端到端语音识别研究综述
郭宗昱 刘博 吴可欣 李姝怡 蒋昊轩 李云洁
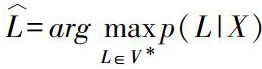
摘?要:语音识别(ASR)是机器学习领域的热点研究问题。长期以来,隐马尔可夫模型-高斯混合模型(HMM-GMM)是传统语音识别主要框架,随着深度学习的快速发展,DNN模块取代GMM,语音识别性能有了一定程度的提升。然而,HMM-DNN模型本身受到各种不利因素的限制,而端到端模型(End-To-End ASR)具有流程简化等优点。因此,端到端模型是语音识别未来的重要研究方向。本文首先介绍传统语音识别的基础理论;然后介绍了HMM-GMM模型和HMM-DNN模型构架;其次,重点介绍了两种不同类型的端到端模型的基本原理;通过以上对比研究,最后总结了语音识别存在的问题和未来发展方向。
关键词:语音识别;端到端;深度学习;CTC;注意力机制
1 绪论
因此,ASR的基本工作是建立一个可以准確计算后验分布p(L|X)的模型。
与基于HMM的模型相比,端到端模型使用单个模型将音频直接映射到字符或单词,更易于构建和训练等优点使其迅速成为大型词汇连续语音识别研究的热点。
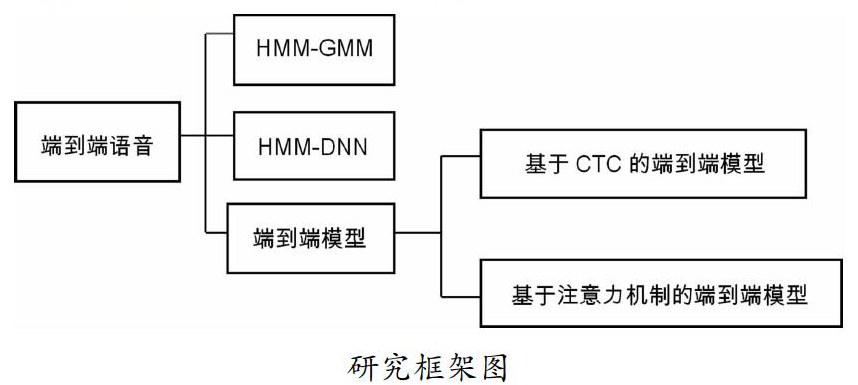
本文的整体框架如下图所示:分别介绍传统语音识别模型(HMM-GMM)、基于传统模型改进的语音识别模型(HMM-DNN)、基于神经网络的端对端语音识别模型;端到端模型又分别介绍了基于CTC和注意力机制的模型。
2 基于HMM-GMM的语音识别模型
基于HMM的模型可以分为彼此独立并发挥不同作用的三个部分:声学模型、发音模型和语言模型。声学模型P(X|S),从隐藏序列S观察X的概率,用于对语音输入和功能序列之间的映射进行建模。发音模型P(S|L),也称为字典,是为了实现音素(或子音素)到音素之间的映射,建立声音序列和语言序列之间的联系。语言模型P(L)由大量语料训练,使用m-1阶马尔可夫假设生成m-gram语言模型,将字符序列映射到流畅的最终转录[1]。HMM-GMM模型是语音识别的通用结构,但随着深度学习技术的发展,DNN(深度神经网络)被引入语音识别的声学建模[2]。与传统的基于HMM-GMM的声学模型相比,它的不同点在于用DNN替换了GMM来对输入语音信号的观察概率进行建模。其作用是计算HMM状态的后验概率,从而取代传统的GMM输出概率[3]。在基于HMM的模型中,不同的模块使用不同的技术并发挥不同的作用。HMM主要用于帧级别的动态时间规整,GMM和DNN用于计算HMM隐藏状态的发射概率[4]。
3 端到端模型
端到端模型是直接将输入音频序列映射到单词或其他字素序列的系统。大多端到端语音识别模型包括:编码器,将语音输入序列映射到特征序列;对齐器,实现特征序列和语言之间的对齐;解码器,对最终的识别结果进行解码。该模型与由多个模块组成的基于HMM的模型不同,它用一个深层网络替换了多个模块,实现从声信号直接映射到标签序列,大大简化了语音识别模型的构建和训练。
3.1 基于CTC的端到端模型
CTC在计算损失时解决了硬对齐问题。对于端到端LVCSR模型,CTC主要克服了数据对齐问题和直接输出目标转录两个困难,它使用单个网络结构将输入序列直接映射到标签序列,实现端到端语音识别。
CTC过程可以看作两个子过程:路径概率计算和路径聚合。其中最重要的是引入新的空白标签和中间概念路径。由于CTC的计算过程相当确定,因此大多数基于CTC的ASR都主要研究如何有效地构建神经网络声学模型。
(1)模型结构。CTC的一大优势是消除了数据分段对齐的必要性。Li等人提出了由CTC为LVCSR任务训练的端到端模型[5]。他们设计了一个三层网络,第一层是78维前馈层,第二层是含有120个记忆体的LSTM层,第三层是含有27个记忆体的LSTM层。结果表明,增加网络的深度和隐藏单元的数量可以有效地提高识别效果[6]。关于结构,Song等人引入CNN并将其与RNN结合用于ASR[7],设计的结构包括了四个CNN层。另外,还有人设计了一个仅使用CNN和CTC的模型[8]。该模型使用十层CNN和三层完全连接,并在时间和频率维度上执行卷积操作。结果表明,更深的模型可以获得更好地识别效果。关于网络深度,Amodei等人使用CTC训练具有九层(其中七层是RNN)的网络,该模型可以在某些任务上胜过人类[9]。Zweig等人使用CTC训练了一个由九层双向RNN组成神经网络,其隐藏单元维数为1024,在各自的数据集上获得最佳结果[10]。综上所述,网络模型的结构和深度趋势并不意味着更深、更复杂的网络在任何情况下都可以取得更好的结果。
(2)大规模数据训练。复杂的深度模型需要大量的数据进行训练以进行语音识别。为了有效地训练一个五层网络模型,Hannun等人使用超过7000h的干净语音数据,加上合成噪声语音,总共超过100,000小时的语音数据[2]。借助大规模数据集,他们在自己构建的嘈杂数据集上取得了最佳结果,胜过了Apple,Google等多家商业公司。Amodei等人使用11,940h的英语语音和9400h的中文语音数据来训练九层网络模型,最终在常规中文识别中达到了高于人类的水平[9]。
(3)语言模型。语言模型对于提高基于CTC的端到端ASR的性能非常有帮助。Graves等人的研究[11]表明,在WSJ数据集上,仅RNN+CTC模型单词错误率(WER)为30.1%。若引入单词词典,WER为24%。若引入三元语法语言模型(LM),WER降至8.7%。语言模型对于在单词水平上取得良好的表现发挥着至关重要的作用。受到这些启发,Li,Maas,Hwang等人的研究也将语言模型与CTC集成在一起[6][12][13]。结果表明,语言模型可以大大提高识别的准确性,对于具有复杂结构和大量训练数据的模型也有显著效果。
3.2 基于注意力的端到端模型
基于注意力的端到端模型可以分為三个部分:编码器,对齐器和解码器,主要是对齐器部分使用了注意力机制。其中编码器起声学模型的作用,与HMM-DNN混合模型相同,因此面临着相同的问题。在相同的解决方案下,它还会出现新的问题。
(1)基于注意力端到端模型框架。该模型由编码网络、解码网络和注意力子网络三个模块组成,编码网络和解码网络均包含循环神经网络单元。编码网络为深层循环神经网络,目的是学习和挖掘语音特征序列的上下文关联信息,从原始特征中提取高层信息,增强特征的区分度和表征能力。注意子网络的主体是含有单隐含层的多层感知器,网络输入是编码网络的输出和解码网络的隐含层单元状态,输出是它们的关联度分数。解码网络由单层循环神经网络和maxout网络连接而成。它先根据注意力子网络得到注意力系数对所有编码网络的输出加权求和得到目标向量,再将目标向量作为网络输入,计算输出序列每个位置上各个音素出现的后验概率[14]。
(2)网络结构。为了提高编码能力,基于注意力的模型中的编码器也变得越来越复杂。早期的编码器基本上位于三层之内[15][16],并逐渐发展为四层[17][18][19]、五层[20][21]、六层[22][23]。使用网络中的网络,批处理规范化,残差网络,卷积LSTM构建了一个15层编码器网络[24],最终在不使用字典或语言模型的情况下,在华尔街日报数据集上实现了10.53%的WER。
(3)基于注意力的工作。从功能上注意力机制可以分为以下三种类型:①基于内容:仅使用输入特征序列F和先前的隐藏状态su-1计算每个位置的权重。但它存在相似性语音片段问题。②基于位置:在每个步骤中,先前的权重αu-1被用作位置信息,以计算当前权重αu。③混合:考虑了输入特征序列F,先前的权重αu-1和先前的隐藏状态su-1,使其能够结合基于上下文和基于位置的注意力的优势。
4 结语
基于超大语料库的前提下,端到端模型已经超过了HMM-GMM模型,但其性能仍然低于或仅与使用深度学习技术的HMM-DNN模型相当。为了真正利用端到端模型,至少需要在模型延迟、语言知识学习等方面进行改进。基于HMM-GMM的模型的构建和训练,同时,经过多年的发展,HMM-GMM模型已达到瓶颈,并且几乎没有进一步改进性能的空间。而深度学习的技术推动了HMM-DNN模型和端到端模型的兴起和发展,这些模型在某些方面的性能已超越HMM-GMM。端到端模型则具有简化模型、联合训练、直接输出和无需要强制数据对齐等优点,且学习曲线较为平缓。因此,端到端模型是LVCSR的当前重点,也是未来的重要研究方向。
参考文献:
[1]Rao,K.;Sak,H.;Prabhavalkar,R.Exploring architectures,data and units for streaming end-to-end speech recognition with RNN-transducer.In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop(ASRU),Okinawa,Japan,16-20 December2017;pp.193-199.
[2]Hannun,A.;Case,C.;Casper,J.;Catanzaro,B.;Diamos,G.;Elsen,E.;Prenger,R.;Satheesh,S.;Sengupta,S.;Coates,A.;et al.DeepSpeech:Scaling up end-to-end speech recognition.arXiv 2014,arXiv:1412.5567.
[3]Lu,L.;Zhang,X.;Cho,K.;Renals,S.A study of the recurrent neural network encoder-decoder for large vocabulary speech recognition.In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association,Dresden,Germany,6-10 September 2015;pp.3249-3253.
[4]Miao,Y.;Gowayyed,M.;Metze,F.EESEN:End-to-end speech recognition using deep RNN models and WFST-based decoding.In Proceedings of the 2015 IEEE Workshop on Automatic,Speech,Recognition,and,Understanding(ASRU),Scottsdale,AZ,USA,13-17December2015;pp.167-174.
[5]Eyben,F.;Wllmer,M.;Schuller,B.;Graves,A.From speech to letters-using a novel neural networ architecture for grapheme based asr.In Proceedings of the 2009 IEEE Workshop on Automatic Speech Recognition & Understanding,Merano/Meran,Italy,13-17 December 2009;pp.376-380.
[6]Li,J.;Zhang,H.;Cai,X.;Xu,B.Towards end-to-end speech recognition for Chinese Mandarin using long short-term memory recurrent neural networks.In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association,Dresden,Germany,6-10 September 2015;pp.3615-3619.
[7]Song,W.;Cai,J.End-to-end deep neural network for automatic speech recognition.Standford CS224D Rep.2015.Available online:https://cs224d.stanford.edu/reports/SongWilliam.pdf(accessed on 14 August 2019).
[8]Zhang,Y.;Pezeshki,M.;Brakel,P.;Zhang,S.;Laurent,C.;Bengio,Y.;Courville,A.Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks.arXiv 2017,[CrossRef].
[9]Amodei,D.;Ananthanarayanan,S.;Anubhai,R.;Bai,J.;Battenberg,E.;Case,C.;Casper,J.;Catanzaro,B.;Cheng,Q.;Chen,G.;et al.Deep speech 2:End-to-end speech recognition in english and mandarin.In Proceedings of the International Conference on Machine Learning,New York,NY,USA,19-24 June 2016;pp.173-182.
[10]Soltau,H.;Liao,H.;Sak,H.Neural Speech Recognizer:Acoustic-to-Word LSTM Model for Large Vocabulary Speech Recognition.arXiv 2017,3707-3711,arXiv:1610.09975.
[11]Graves,A.;Jaitly,N.Towards end-to-end speech recognition with recurrent neural networks.In Proceedings of the International Conference on Machine Learning,Beijing,China,21 June-26 June 2014;pp.1764-1772.
[12]Maas,A.;Xie,Z.;Jurafsky,D.;Ng,A.Lexicon-free conversational speech recognition with neural networks.In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,Denver,CO,USA,31 May-5 June 2015;pp.345-354.
[13]Hwang,K.;Sung,W.Character-level incremental speech recognition with recurrent neural networks.In Proceedings of the 2016 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),Shanghai,China,20-25 March 2016;pp.5335-5339.
[14]龍星延.基于注意力机制的端到端语音识别技术研究.2018,4,24:12-14.
[15]Chan,W.;Lane,I.On Online Attention-Based Speech Recognition and Joint Mandarin Character-Pinyin Training.In Proceedings of the Interspeech,San Francisco,CA,USA,8-12 September 2016;pp.3404-3408.
[16]Chan,W.;Zhang,Y.;Le,Q.V.;Jaitly,N.Latent Sequence Decompositions.In Proceedings of the 5th International Conference on Learning Representations,ICLR 2017,Toulon,France,24-26 April 2017.
[17]Bahdanau,D.;Chorowski,J.;Serdyuk,D.;Brakel,P.;Bengio,Y.End-to-end attention-based large vocabulary speech recognition.In Proceedings of the 2016 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),Shanghai,China,20-25 March 2016;pp.4945-4949.
[18]Watanabe,S.;Hori,T.;Kim,S.;Hershey,J.R.;Hayashi,T.Hybrid CTC/attention architecture for end-to-end speech recognition.IEEE J.Sel.Top.Signal Process.2017,11,1240-1253.[CrossRef].
[19]Chorowski,J.;Jaitly,N.Towards better decoding and language model integration in sequence to sequence models.arXiv 2016,arXiv:1612.02695.
[20]Chiu,C.;Sainath,T.N.;Wu,Y.;Prabhavalkar,R.;Nguyen,P.;Chen,Z.;Kannan,A.;Weiss,R.J.;Rao,K.;Gonina,E.;et al.State-of-the-Art Speech Recognition with Sequence-to-Sequence Models.In Proceedings of the 2018 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),Calgary,AB,Canada,15-20 April 2018;pp.4774-4778.
[21]Prabhavalkar,R.;Sainath,T.N.;Wu,Y.;Nguyen,P.;Chen,Z.;Chiu,C.;Kannan,A.Minimum Word Error Rate Training for Attention-Based Sequence-to-Sequence Models.In Proceedings of the 2018 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),Calgary,AB,Canada,15-20 April 2018;pp.4839-4843.
[22]Hayashi,T.;Watanabe,S.;Toda,T.;Takeda,K.Multi-Head Decoder for End-to-End Speech Recognition.arXiv 2018,arXiv:1804.08050.
[23]Weng,C.;Cui,J.;Wang,G.;Wang,J.;Yu,C.;Su,D.;Yu,D.Improving Attention Based Sequence-to-Sequence Models for End-to-End English Conversational Speech Recognition.In Proceedings of the Interspeech ISCA,Hyderabad,Indian,2-6 September 2018;pp.761-765.
[24]Zhang,Y.;Chan,W.;Jaitly,N.Very deep convolutional networks for end-to-end speech recognition.In Proceedings of the 2017 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),New Orleans,LA,USA,5-9 March 2017;pp.4845-4849.
項目基金:空中交通管理创新创业实践基地(项目编号:202010059083)
作者简介:郭宗昱(2000—),女,汉族,湖南人,本科,端到端语音识别;吴可欣(2000—),女,汉族,湖北人,本科,端到端语音识别;李殊仪(2000—),女,汉族,云南人,本科,端到端语音识别;蒋昊轩(2001—),男,汉族,四川人,本科,端到端语音识别;李云洁(1998—),男,汉族,云南人,本科,端到端语音识别。
通讯作者:刘博(1985—),男,汉族,陕西人,硕士,中级,空中交通管理、机器学习。
