李伯涵 李红莲


摘要:基于注意力机制的编码-解码模型的神经网络具有很好的生成文本摘要能力。但是,这些模型在生成过程中很难控制,这导致在生成文本中缺少关键信息。一些关键信息,例如时间,地点和人物,对于人类理解主要内容是必不可少的。本文提出了一个基于多任务学习框架的用于生成文本摘要的关键信息指南网络。主要思想是以端到端的方式自动提取人们最需要的关键信息,并用其指导生成过程,从而获得更符合人类需求的摘要。在本文提出的模型中,文档被编码为两个部分:普通文档编码器的编码结果和关键信息的编码,关键信息包括关键句和关键词。引入了多任务学习框架以获得更先进的端到端模型。为了融合关键信息,提出了一种多视角注意指南网络,以获取源文本和关键信息的向量。另外,向量被合并到生成模块中以指导摘要生成的过程。本文在CNN 与Daily Mail数据集上评估了模型,实验结果表明此模型有重大改进。
关键词:关键信息;多任务学习;文本摘要;关键信息指南网络
中图分类号:TP391.1 ? ? ?文献标识码:A
文章编号:1009-3044(2020)31-0020-06
Abstract: The neural network of the encoding-decoding model based on the attention mechanism has a good ability to generate text summaries. However, these models are difficult to control during the generation process, which leads to the lack of key information in the generated text. Some key information, such as time, place, and people, is essential for humans to understand the main content. This paper proposes a key information guide network for generating text summaries based on a multi-task learning framework. The main idea is to automatically extract the key information that people need most in an end-to-end manner, and use it to guide the generation process, so as to obtain a summary that is more in line with human needs. In the model proposed in this paper, the document is coded into two parts: the coding result of the ordinary document encoder and the coding of key information. The key information includes key sentences and keywords. A multi-task learning framework is introduced to obtain a more advanced end-to-end model. In order to fuse key information, a multi-perspective attention guide network is proposed to obtain the vector of source text and key information. In addition, vectors are incorporated into the generation module to guide the process of abstract generation. This paper evaluates the model on the CNN and Daily Mail datasets, and the experimental results show that this model has significant improvements.
Key words: key information;multi-task learning;text summary;key information guide network
1引言
文本摘要是一項自动从给定文本生成简短摘要的任务。文本摘要有两种主要方法:抽取式和生成式。抽取式模型[1-2]通常通过从原始文本中提取一些句子来获得摘要,而生成式模型[3-4]通过生成新的句子来生成摘要。最近,编码-解码神经网络框架[5]推进了对生成式文本摘要的进一步研究。
原始文本和摘要都是人类语言。为了得到更高质量的结果,模型必须能够“理解”并以类似于人的方式表示原始文本。时间,地点和人物等实体是人类理解主要内容的关键。因此,必须利用这些关键信息生成摘要。尽管当前的生成式模型被证明能够捕获文本摘要的规律性,但是在生成过程中却很难对其进行控制。换句话说,没有外部指导,很难确保生成式模型可以识别关键信息并将其生成到摘要中[6]。
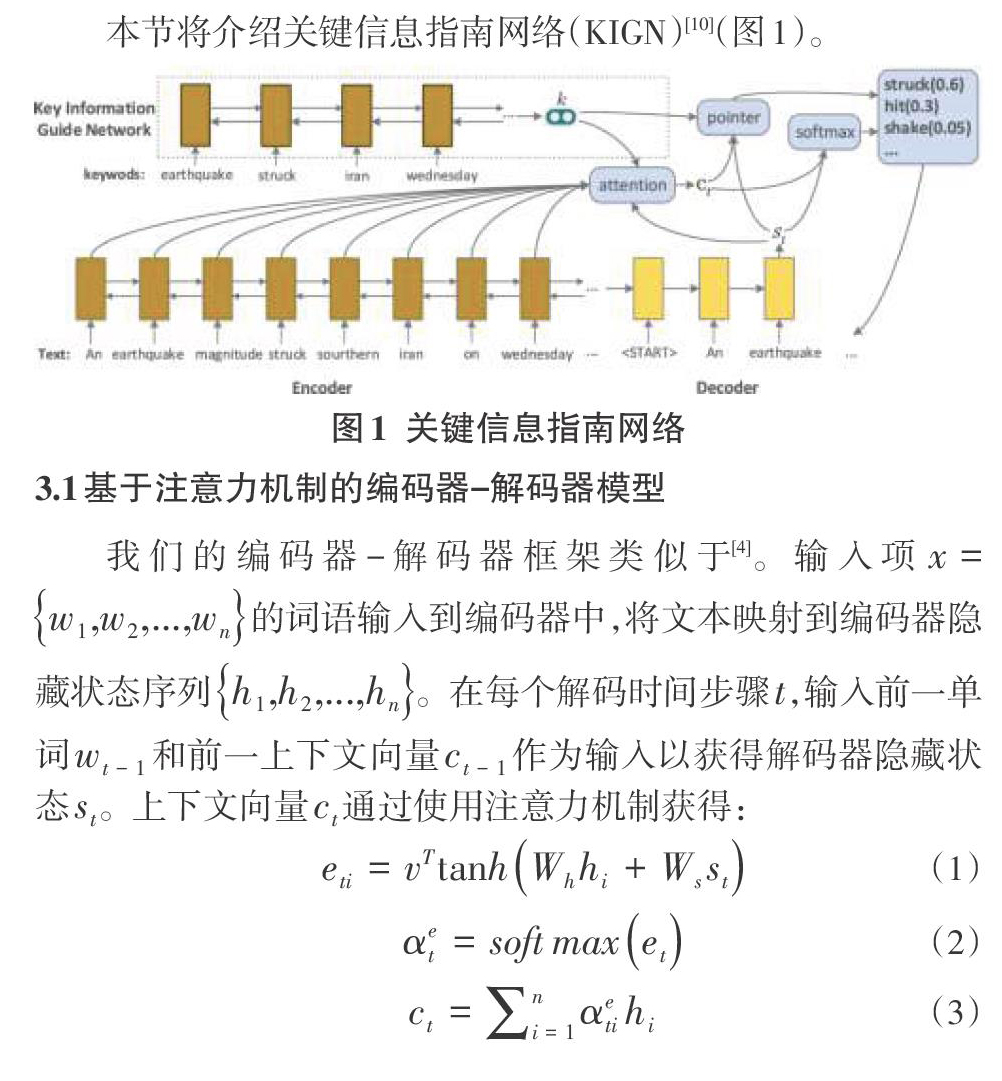
一些研究试图解决这些问题。Zhou等人[7]提出了一个选择性门网络来保留摘要中的更多关键信息。但是,由输入文本控制的选择性门网络仅控制一次从编码器到解码器的信息流。如果某些关键信息没有通过网络,那么它们将很难出现在摘要中。See等人[8]提出了一种指针生成器模型,该模型使用指针机制[9]从输入文本中复制单词,以处理未登录词(OOV)。没有外部指导,指针很难识别关键字。在先前的工作中,本文将抽取式模型和生成式模型结合在一起,并使用前一个模型来获取关键词作为后一个模型的指导[10]。然而,这种模型还不够完善。并且这是一个通过TextRank算法提取关键字的流水线系统。
3.3指针机制
为了处理OOV(未登录词)问题,将指针网络[9]与基于关键信息的生成方法相结合,这样便能够复制单词并生成文本。在指针生成器模型中,需要计算一个开关[psw]以在生成的单词和原文本的单词之间进行选择:
4使用KIGN进行生成式文本摘要的多任务学习
第3节中介绍的KIGN使文本摘要生成器可以更加关注关键信息。但是,该模型还不够完善。例如,关键信息是通过Textrank算法而不是基于学习的方法获得的。本节介绍了一种基于KIGN框架的用于生成式文本摘要的多任务学习模型(图2),该模型包括文档编码器,关键信息提取器以及联合训练和预测指南机制等方法。
如图2所示,首先,提出一种文档编码器,它包括单词级编码器和句子级编码器。这样,可以分别获取每个单词和每个句子编码的全局特征。然后,关键信息提取层选择关键词和关键句子。接下来,生成器将指导生成过程。最后,通过以端到端的方式最小化三个损失函数来训练和关键信息提取器。
4.1文档编码器
本文提出了一种新颖的文档编码器,分别对单词和句子进行编码,而不是仅使用分层编码器对两者进行编码[4]。该方法将有助于后续的关键词提取和关键句子提取。
4.1.1全局词编码器
关键词提取的任务需要整个文档的信息以及单个单词的信息。使用双向LSTM作为全局词编码器。输入文本[w1,w2,...,wn]的词语被前馈到全局单词编码器中,全局单词编码器将文本映射到一系列隐藏状态[hw1→,hw2→,...,hwn→]:
关键词标签生成。要获取关键词,需要去除参考摘要中的停用词,然后将其余部分[rw=rwii]用作关键字正确数据标签。对于关键句子正确数据标签[rs=rsii],测量文本中每个句子的信息量,并选择关键句子[11]。为了获得正确数据标签,首先通过计算句子和参考摘要之间的ROUGE-L得分,来测量文章中每个句子的信息量。其次,根据信息量对句子进行排序,并按信息量从高到低的顺序选择句子。最后,获得了正确数据标签并通过最小化损失函数来训练提取器。方法类似于[11],该方法旨在提取文章的最终摘要,以便使用ROUGE F-1得分来选择句子。在本文提出的模型中,使用ROUGE得分来获得尽可能多的参考摘要信息。
4.5测试预测指南机制
在测试的过程中,模型在预测下一个单词时,不仅要考虑上述概率(公式(9)),还要考虑预测指南机制[13]预测的长期值。
本文的预测指南机制是具有sigmoid激活函数的单层前馈网络,可预测最终摘要中关键信息的范围。在每个解码时间[t]处,对解码器隐藏状态进行平均求和[st=1tl=1tsl],编码器隐藏状态[hn=1ni=1nhi],并且关键信息[k]作为输入获得长期值。
为每个[x]摘要采样yp1和yp2两个部分,并随机停止得到[st]。然后,从yp完成构建,以获取M个平均解码器隐藏状态[s]并计算平均得分:
5实验
5.1实验设置
这里使用CNN /Daily Mail数据集[4,25],并且以与[8]相同的方式处理数据。对于全局单词编码器和句子编码器,使用三个300维LSTM,并使用一个5万词的词汇表。在训练和测试过程中,将单词编码器的输入设为400个词汇,并将摘要的长度设为100个词汇。使用Adagrad算法[15]以学习速率0.15和初始累加值0.1来训练模型。一次训练样本数设置为16,关键词和关键句子的数量分别为40和10。共同训练这三个任务,并设置[λ1=1]和[λ2=λ3=0.5]。本文采用的主要评估指标是ROUGE的F得分。
此外,对于预测机制,使用单层前馈网络,并将节点数设置为800。对于超参数[α],在解码期间使用不同的[α]来测试KIGN预测指南模型在运行期间的性能。从图3可以看出,[α]为0.8到0.95时此模型的性能是稳定的。另外,将[α]设置为0.9时,可以获得最高的F分数。这里将M设置为8并采用mini-batch算法与AdaDelta算法来训练模型。
在训练和测试的过程中,将输入词语设置为400个,并将输出摘要的长度设置为100个词语。在测试阶段类似于[8],将输入词语设置为400个,并将输出摘要的長度设置为100个词语。以少于200,000的迭代次数训练关键词网络模型。然后,基于KIGN模型训练一个单层前馈网络。最后,在测试过程中,将KIGN模型与预测指南机制相结合以生成摘要。
5.2结果与讨论
实验结果如表1所示。前五种是常用的序列到序列方法:具有注意力机制的Seq2Seq模型(词汇表含150k词汇),具有注意力机制的Seq2Seq模型(词汇表含50k词汇),具有图注意力机制的Seq2Seq模型,分层注意力机制网络[4]和具有指针机制的Seq2Seq模型。
表1表明本文模型的基线模型(称为关键信息指南网络)(如图1所示)比具有指针机制的Seq2Seq模型获得更好的分数,分别为+1.3 ROUGE-1,+0.9 ROUGE-2和+1.0 ROUGE-L。借助指针机制(如图1所示),关键信息指南网络(KIGN + Prediction-guide)再次取得了更好的分数,分别为+2.5 ROUGE-1,+1.5 ROUGE-2和+2.2ROUGE-L。而具有多任务学习框架的关键信息指南网络(如图2所示)获得了最佳分数。并且,如果给出了关键词和关键句子,则结果会更好,这也证明使用关键信息指导文本摘要生成是合理的。
5.3案例研究
为了证明本文的方法获得关键信息的能力,图4显示了特定文本的处理结果。原始文本列在图4的上半部分,并对关键信息加粗处理。接下来是给出的原本摘要和两个模型的输出。原始文字是关于在Android手机上的Google手写输入和一些功能介绍,关键信息是“goole claims”,“read anyones handwriting”,“android handsets can under 82 languages in 20 distinct scripts”和“works with both printed and cursive writing input with or without a stylus”可以观察到,具有指针机制的基线模型的输出仅涉及“google have cracked the problem of reading handwriting”,然而本文的模型总结了几乎所有关键信息。
6結论
本文提出了一种具有关键信息指南网络的多任务学习模型,该模型以新颖的方式将抽取式方法和生成式方法相结合。此模型基于关键信息指南网络。关键信息指南网络使用抽取式方法从文本中获取关键字,然后将关键词编码为关键信息向量,并将其输入到生成模型中以指导生成过程。指导主要从两个方面进行:注意力机制和指针机制。在关键信息指导网络的基础上,本文提出了一种多任务学习模型来联合训练抽取式模型和生成式模型,具体而言,使用文档编码器分别对输入文本的词汇和句子进行编码。然后,基于编码器,提取包括关键字和关键句在内的关键信息。通过这种方式,关键信息的提取并不是通过TextRank方法,而是从序列到序列模型中获取。最后,共同训练关键词提取,关键句子提取和生成摘要这三项任务。在测试阶段,使用一种预测指南机制,来进一步指导摘要生成,该机制可以获取长期值用于后续的解码。实验表明,本文提出的模型可以显著提升摘要的质量。
参考文献:
[1] R. Mihalcea, P. Tarau, in Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. Text rank: bringing order into text (Association for Computational Linguistics, Barcelona, Spain, 2004), pp. 404–411. https://www.aclweb.org/anthology/W04-3252.
[2] YasunagaM,ZhangR,MeeluK,etal.Graph-based neural multi-document summarization[EB/OL].2017:arXiv:1706.06681[cs.CL].https://arxiv.org/abs/1706.06681.
[3] A. M. Rush, S. Chopra, J. Weston, in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. A neural attention model for abstractive sentence summarization (Association for Computational Linguistics, Lisbon, Portugal, 2015), pp. 379–389. https://www.aclweb.org/anthology/D15-1044. https://doi.org/10.18653/v1/D15-1044
[4] R. Nallapati, B. Xiang, B. Zhou, Sequence-to-sequence rnns for text summarization. CoRR.abs/1602.06023 (2016). 1602.06023
[5] I. Sutskever, O. Vinyals, Q. V. Le, in Advances in Neural Information Processing Systems 27. Sequence to sequence learning with neural networks (Curran Associates, Inc., 2014), pp. 3104–3112. http://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf
[6] J. Tan, X. Wan, J. Xiao, in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).Abstractive document summarization with a graph-based attentional neural model (Association for Computational Linguistics, Vancouver, Canada, 2017), pp. 1171–1181. https://www.aclweb.org/anthology/P17-1108. https://doi.org/10.18653/v1/P17-1108
[7] Q. Zhou, N. Yang, F. Wei, M. Zhou, in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Selective encoding for abstractive sentence summarization (Association for Computational Linguistics, Vancouver, Canada, 2017), pp. 1095–1104. https://www.aclweb.org/anthology/P17-1101. https://doi.org/10.18653/v1/P17-1101
[8]A. See, P. J. Liu, CD. Manning, in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Get to the point: summarization with pointer-generator networks (Association for Computational Linguistics, Vancouver, Canada, 2017), pp. 1073–1083. https://www.aclweb.org/anthology/P17-1099. https://doi.org/10.18653/v1/P17-1099
[9] O. Vinyals, M. Fortunato, N. Jaitly, in Advances in Neural Information Processing Systems 28, ed. by C. Cortes, N. D. Lawrence, D. D. Lee, M.Sugiyama, and R. Garnett. Pointer networks (Curran Associates, Inc., 2015), pp. 2692–2700. http://papers.nips.cc/paper/5866-pointer-networks.pdf
[10] C. Li, W. Xu, S. Li, S. Gao, in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Guiding generation for abstractive text summarization based on key information guide network (Association for Computational Linguistics, New Orleans, Louisiana, 2018), pp. 55–60. https://www.aclweb.org/anthology/N18-2009. https://doi.org/10.18653/v1/N18-2009
[11] W.-T. Hsu, C.-K.Lin, M.-Y. Lee, K. Min, J. Tang, M. Sun, in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). A unified model for extractive and abstractive summarization using inconsistency loss (Association for Computational Linguistics, Melbourne, Australia, 2018), pp. 132–141. https://www. aclweb.org/anthology/P18-1013. https://doi.org/10.18653/v1/P18-1013
[12] S. Chopra, M. Auli, A. M. Rush, in Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Abstractive sentence summarization with attentive recurrent neural networks (Association for Computational Linguistics, San Diego, California, 2016), pp. 93–98. https://www.aclweb.org/anthology/N16-1012. https://doi.org/10.18653/v1/N16-1012
[13] D. He, H. Lu, Y. Xia, T. Qin, L. Wang, T.-Y. Liu, in Advances in Neural Information Processing Systems 30, ed. by I. Guyon, U. V. Luxburg, S. Bengio,H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett. Decoding with value networks for neural machine translation (Curran Associates, Inc.,2017), pp. 178–187. http://papers.nips.cc/paper/6622-decoding-with value-networks-for-neural-machine-translation.pdf
[14] B. Dzmitry, C. Kyunghyun, B. Yoshua, Neural machine translation by jointly learning to align and translate. Comput.Sci. (2014). 1409.0473v6
[15] J. Duchi, E. Hazan, Y. Singer, Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 12(Jul),2121–2159 (2011)
[16] C. Y. Lin, E. Hovy, in Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics. Automatic evaluation of summaries using n-gram co-occurrence statistics, (2003), pp. 150–157. https://www. aclweb.org/anthology/N03-1020
[17] M. D. Zeiler, ADADELTA: an adaptive learning rate method. CoRR.abs/1212.5701 (2012). 1212.5701
[18] M. Zhanyu, L. Yuping, K. W. Bastiaan, W. Liang, G. Jun, Variational Bayesian learning for Dirichlet process mixture of inverted Dirichlet distributions in non-Gaussian image feature modeling. IEEE Trans. Neural Netw. Learn. Syst. 30(2), 449–463 (2019). https://doi.org/10.1109/TNNLS.2018.2844399
[19] M. Zhanyu, Y. Hong, C. Wei, G. Juo, Short utterance based speech language identification in intelligent vehicles with time-scale modifications and deep bottleneck features. IEEE Trans. Veh. Technol.68(1), 121–128 (2019). https://doi.org/10.1109/TVT.2018.2879361
[20] K. Zhang, N. Liu, X. Yuan, X. Guo, C. Gao, Z. Zhao, Fine-grained age estimation in the wild with attention LSTM networks. IEEE Trans. Circ. Syst.Video Technol. (TCSVT) (2019). Accepted. https://doi.org/10.1109/tcsvt.2019.2936410
[21] L. Xiaoxu, Y. Liyun, C. Dongliang, M. Zhanyu, C. Jie, Dual cross-entropy loss for small-sample fine-grained vehicle classification. IEEE Trans. Veh.Technol. (TVT). 68(5), 4204–4212 (2019)
[22] M. Zhanyu, X. Jing-Hao, L. Arne, T. Zheng-Hua, Y. Zhen, G. Jun,Decorrelation of neutral vector variables: theory and applications. IEEE Trans. Neural Netw. Learn. Syst. 29(1), 129–143 (2018). https://doi.org/10.1109/TNNLS.2016.2616445
[23] M. Zhanyu, C. Dongliang, X. Jiyang, D. Yifeng, W. Shaoguo, L. Xiaoxu, S.Zhongwei, G. Jun, Fine-grained vehicle classification with channel max pooling modified CNNs. IEEE Trans. Veh. Technol. 68(4), 3224–3233 (2019)
[24] M. Zhanyu, X. Jiyang, L. Yuping, T. Jalil, X. Jing-Hao, G. Jun, Insights into multiple/single lower bound approximation for extended variational inference in non-Gaussian structured data modeling. IEEE Trans. Neural Netw. Learn. Syst., 1–15 (2019). https://doi.org/10.1109/TNNLS.2019.2899613
[25] K. M. Hermann, T. Kocisky, E. Grefenstette, L. Espeholt, W. Kay, M.Suleyman, P. Blunsom, in Advances in Neural Information Processing Systems 28, ed. by C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R.Garnett. Teaching machines to read and comprehend (Curran Associates, Inc., 2015), pp. 1693–1701. http://papers.nips.cc/paper/5945-teaching machines-to-read-and-comprehend.pdf
【通聯编辑:梁书】
- 中南六省将全面禁止外地生猪调入
- 浙江省生猪养殖省内跨区域调剂补偿政策出台
- 湖北:黄石首家生猪运输车辆洗消中心投入使用
- 江西省奉新县多举措做好生猪复养增产工作
- 《兽医临床诊断学》的实践教学现状及对策
- 虚拟现实技术在《畜禽解剖生理》课程教学中的应用
- “新农科”背景下卓越动物科学专业“晋级式”实践教学模式的研究与实践
- 山羊布鲁氏菌病的防控思考
- 畜牧养殖环境污染及对策研究
- 利川市病死畜禽无害化收集处理体系运行中存在的问题与建议
- 农村养殖业存在的问题及建议
- 猪育种存在的问题及育种方式的选择
- 一例肉鸡混合型鸡痘的诊治
- 鸡传染性喉气管炎的防控
- 鸡常见病的症状与防治措施
- 牛冬季腹泻的诊治
- 羊蠕虫病的种类、检疫方法和防治措施
- 猪霉菌毒素中毒的诊断与治疗方法
- 仔猪原发性缺铁性贫血病的诊治及预防
- 一起水淹种猪场无害化处理方案
- 山羊口疮病的发病特点、鉴别诊断及防治措施
- 生态猪支原体肺炎的防治
- 鄂州市2020年春季重大动物疫病免疫效果评估与分析
- 一起猪链球菌和传染性胸膜肺炎放线杆菌混合感染的诊断报告
- 基于宠物经济与产业升级中职兽医技能人才需求的探究
- mouth off
- mouth organ
- sufferableness
- sufferablenesses
- sufferably
- suffered
- sufferer
- sufferers
- suffer from
- sufferfrom
- suffer from sth
- suffer heavy losses
- suffering
- sufferingly
- sufferings
- suffers
- suffice
- sufficed
- sufficer
- sufficers
- suffices
- sufficiencies
- sufficiency
- sufficient
- sufficiently
- 评论考察官吏的才德
- 评论衡量
- 评论解释
- 评论记载
- 评论诗歌、诗人、诗派,记录诗人议论、事迹的著作
- 评论语
- 评论赞美
- 评论辩驳的奏章
- 评论高下
- 评评理
- 评识
- 评词
- 评话
- 评话或评弹演员演唱故事所用的底本
- 评语
- 评说
- 评说事理的是非
- 评说是非
- 评说罪过
- 评课
- 评质
- 评赃
- 评资
- 评赏
- 评赞