最短距离法。
1.2.1 数据标准化
由于所选数据的量纲和数值大小都不一致,数值的变化范围也不同,因此必须首先对所选数据进行标准化处理,如果有n个样本,n个样本有m个指标,且每个变量可表示为xij,均值为
1.2.2 聚类
距离:对样品进行聚类时,“靠近”往往由某种距离来刻画。若每个样品有p个指标,故每个样品可以看成p维空间中的一个点, n个样品就组成p维空间中的n个點,样品与指标构成一个矩阵,此时就可以用距离来度量样品之间的接近程度。
令xij表示第i个样品的第j个指标, dij表示第i个样品与第j个样品之间的距离,最常见最直观的计算距离的方法是:
当各变量的测量值相差悬殊时,为了计算的准确性,需先将数据标准化,然后用标准化后的数据进行计算。
根据K-means聚类,对会员的位置信息(GPS)进行聚类,得到6个聚类中心的位置以及6个类别的会员数量及位置,如表1。
1.3 相关性分析
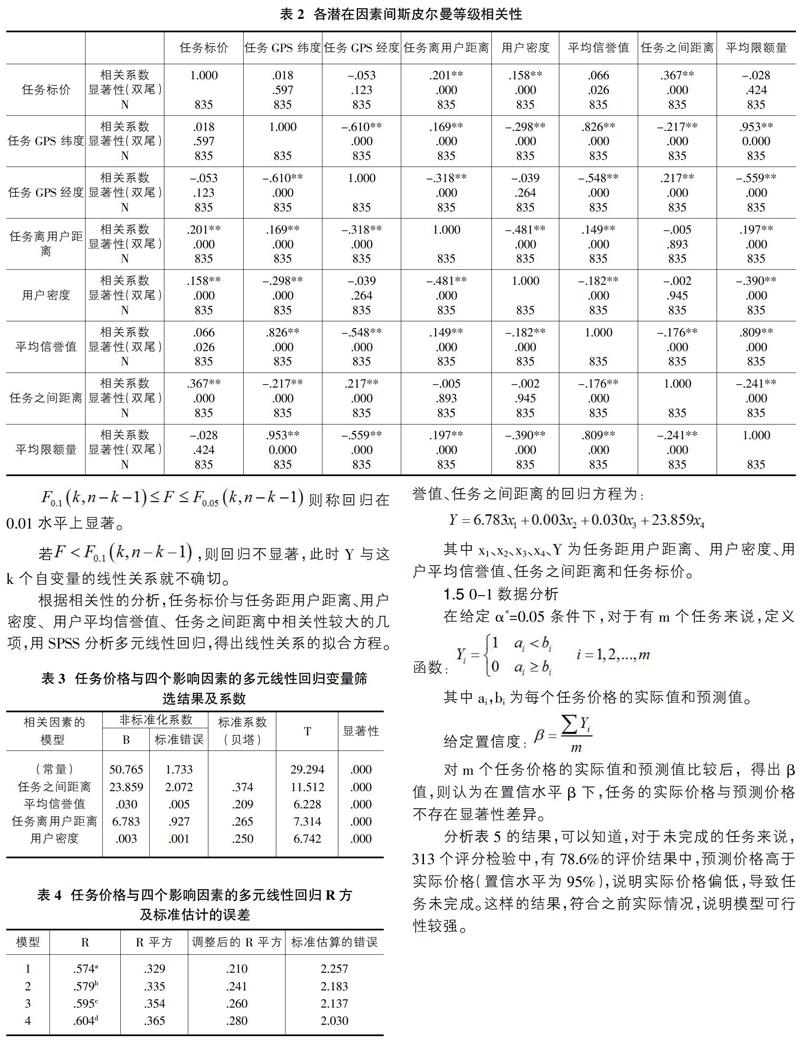
相关分析是描述两个变量间关系的密切程度,主要由相关系数值表示,当相关系数r的绝对值越接近于1,则表示两个变量间的相关性越显著。双变量系数测量的主要指标有卡方类测量、Spearman相关系数、Pearson相关系数等,由于项目任务的经纬度数据为定距数据,则在进行两者间的相关性检验时用其中t统计量服从n-2个自由度的t分布。
软件众包任务标价与各潜在因素之间的Pearson相关性分析计算结果详见表2。在0.05的显著性水平下,与软件众包任务标价显著相关的因素包括:任务距用户距离x1、用户密度x2、用户平均信誉值x3、任务之间距离x4。
1.4 多元线性回归模型
多元回归分析是研究多个变量之间关系的回归分析方法,确定变量之间数量的可能形式,并用数学模型表示如下:
式中b0为截据;b1,…,bk为偏回归系数;?着为残差;
其中多元模型的矩阵表达式:
根据R方值的大小,可判断出多元线性回归方程的契合度,观察模型后退5次得到R方值与标准估计的误差,R2=0.715,可知方程的吻合性较高。
考虑到与软件众包标价显著相关的因素间有可能出现彼此相关,即因素间不独立的情况,如果直接使用这些因素建立多元回归模型,模型中将出现多重共线性,造成回归结果混乱。为了消除多重共线性对分析结果的干扰,我们采用具有最优变量筛选效果的逐步回归方法建立分析模型,不停地增加变量并考虑剔除之前的变量的可能性,直至增加变量已经不能导致模型的残差平方和显著减少(F统计量检验不通过)或增加任一变量,该变量对标价的影响均不显著(t统计量检验不通过)。逐步回归不仅使模型变得简单,还使自变量对因变量的影响清晰地展现出来,结果更可信,也更容易解释。使用逐步回归方法建立软件众包标价分析模型的过程中自变量逐个引入,边引入边检查有没有可能剔除某个变量。
建立模型,要对模型进行拟合度检验,回归方程的显著性检验就是检验样本回归方程的变量的线性关系是否显著,即能否根据样本来推断总体回归方程中的多个回归系数中至少有一个不等于0,主要是说明样本回归方程R2的显著性。检验的方法用方差分析,这时因变量Y的总体变异系本分解为回归平方和与误差平方和,即表示为:
根据相关性的分析,任务标价与任务距用户距离、用户密度、用户平均信誉值、任务之间距离中相关性较大的几项,用SPSS分析多元线性回归,得出线性关系的拟合方程。
根据表4中R方值的大小,可判断出多元线性回归方程的契合度,观察模型后退4次得到R方值与标准估计的误差,R2=0.604,可知方程的吻合性较高。最后由表5得到任务标价与任务距用户距离、用户密度、用户平均信誉值、任务之间距离的回归方程为:
对m个任务价格的实际值和预测值比较后,得出β值,则认为在置信水平β下,任务的实际价格与预测价格不存在显著性差异。
分析表5的结果,可以知道,对于未完成的任务来说,313个评分检验中,有78.6%的评价结果中,预测价格高于实际价格(置信水平为95%),说明实际价格偏低,导致任务未完成。这样的结果,符合之前实际情况,说明模型可行性较强。
1.6 未完成原因的分析
根据模型以及图2的分析,任务未完成主要是由于:①对比任务完成点距离用户与未完成点的距离,可以得到未完成任务点距用户的距离较已完成点偏远,可能是由于用户往往不太愿意前往距离远的地区;②用户密度高的区域相比低密度区域任务完成情况较好,大多因为同一个任务点被多个用户共同预定,大大提高了该点任务的完成度;③用户信誉值较高的区域任务完成度普遍较好,良好的用户信誉值保障了该点的任务即使被用户接单而不违约,则任务完成情况有所提高;④任务之间距离过大的区域相比任务间距密集区的用户接单情况鲜有问津,故完成度不高,往往是用户会因为完成其中一点任务而难以继续完成另一点任务,或者是两点任务都难以完成,最终放弃这两点的任务,弃单也会导致任务未完成。同时,不同地区的GDP值,地区之间的地形差异,交通发达情况,高程情况都有可能导致任务未完成。
2 优化定价模型
2.1 选取影响因素的原则
完备性、客观及可操作性原则。影响因素体系作为一个完整体系,可以从不同的方面反映任务定价不同,也可以反映整个任务定价的实时变化,保证回归结果的客观准确性,体现不同影响因素对APP拍照赚钱任务定价的影响。影响因素体系的建立需要保证在实际的运用中能够体现其价值所在,所以选取每个因素都必须具有可操作性,从而使得整个影响因素体系简明,易操作有实际应用功能。
映射原则。有时评价任务定价的某个目标时,很难找到直接反映该问题的指标,这时我们可以从目标实现所需要的某些现象进行相关的映射提炼,即哪些现象可以反映我们所需的目标的变化情况。
2.2 选取过程
影响因素的选取是一个抽象具体事物和反复锤炼的逻辑思维判断过程。在寻求新的任务定价时,任务和会员地理位置、会员信息、实际地域的交通、经济、地形差异等都会影响到对任务的定价影响,这就需要我们对复杂的指标进行精确的筛选。
根据指标的选取原则,构建的影响因素体系如图3所示。
根据图3,我们可以看出,为了构建合理实际的任务定价因素体系,我们选取了八个影响因素,分别为:任务距用户距离,单位区域用户密度,用户平均信誉值,任务之间相隔距离,区域的GDP总值,任务点附近的城市道路网密度,会员抢单时间,任务点附近的用户限额总量。
2.3 相关性分析
双变量系数主要测量指标有很多,Pearson相关数据适用于联合分布为二维正态分布的两个随机变量,Spearman相关系数对变量分布没有要求。项目任务的各个数据的潜在因素与参与度的联合分布不一定满足正态分布,因此检验时使用Spearman相关系数度量各潜在因素与参与度之间的相关性。Spearman相关系数计算时需先对数据排秩,其计算公式为:
其中t检验服从自由度为n-2的t分布。考虑到与软件众包标价显著相关的因素间有可能。
2.4 影响因素的分析处理
2.4.1 定性分析
定性分析,是指依据现实验和主、客观分析方法,对于某种事物的本质属性、发展趋势或多种事物之间的相关关系给予直观、概括性表述的一种分析方法。结合问题一,八个因素对任务定价都有一定影响。任务距用户距离越近,用户越有可能接单;单位区域用户密度高,则接单的用户也会增多;较高的会员信誉值大大保证了接单用户会及时完成接单任务;任务之间相隔距离远会降低用户接单兴致,可能使得任务流单;区域的GDP总值可以间接表明该区域中的用户数量,用户接單执行情况等信息;任务点附近的城市道路网密度越大,该区域用户接单并完成越方便,可以加强该区域用户的接单率;会员较早的抢单,则会更早的选择较有利的任务位置,将接单情况将更好;任务点附近的用户限额如果偏低,将抑制该区域任务接单并完成水平,说明较高的用户限额是有利的。
2.4.2 定量分析
①区域的GDP总值。把各个任务点的地理位置导入google地图,利用智能交互软件定位出每个位置所属于的城市及区域,采集题中所给任务点经纬度数据,全都对应落在了广东省深圳市的南山区、宝安区、盐田区、福田区、罗湖区、龙岗区,和广东省广州市天河区、增城区、黄埔区、萝岗区、番禺区、海珠区、白云区、荔湾区、南沙区、越秀区、花都区、从化区,以及东莞市、佛山市、清远市和惠州市之中。收集这些行政区域2016年的GDP总量数据资料[6,7],并对任务点的位置与GDP数据一一配对组合。
②任务点附近的城市道路网密度。是指任一任务点周围一定面积下依道路网内的道路中心线长度与依道路网所服务的用地面积之比,利用Python编程,结合google智能交互软件对每一任务点,及任务点周边道路长度和用地面积的精确定位,任务标价低区对应着交通密集区,把计算得出的每一个任务点道路网密度与该点位置一一匹配组合。
③会员抢单时间。定义为在一定区域范围内所有会员订单抢单时间的平均值与这个区域内任一一点的抢单时间的差值,先把所有抢单时间的单位转化为“天”,利用Python分析计算得到每一任务点的会员抢单时间,再与该点经纬度位置一一组合。
④任务点附近的用户限额总量。在一定区域范围内所有会员订单限额之和。
2.4.3 二元Logistic回归模型
Logistic回归属于概率型非线性回归,它是研究二分类观察结果与一些影响因素之间关系的一种多变量分析方法。例如,在流行病学研究中,经常需要分析疾病与各危险因素之间的定量关系,为了正确说明关系,需要排除一些混杂因素的影响。对于线性回归分析,由于应变量Y是一个二值变量(通常取值1或0),不满足应用条件,尤其当各因素都处于低水平或高水平时,预测值Y值可能超出0~1范围,出现不合理都现象。用Logistic回归分析则可以较好的解决上述问题。Logistic回归模型的基本形式如下:
因此,对因变量P按照ln(P/(1-P))的形式进行对数变换,可以将Logistic回归问题转化为线性回归问题,在按照多元线性回归的方法求解回归参数。对于P取值只有0和1的情况,在实际中不是直接对P进行回归,而是先定义一个单调连续的概率函数π:
然后只需要对原始数据进行合理的映射处理,就可以用线性回归方法得到回归系数,最后再根据π和P的映射关系进行反映射得到P的值。
2.5 模型的求解
2.5.1 数据计算
根据公式任务点附近的城市道路网密度?籽=l/S
其中,L为路网内道路总长度;S为路网所服务的用地面积
其中,in为在一定区域范围内某一个会员的订单限额。
2.5.2 相关性分析
通过Matlab计算得到各个影响因素的值。软件众包任务标价与各潜在因素之间的Spearman相关性分析计算结果详见表6。在0.05的显著性水平下,与软件众包任务标价显著相关的因素包括:任务距用户距离x1、用户密度x2、用户平均信誉值x3、任务之间距离x4、区域的GDP总值x5、任务点附近的城市道路网密度x6、会员抢单时间x7、任务点附近的用户限额总量x8。
从任务标价分析与任务限额总量因素的相关系分析,得出与抢单时间、路网密度、任务地区GDP相关性较为显著,任务限额总量与任务标价的相关性r=0.056>0.05,所以任务限额总量与任务标价关系显著性较差,将任务限额总量因素剔除。
根据表7中R方值的大小,可判断出多元线性回归方程的契合度,观察模型后退4次得到R方值与标准估计的误差,R2=0.537,可知方程的吻合性较高。结合问题一,最后得到任务标价与任务距用户距离x1、用户密度x2、用户平均信誉值x3、任务之间距离x4、区域的GDP总值x5、任务点附近的城市道路网密度x6、会员抢单时间x7的回归方程为:
2.5.3 Logistic回归
先验数据的处理:
首先将附件一中的任务完成情况作为历史完成情况来分析,根据合理推断,在任务点历史情况中处于完成情况下,如果设计的新定价比任务历史价格高,那么该点实际情况一定也是完成。同理,也可以推断出,在历史情况中任务处于未完成情况下,如果任务点的新定价比历史价格低,那么该点实际情况一定也是未完成。根据这种推理,我们将新的定价方案价格和附件价格对比,根据附件数据的完成情况分析得到了404组先验数据。接下来我们利用SPSS软件以任务完成情况作为因变量、定价影响因素作为自变量建立二元Logistic回归模型,根据404组先验数据,预测得到剩下的423组数据,最后综合先验数据与预测数据发现新定价方案任务完成率(完成的任务个数占总任务个数的比例)相比原方案提升了6.47%。
根据模型与原方案的对比,新任务定价方案考虑了:增加区域的GDP总值因素,相比之前更加精确的表明了该区域中的用户数量,用户接单执行情况等信息;如果任务点附近的城市道路网密度增大,则该区域用户更容易接单,更想接单;会员越早抢单则会越早的选择较有利的任务位置,抢单时间一个重要影响因素;任务点附近的用户对预定任务的限额也会影响任务定价,说明较高的用户限额量有利。
3 模型的推广
移动互联网的自助式劳务众包平台是目前基于“互联网+”平台的O2O(offlinc-to-online)经营模式,因此该平台在市场上具有广泛的应用前景。此定价模型可以广泛应用于社会经济的各个领域内,不仅适用于分析不同位置APP定价高低程度,还可推广运用于出租车资源的“供求匹配”模型,以及国际油价行走趋势研究等定价用户需求关系的情况中。
参考文献:
[1]刘晓钢.众包中任务发布者出价行为的影响因素研究[D].重庆大学,2012.
[2]高铭,王毅.众包项目风险评估模型研究[J].管理現代化,2016(03):105-107.
[3]孙信昕.众包环境下的任务分配技术研究[D].扬州大学,2016.
[4]安思锦,翟健.软件众包参与度影响因素分析及预测模型[J].计算机系统应用,2015(10):9-16.
- 新课改下教育教学的“三自”学生观
- 新课程标准理念下初中化学实验教学的探索与实施
- 初三化学教学中生活化知识教学的实践与探讨
- 初中生物生活化教学的实施路径
- 初中物理核心素养教学的构建
- “预设”与“生成”共舞,智慧与激情齐飞
- 核心素养理念下的初中数学课堂教学
- 基于核心素养下的初中数学模型思想的培养
- 数学课堂教学中学科素质与学科核心素养初探
- 基于核心素养下中学数学有效课堂教学研究
- 基于核心素养培养下的初中数学教学
- 初中地理生活化教学浅析
- 基于核心素养提升探究初中道德与法治教学
- 初中英语教学的有效方法探究
- 农村寄宿制初中语文综合性学习的实践探究
- 基于新课改背景下初中语文教学中情感教育探究
- 新课程标准下的初中语文阅读教学策略
- 让阅读成为语文课堂教学的主旋律
- 化学合作学习模式研究
- 改进化学实验 创新器材使用
- “任务驱动式”合作学习在中学物理教学中的应用研究
- 初中物理创新实验教学的现状及对策分析
- 新课改下农村初中数学教学中创新策略研究
- 初中数学教学中的合作模式构建研究
- 新课程标准下初中数学教学模式的优化创新
- sveltenesses
- svelter
- sveltest
- sw
- swab
- swabbed
- swabbing
- swabs
- swagger
- swaggered
- swaggerers
- swaggering
- swaggeringly
- swaggers
- swaggery
- swahili
- swallow
- swallow-diving
- swallowed
- swallowers
- swallow hole
- swallowing
- swallowlike
- swallow-like
- swallows
- 滋补阴虚
- 滋议
- 滋长
- 滋长茂盛
- 滋阜
- 滋阴
- 滋静
- 滌
- 滌蕩
- 滍
- 滍水
- 滎
- 滏
- 滏水集
- 滏阳河
- 滑
- 滑一趟
- 滑上加滑
- 滑不到哪里去
- 滑不唧溜
- 滑不溜
- 滑不溜秋
- 滑不溜鳅
- 滑串子
- 滑串流口