周莹
【摘要】 本文在对零拷贝技术改进的基础上提出了一种适应不同网络负载环境下的自适应的数据捕获方法,重点介绍了其实现的关键技术、数据捕获整体结构,自适应数据捕获方法使用范围更广、在同等条件下有效的减轻了CPU的负荷,提高了数据捕获的效率。
【关键词】 自适应 数据捕获 Linux系統
一、引言
网络数据捕获是网络安全性分析过程中一种常用的方法,一般采用NAPI中断轮询机制、零拷贝技术和TOE等关键方法来提升数据捕获的性能,但是这些方案在实际应用中存在适用范围小性能提升有限等问题。本文提出了自适应网络数据捕获方法,实现一种应用范围更广的数据捕获方案。
二、自适应数据捕获及其关键技术
为了提高数据捕获的效率,适应不同的网络环境,本文在零拷贝的基础上提出一种自适应的网络数据捕获机制。
2.1 自适应网络数据捕获整体结构
与零拷贝技术相比,将接口程序中队列中的去写数据的方式从硬件中断方式改为轮询方式,设定自适应的轮询定时器,采用自适应的方式根据流量大小对定时器的工作时间进行调整,如果网络中数据流量较大时则增大定时器的定时时间间隔,如果流量较小时则减小定时器定时时间。通过这种方式可以减小中断带来的系统开销,同时能够根据不同的网络环境适时调整轮询频率,及时高效的处理网络数据。
2.2 自适应定时器
自适应网络数据捕获方法减少中断次数的关键就是根据网络流量大小修正轮询时定时器计时的时间间隔。其核心是根据已经采集的数据流量大小预测定下一次定时器启动的时间。在预测时间时首先按照一定的时间间隔采集当前网络流量大小得到一个连续的时间序列,网络流量数据可以用如下数据形式描述:
X={x1,x2,x3,…xt,t=1,2,3…}
其中xt表示网络中t到t+1时刻网络中数据流量大小,X表示为连续的网络流量时间序列。网络流量预测根据过去的现在已知的或者非确定的网络流量状态建立一个网络流量预测模型从而预测未来的流量,可以用如下函数表示: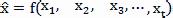
其中为其与预测值。为了不增加额外的开销,在流量预测时使用计算相对简单预测也较准确的基于数理统计的泊松过程模型。
2.3 内存地址映射
为了避免数据在内存之间的拷贝,在用户和内核中设置了一块共享的缓冲区,但是用户程序所使用的地址和硬件使用的物理地址是不相同的。Linux操作系统中每个应用程序维护一个多级页表来实现地址之间的转换。
内存地址转换时首先将用户缓冲区UserBuff经过页对齐之后的首地址传入内核中并以此为首地址逐级映射到物理地址表phy_addr_table。物理地址表phy_addr_table一旦初始化后就锁定不可更改。具体过程如下:
For(i=0;i<(BUFF_BLK_NUM)>>1);i++,addr+=PAGE_SIZE)
经过映射之后,用户就可以直接访问送入Phy_addr_ table中的网络数据包。
三、测试
为了对自适应网络数据数据捕获方法进行进一步分析,对整个系统进行了测试。测试是使用linux2.6.21操作系统,realtek rtl8168 8111网卡,CPU为Intel(R) i3-2100 CPU。为了测试自适应数据捕获系统的性能,测试了64字节小包发送不同速率的数据包对CPU资源的占用情况,测试结果如表1所示:
测试结果表明,自适应的网络数据捕获方法在不同的数据流量大小情况下占用CPU的资源均比使用libpcap库和零拷贝技术时要小,尤其是在发包数量大道150万个/s的情况下采用libpcap库和零拷贝机制的CPU使用率达到将近100%,自适应数据捕获CPU使用率仍然相对较低。
四、结束语
本文在对零拷贝技术的改进的基础上提出了一种适应不同网络负载环境下的自适应的数据捕获方法,相比较与其他数据捕获机制,自适应数据捕获方法使用范围更广、在同等条件下有效的减轻了CPU的负荷,提高了数据捕获的效率。
参 考 文 献
[1]马博.Linux下的高流量数据包监听技术[J].计算机应用,2009,29(5):1244-1250
[2]刘文涛.网络安全开发包详解[M].北京:电子工业出版社,2011
- 健美操社团对促进高职校园体育文化建设的研究
- 体育之道“核”之为引
- 试析如何对青少年进行足球运动体能训练的探究
- 浅谈新课标下小学体育教学方法的探究
- 新课程改革下小学体育课堂教学策略研究
- 街舞在高校体育文化建设中的作用
- 幼儿园体育活动存在的问题及解决办法
- 河套学院足球啦啦操运动的创新性研究
- 初探幼儿园体育游戏中教师的介入时机
- 提出河套学院啦啦操教学中培养学生创编能力的合理设置的相应对策
- 分组教学法在普通高校教学中的创新应用研究
- 信息技术在体育教学中的应用探讨
- 多球供球节奏对乒乓球项目训练效果的影响研究
- 增强高校思政课堂吸引力的途径探究
- 项目教学法在汽车底盘实训中的应用
- 初中物理课堂提问的技巧与方法
- 高职院校生产性实训基地建设策略研究
- 浅析中职学生法律意识的培养
- 大学生网络兼职问题分析
- 小学弘扬儒家诚信理念,培养小学生诚实守信的优秀品质
- 关于中职教育如何服务地方经济发展的思考
- 现行高考模式弊端的调查与思考
- 农村中等专业学校涉农专业信息化教育的对策研究
- 论研究生学术能力的培养
- 新时代下教师授课思想的变革
- salarymen
- salarypackage
- salary package
- salaryprogression
- salary progˌression
- salary scale
- salaryscale
- sale
- saleability
- saleability,saleableness
- saleable
- saleably
- saleandleaseback
- sale and leaseback
- saleandrepurchaseagreement
- sale and repurchase aˌgreement
- saleasseen
- sale as seen
- salebydescription
- sale by description
- sale by sample
- salebysample
- saleorreturn
- sale or return
- sale price
- 消除顾虑
- 消除饥饿
- 消除,取消
- 消陨
- 消隐
- 消靡
- 消面虫
- 消音器
- 消颓
- 消食
- 消髀肉
- 消魂
- 消魂丧魄
- 消魂失魄
- 消魂夺魄
- 消黯
- 涉
- 涉世
- 涉临绝境的人
- 涉人
- 涉众型
- 涉众型经济犯罪
- 涉侨
- 涉儿
- 涉内