魏一丁

[摘 要]利用8天左右的淘宝用户数据,基于Keras框架完成电商推荐系统排名部分构建。该系统采用了多层深度学习框架,使用用户ID、商品ID、类目ID、用户行为类型与行为时间作为隐藏特征来源输入,映射成高密度低维向量,利用ReLU与Softmax等激活函数生成推荐模型,预测误差率0.21。
[关键词]隐藏特征;推荐系统;排名;深度学习;Keras
doi:10.3969/j.issn.1673 - 0194.2020.12.073
[中图分类号]TP391.3[文献标识码]A[文章编号]1673-0194(2020)12-0-04
1 ? ? 基于多维隐藏特征电商推荐系统的相关研究
对于在线电商平台来说,主要目的是最高效率地撮合交易,高性能的推荐系统不可或缺,可以让买卖双方在最短时间内找到对方,并实现交易。有关推荐系统的算法包括传统推荐算法和当前基于深度学习的算法。当前有3类基于内容、协同过滤和混合的推荐方法,其中协同过滤推荐方法由GoldBerg等人提出,基于项目或基于用户,通过矩阵的点乘积计算得分实现。目前,推荐算法引入了深度学习算法,大致说来:基于深度神经网络的DNN适用于隐藏多层的数据维度,卷积神经网络CNN训练参数较少,图卷积GNN适合推荐质量要求较高以及关注序列信息的循环神经网络RNN与LSTM等,每种方法都有不同的侧重场景。
推荐系统一般分为召回阶段和排序阶段。在召回时,快速使用简单维度的数据将百万级用户商品等数据过滤成百级。在排序期,充分利用多维度的数据来精细化筛选,输出个、十位数级。在上述两个阶段中,核心在于嵌入(Embedding)生成,旨在将高维数据映射到低维数据域,降低了计算复杂度。当前的嵌入方法包括:LLE、Laplacian Eigenmaps、Graph、HOPE的因式分解型,DeepWalk、node2Vec的随机行走型,还有GCN等深度学习型。其中,每个社交媒体根据自身数据分布情况和特点选取数据维度生成嵌入。目前,成熟的社交媒体平台采用的架构基本一致,只是在算法选择、网络层设计有所不同。Youtube采用前述,全部使用DNN方式,在召回时不再使用LSH,而是使用Spill-tree这种改进版的邻域搜索方法。Instagram采用的PinSage架构,一种基于GNN的方式。衡量推荐系统的指标包括A/B测试、精准率和响应时间等,而目前各类开源架构、开放Python功能包,在所考虑的各项指标中基本能够满足实际方面的需求。比较成熟的是Keras框架,基本囊括了大多数算法和网络层。此外,一些新兴的算法,也可以通过引包方式实现。
相对于评论文字、星级评价这些显性的特征,用户在线状态、在线时长、观看次数、点击数、购买频次、加购、收藏数则是隐性特征,需要一种可量度的方式来构建用户与商品的关联。本研究侧重隐藏特征,从用户ID、商品ID、行为类型与行为时间构建嵌入Embedding,通过Keras的DNN,实现生成推荐。
2 ? ? 研究方法及过程
本文选取基于淘宝平台2017年11月25日01:21:10-2017年12月3日17:38:11的数据,合计1亿多条。将原始数据清洗,并按照2∶8的比例随机分成训练集、测试集(图1)。
假设:研究侧重于精细化排序部分,简单地将亿条数据按用户ID大于100的条目进行删除,得到1万多条数据,近似于召回的结果。
沿用Keras的Embedding方法,使用“ReLU”“Softmax”函数进行激活,编译器为“adam”,选取“mean_squared_error”指标评估。嵌入映射部分,选用用户ID、商品ID、行为类型、时间戳等作为隐藏多维数据。其中,行为类型包括【展现-1】、【加购-2】、【收藏-3】、【购买-4】。
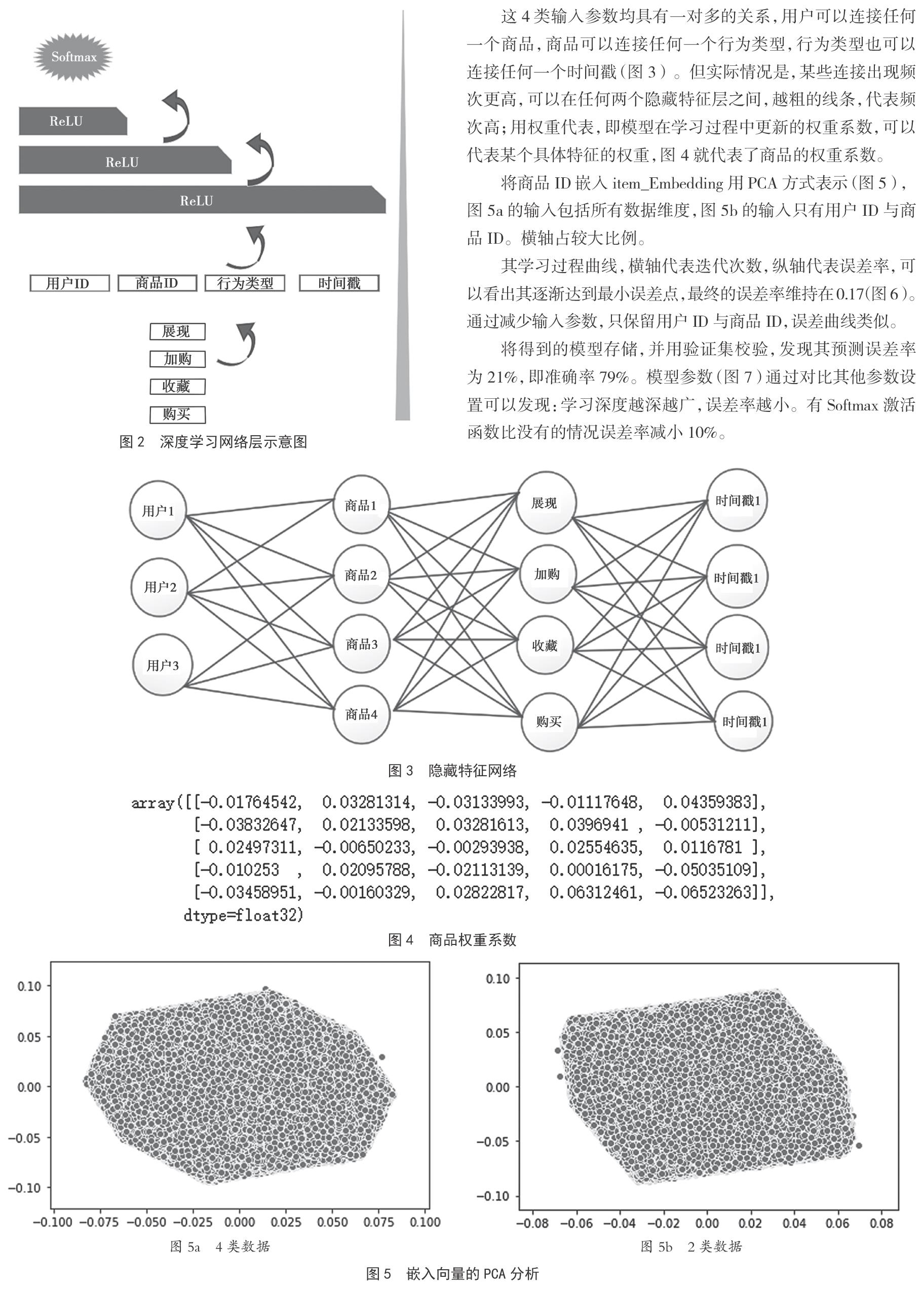
特征工程:给定某个用户ID,能够准确预测与之相近的商品ID。基于打分逻辑,该预测假设展现对应1分,加购对应2分,收藏对应3分,购买对应4分,分数越高则越是期望推荐的商品。于是将数据集做一个处理,分别用评分1~4代替原有行为类型,嵌入部分如图1所示。其中,用户ID等数据分别表示嵌入,经过Flatten之后,合并输入第一层。ReLU分别有5层,从1 028位到32位,最后通过分类函数Softmax输出(图2)。
这4类输入参数均具有一对多的关系,用户可以连接任何一个商品,商品可以连接任何一个行为类型,行为类型也可以连接任何一个时间戳(图3)。但实际情况是,某些连接出现频次更高,可以在任何两个隐藏特征层之间,越粗的线条,代表频次高;用权重代表,即模型在学习过程中更新的权重系数,可以代表某个具体特征的权重,图4就代表了商品的权重系数。
将商品ID嵌入item_Embedding用PCA方式表示(图5),图5a的输入包括所有数据维度,图5b的输入只有用户ID与商品ID。横轴占较大比例。
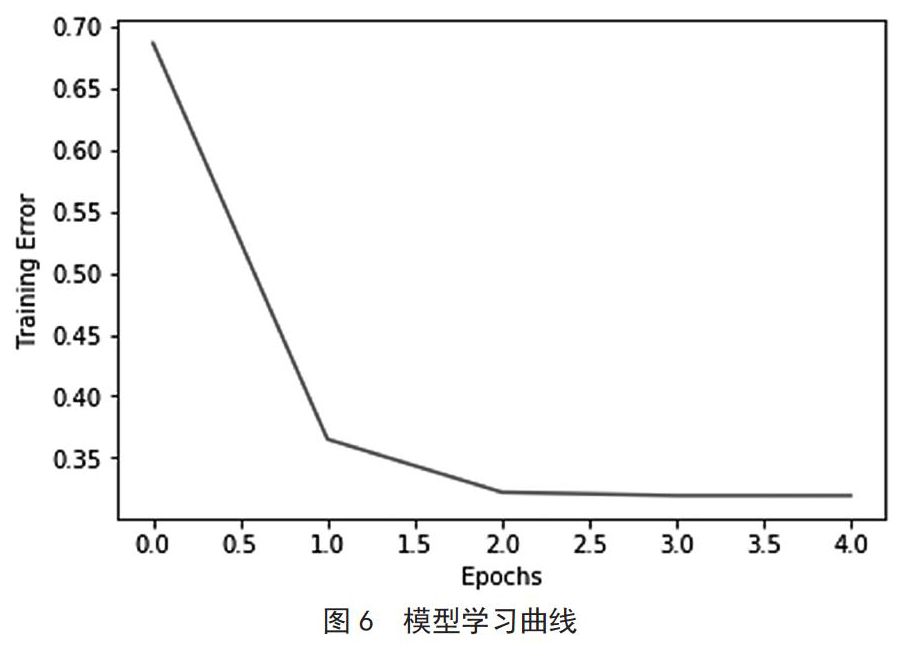
其学习过程曲线,横轴代表迭代次数,纵轴代表误差率,可以看出其逐渐达到最小误差点,最终的误差率维持在0.17(图6)。通过减少输入参数,只保留用户ID与商品ID,误差曲线类似。
将得到的模型存储,并用验证集校验,发现其预测误差率为21%,即准确率79%。模型参数(图7)通过对比其他参数设置可以发现:学习深度越深越广,误差率越小。有Softmax激活函数比没有的情况误差率减小10%。
3 ? ? 結 语
越多的数据维度参与学习就会得到越丰富的特征向量,建立的预测模型越精准。Keras框架可以实现快速设计模型,通过使用自身的Embedding方法,可以轻松实现高维空间向低维空间的映射。将用户行为类型设置为不同的等级,按照4个数据维度的网络关系(图3)进行多次迭代,发现各个节点的权重系数,最终形成网络模型,可以进行推荐。电商推荐系统是提升精准度的关键环节,可以用于召回与排序,有很多的推荐算法可以实现,但是在具体实践中,需要考虑用户的属性与数据维度。依据用户评论文字和评分会造成稀疏矩阵和冷启动问题,这里不进一步展开。因此这就意味着卖家需要靠评价提高自身获取流量的权重。这往往带来虚假交易等现象,浪费了平台很多资源,甚至花费更高的成本去监管。随着推荐系统的成熟,快速匹配相似度高的交易已经成为趋势。电商平台将隐藏维度的数据引入推荐系统中,模型会深刻地描绘用户画像。
主要参考文献
[1]周万珍,曹迪,许云峰,等.推荐系统研究综述[J].河北科技大学学报,2020(1):76-87.
[2]David Goldberg,David.Nichols,Brian M,et al.Using Collaborative Filtering to Weave an Information Tapestey[J].Communications of the ACM,1992,35(12):61-70.
[3]Goyal P,Ferrara E.Graph Embedding Techniques,Applications,and Performance:A Survey[J].Knowledge Based Systems,2018,151:78-94.
- 数概念:基于“历史发生原理”的教学建构
- 小学数学教材中“艺术与数学”的比较研究
- 让学生的思维穿行在数学知识的生长过程中
- 数学实验:打造学生数学学习的“四度空间”
- 量感:儿童应当具备的数学“核心素养”
- “用分数解决问题”的教学实践与思考
- 小学数学看图列式教学的思考
- 精心设计数学实验,培养数学核心素养
- 引导自主学习,提升数学素养
- 来一场翻转课堂的华丽转身
- 小学数学习题教学中核心素养提升策略
- 让学生在数学学习中自在生长
- 让学引思,让学生数学学习真正发生
- 借助类比,让数学学习真正走向自主
- “四格图”辅助解决问题的实践与思考
- 小学数学低段读图能力培养的探索
- 基于数学活动 推进概念学习
- 基于学生本位 引导数学交流
- 老师,除法有分配律吗
- “以学定教”引探究 “深度学习”促发展
- 逐梦平衡:在预设与生成的路上阔步前行
- 多想一步,在“想”中培养数学核心思想
- 运用“适时等待” 优化数学学习
- 在对话中提升数学教学
- 对“有效使用、开发教材”的再思考
- cuticle
- cuticles
- cuticular
- cut in
- cuting in
- cuting out
- cut in on
- cut in (on sb/sth)
- cut in (on somebody/something)
- cut-it
- cut it
- cut it fine
- cut it out
- cut-it-out
- cutleries
- cutlery
- cutlet
- cutlets
- cut my wisdom teeth
- cut-no-ice
- cut off
- cut-off
- cutoff
- cut off/down
- cut off from
- 须菩提
- 须蕊
- 须要
- 须貌
- 须铁树开花。
- 须陀
- 须面
- 须顷
- 须须
- 须髭
- 须髯
- 须髯如戟
- 须髯张开如戟
- 须鬛
- 须鬣
- 须鲸
- 须鲸类口部的角质薄片
- 须麋
- 须麋冠带
- 须(稀)少
- 须(虚)心
- 顼
- 顼顼
- 顽
- 顽习