邓宗武
摘要:在数据发布中,数据发布的目的是为了其他企业或者组织等能够通过分析研究发布后的数据得到有价值的信息。然而数据的发布会泄露数据所有者的隐私信息,因此近几年来对于数据发布隐私保护的研究也越来越多。目前,在数据发布隐私保护方法中使用最多的是匿名化方法。该文通过结合特征选择领域知识,对数据发布在隐私保护和数据可用性上进行了研究,提出了将特征选择技术应用在数据发布隐私保护中,从待发布的数据属性中选择最有利于对数据发布有研究价值的数据属性,该方法降低了数据隐私泄露的风险,并且有利于数据挖掘。
关键词:数据发布;隐私保护;特征选择;微聚集
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)15-0001-02
1 概述
数据发布隐私保护的主要思想是在不泄露数据隐私和保持数据可用性之间寻找一种平衡[1]。数据发布的目的是为了数据的收集者(如个体、企业、政府等)进行分析研究然后做出相对应的措施来达到自己的目的。发布的数据的属性大都是多维的,如果所有的数据属性全部发布,数据的隐私泄露的几率非常高,同时数据的损失也会非常大,数据可用性大大降低,一些无关数据属性或者相关性较小的数据属性的发布会加大隐私泄露的几率且对于数据发布没有研究意义,因此,研究发布数据中的属性对于数据发布是否具有研究价值,以及在数据隐私保护和保证数据可用性之间寻找一种平衡具有非常重要的意义。本文提出将特征选择技术和微聚集技术相结合的隐私保护方法,从待发布的数据属性中选择最有利于对数据发布有研究价值的数据属性,该方法降低了数据隐私泄露的风险,但是在一定程度上增加了信息的损失。
2 特征选择及reliefF算法
特征选择是一种非常常见的降维方法,它是指从原始特征集中选择使某种评估标准最优的特征子集,其目的是挑选一些最有效的特征从而降低数据特征维度,使选出的最优特征子集和特征选择前近似甚至更好的预测结果,这不但提高了模型的泛化能力、计算效率,也提高了数据的实际效用,同时可降低维度灾难的发生频率。
Relief[2]算法在特征选择算法中比较优秀且常用的算法。Relief算法随机从训练集中选取m个样本实例,然后找出和选取的样本属于同类和不同类的两个距离最近的样本,计算它们之间的差异,计算样本的每个特征和类的相关性,再用平均值分别作为各个特征的权值。
在relief算法的基础上,I. Kononerko[3]等人在其基础上得到了其扩展算法ReliefF,ReliefF算法是从同类和不同类中选择k个距离最近的样本,然后计算平均值作为各个特征的权值[3]。将得到的特征进行排序,然后根据一定的规则来判定特征是有效还是无效的;或者选择n个权值最大的特征,去除其他特征来进行特征选择。
特征选择的目的是选择和分类有较大相关的特征,特征选择没有改变特征的语义特征和数值,只是选择特征子集。将特征选择应用在数据发布中时,特征选择是选择和敏感属性有较大相关的准标识符属性,权值越高的说明该准标识符属性和敏感属性的相关性越高,那么该准标识符属性对于数据发布的研究价值和意义就越大,反之则越小。原始数据集在经过了特征选择之后,数据属性个数减少,即数据的维度降低了,这样再对数据集进行匿名化时,匿名化的效率得到了提高,防止了数据“维度灾难”的发生,同时隐私泄露的风险也相应地降低了,但是在一定程度上增加了数据的信息损失。
3 reliefF 算法在数据发布隐私保护中的应用
特征选择算法选择的是对于分类最有利的特征。而在本文中,我们要选择的特征属性则是和敏感属性具有相关性的准标识符属性。本文提出的基于reliefF的匿名化方法主要思想是:首先使用reliefF算法得到每个数据属性的权值,即数据中每个属性和敏感属性的相关性;然后按照一定的规则剔除一些数据属性,对剔除了数据属性的数据集进行微聚集得到匿名数据表。具体步骤如下:
步骤1:数据预处理1
1)将原始数据集中的不完整数据剔除;
2)去除元组中的冗余属性;
步骤2:数据预处理2
对预处理1中得到的数据集进行标准化,得到数据集T;
步骤3:使用reliefF算法对数据集T进行降维处理得到数据集T
该步计算元组每个属性的权值,先将权值小于0的属性去除,同时将大于0的属性权值进行排序;
步骤4:使用MDAV算法对数据集T'进行微聚集得到数据集T''
对整个数据集进行微聚集,得到k值不同时的信息损失和隐私泄露风险;
剔除权值最小的属性得到新的数据集,对新的数据集进行微聚集,得
得到k值不同时的信息损失和隐私泄露风险;
多次执行,得到多个信息损失和隐私泄露风险,比较他们之间的差异,再结合数据属性的实际含义得到最后需要发布的数据集T"
基于reliefF的数据发布隐私保护是将reliefF和MDAV相结合来得到匿名化数据,该匿名化数据权衡了数据可用性和隐私泄露风险之间的关系,是相对于最原始数据集发布较为有利的匿名化数据集。
3.1 数据可用性分析
同质性测度(SSE)的计算方法为:等价类中的元组的和原始数据集的数值是相同的,而该等价类的类质心应为经过特征选择后的匿名化数据的类质心加上被剔除的属性的质心0,同质性测度则是原始数据集的数据元组和所在的等价类的类质心之间的距离之和,此时的匿名表所有类相对于原始数据集的同质性测度定义为R-SSE,信息损失量为R-IL=R-SSE/SST。
3.2 隐私泄露分析
匿名化处理后的数据匿名表并不能保证隐私信息得到百分百不被泄露,它仍然有被攻击者攻击的可能,匿名表的安全性指标是信息泄露风险的主要考虑原则。数据安全性度量方法主要有[4]:(1)记录链接方法;(2)区间泄密方法。记录链接度量方法包括基于距离记录链接方法和基于概率记录链接方法两张方法。本文使用的是基于距离记录链接方法。
基于距离记录链接方法就是通过统计匹配成功数所占的比例来衡量数据集的安全性,匹配成功的元组个数用LR表示,数据集总的元组个数用TR表示,则整个数据集的安全性可以用公式表示:
R-TRL = LR /TR
4 实验结果及分析
本实验的运行环境:2.5GHz Intel(R) Core(TM)处理器,8G内存,Windows 8系统。实验数据采用美国的Adult数据库,目前,大部分对PPDP的匿名化模型的研究都采用Adult数据库为测试数据。
实验首先经过reliefF特征选择选择和敏感属性具有相关性的属性,然后分别测试了不同的数据属性个数在不同的数据集大小和不同k值的情况下的信息损失量和隐私泄露风险。
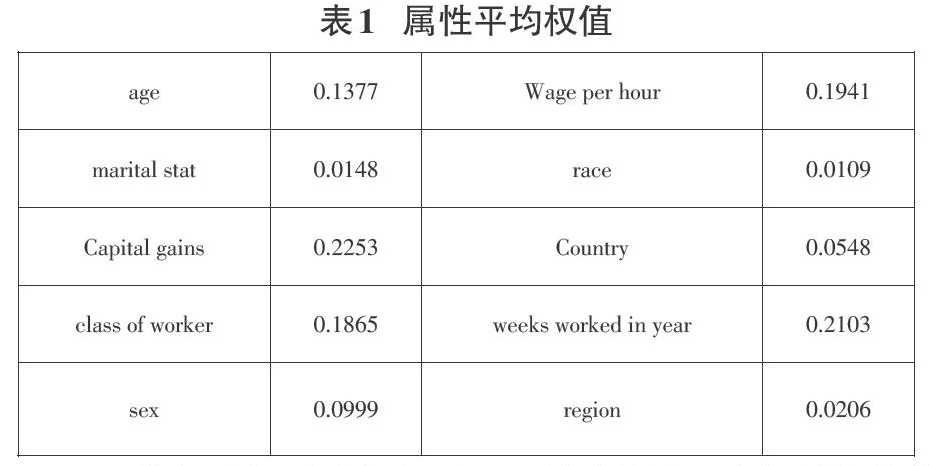
表1是经过特征选择后权值大于0的特征的平均权值。
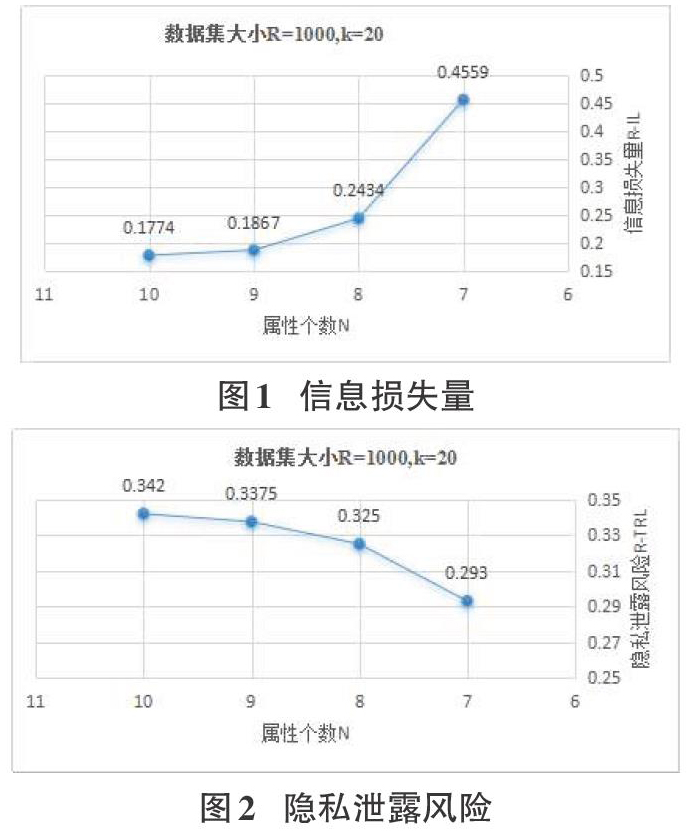
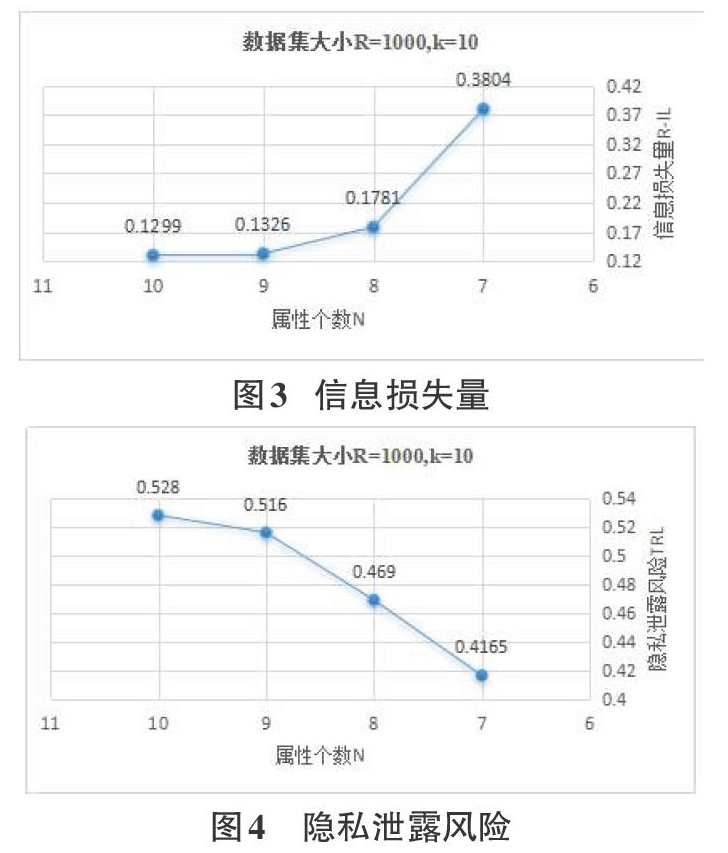
通过特征选择后我们得到了和敏感属性具有相关性的数据属性,我们将这些属性作为数据发布中的准标识符属性,然后对数据集进行微聚集,得到不同的数据属性个数在不同的数据集大小和不同k值的情况下的信息损失量和隐私泄露风险。实验分别测试了数据集大小为2000,k为20,10,5,数据属性个数为10,9,8,7时的多组信息损失量和隐私泄露风险。
图3、图4可以看出,当数据属性的维度N=8时,数据的信息损失量R-IL和隐私泄露风险R-TRL之间的平衡相较于其他维度是较好。
图5、图6可以看出,当数据属性的维度N=8或9时,数据的信息损失量R-IL和隐私泄露风险R-TRL之间的平衡相较于其他维度是较好。
综合以上几种情况分析能够看出,当属性个数N=8时,数据的信息损失量R-IL和隐私泄露风险R-TRL之间的平衡相较于其他维度是较好。
5 结束语
通过实验验证我们可以得出结论:通过reliefF来选择数据发布的属性能够选择对数据发布有意义的数据属性,相对于原始数据集增加了数据的信息损失,但是在发布的匿名化数据集中,数据的准确性相较于原始数据集的更好,数据失真更小,同时也提高数据的安全性。
参考文献:
[1] 王平水. 基于聚类的匿名化隐私保护技术研究[D].南京航空航天大学,2013.
[2] Kira K ,Rendell L A.The feature selection problem: Traditional methods and a new Algorithm[J].Proceedings of Ninth National Conference on Artificial Intelligence, 1992,05: 129-134.
[3] Kononerko I.Estimating attributes: analysis and extension of Relief[C]. In Proceedings of European conference on machine learning, Springer-Verlag New York, 1994:171-182.
[4]Panaretos J, Nikolaos T. Aspects of estimation Procedures at eurostat with some emphasis on over-space harmonization[A].Proc of the 5th Hellenic-European Conference on Computer Mathematics and its Applications[C].Athens,Greece:LEA Press,2001:853-857.
- 大数据审计在商业银行审计中的应用研究
- 浅析经济结构的调整对经济金融化发展的影响
- 互联网时代下民宿产业发展模式研究
- FDI对我国企业OFDI的影响
- 乡村振兴战略背景下中山特色农产品电商发展路径
- 我国跨境电子商务物流现状及运作模式分析
- 疫情环境下智慧物流的作用与发展趋势
- 企业生产物流系统现状分析及整合策略
- 中俄边贸物流发展问题研究
- 中欧班列对城市物流网络的影响
- 大学生网贷消费和金融素养调查
- 孤独经济下的消费行为及行业发展研究
- 新上市主要农产品期货价格泡沫及特征研究
- 浅谈新冠肺炎疫情对居民消费行为的影响
- 以工匠精神助力消费从“物质”向“精神”转型
- 国产乳制品销售额的特点和影响因素
- 中国品牌奶茶顾客忠诚度及其影响因素
- 新时代企业人力资源绩效管理体系的构建探究
- 关于新形势下企业人力资源管理中的问题及对策
- 高新技术企业新生代知识型员工激励机制研究
- 对企业管理中人员与岗位相匹配问题的探讨
- 中小企业构建和谐劳动关系的重要性和途径
- 新形势下企业人力资源管理中的问题及对策
- 基于“受众群体”的农产品网络直播策略研究
- 粉丝应援电商平台运营模式的探究
- endowment mortgage
- endowments
- endows
- endow sb/sth with sth
- endow with
- endproduct
- end product
- end-product
- end products
- end result
- end's
- ends
- ends up
- end-to-end
- endtoend
- end-up
- end up
- end up (as sth); end up (doing sth)
- endurable
- endurance
- endurances
- endure
- endured
- endurement
- endurer
- 顾祝同
- 顾离退
- 顾私
- 顾笑
- 顾管
- 顾累
- 顾绣
- 顾维钧
- 顾而言他
- 顾脑袋不顾腚
- 顾菟
- 顾藉
- 顾虎头
- 顾虑
- 顾虑且害怕
- 顾虑多
- 顾虑太多
- 顾虑太多,不能成事
- 顾虑打消,完全放心
- 顾虑畏惧
- 顾虑过多,犹豫不决
- 顾虑避忌
- 顾虑重重
- 顾虑,畏忌
- 顾蜉蝣而自嗟