杨圆飞 田萱
摘 ? 要:论文、代码及数据集是计算机科学领域的重要研究资源。但论文种类繁多,论文及其相关资源(如代码和数据集)散落在个人电脑上难以查找和共享,导致资源管理效率低、成本高,并容易导致资源泄露或丢失。在当前信息时代,提高研究资源信息化水平具有重要现实意义。文章为北京林业大学信息学院文本挖掘与智能信息处理研究团队设计开发了一套研究资源共享平台,该系统旨在对团队的论文、代码及数据集资源进行统一管理,厘清资源之间的相互关系。该系统具有资源检索、资源上传和下载、数据统计功能,能够帮助团队提升研究效率,节约团队成本。
关键词:资源共享;信息管理系统;Spring MVC(Spring Model-Viewer-Controller)框架
中图分类号:TP315 文献标志码:A 文章编号:1673-8454(2020)11-0092-05
随着我国科学研究工作如火如荼地进行,研究者面临着大量的论文阅读,而这些论文往往涉及许多附加资源。以计算机科学领域来说,论文中可能涉及算法代码和实验数据集,而这些资源作为科学研究的主要参考资料,具有难收集、不易管理等特点。事实上,目前这些研究资源的管理并没有特别好的自动化管理方式,可能仅仅在需要某些论文或其附加资源时才会去检索、下载、阅读,并且在使用完后可能就被清理了。这种原始手工的资源管理方式带来了大量重复劳动,而且效率低下。此外,在人工管理过程中,研究资源在硬盘文件系统中往往只保存为一对多的关系,例如一篇论文的代码或数据集与该论文存放在一起,但如果另一篇论文引用了相同的数据集,则需要把数据集再拷贝一份与之一起存放,这就会带来数据冗余。并且,如果仅仅通过电脑桌面上的文件资源管理器很难查看数据集、代码和论文的引用关系,不利于研究资源的高效利用和管理。事实上,随着研究工作的深入,相关研究资源数量越发庞大,如何高效管理和利用这些数量巨大的论文及其附加资源越来越成为研究人员面临的难题。
一、研究资源管理存在的问题
笔者通过对北京林业大学信息学院文本挖掘与智能信息处理团队的分析,发现目前研究资源的管理仍然存在以下问题。
第一,研究资源缺少管理方案,共享困难,需要的时候通过网络渠道下载后保存在个人电脑的硬盘中,共享的时候直接通过网络从一方的PC上发到另一方的PC上,步骤烦琐,而且论文与代码或数据集常常是相关的,这种直接发送文件的方式容易让论文与代码或数据的关系产生混乱。
第二,研究资源查找和共享效率低。如果团队成员想要查找相关资源,需要自己再去查找,不能利用其他成员已经做过的工作。如果想利用其他成员已经查找的结果,则必须求助于其他团队成员,如果团队有10个成员,那么至多需要与9个成员沟通才能够拿到需要的资源。
第三,团队贡献难以追踪。当团队成员离开团队,其所阅读的论文、整理的代码及数据集无法得到有效评估和高效复用,因此无法精确衡量该成员在团队期间所做的工作。
二、研究资源共享平台的优点
笔者结合成熟的Web系统开发技术,依托北京林业大学信息学院文本挖掘与智能信息处理研究团队的业务需求,针对团队研究资源设计开发了一套集资源检索、资源上传和下载、数据统计为一体的Web系统。
该系统设计了一套研究资源的管理方案,将资源管理角色分为资源上传者和资源管理者两类。资源管理者是系统的管理员(下称系统管理员),能够管理用户和资源。资源上传者(下称普通注册用户)是团队的研究成员,能够上传、下载、检索和评价资源。其中,普通用户在对资源发表评论时,可以引用系统中的其它资源,这将给团队的资源交流带来极大便利。团队用户在检索时,不仅可以按照资源领域进行分类检索,还可以根据资源领域的不同、资源类型的不同及关键词进行组合查询。
本系统具有数据统计功能。为了使系统管理员了解系统资源情况及用户使用情况,该系统会对系统中资源的数量、访问量、下载量,普通用户上传资源的情况、评论的情况进行统计,并对这些数据进行可视化展示,以便管理员对其团队成员的贡献进行了解。
此外,本系统还具有消息提醒功能,当普通用户上传的资源被评论或附加资源时,系统会自动通知用户,以便用户能够及时地了解自己所上传资源的最新情况,用户登录后就能够看到消息提醒。
三、Web系统的架构
研究资源共享平台底层,根据实际业务存储论文及附加资源的基本信息,以及用户的基本属性。上层以流行的Web技术构建系统,为用户提供良好的交互体验。系统提供对研究资源的上传和下载服务,所有的研究资源都将被系统统一管理和存储。
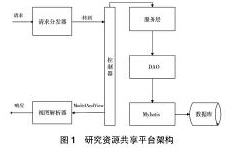
研究资源共享平台为典型的B/S架构,以成熟的MVC(Model-View-Controller)架构SpringMVC作为依托。该架构由请求分发器(RequestDispatcher)、控制器(Controller)、視图解析器(ViewResolver)三大核心组件组成,后台还包括服务层(Service)、数据持久层,如图1所示。
其中,请求分发器接收来自浏览器的请求,并根据请求路径查找控制器。之后,将请求交付给控制器处理。控制器层是系统的核心,主要负责业务代码组织及控制页面跳转。每个控制器接收用户请求,并调用一个或多个服务层提供的服务实现业务功能。处理完成后,控制器会向视图解析器传递一个ModelAndView对象。该对象由Model和View组成。Model指的是数据,View指的是视图。一般地,视图要呈现给浏览器HTML页面,而Model要在HTML页面上显示数据。视图解析器就是把HTML页面和数据结合起来,构造一个动态的网页返回给用户。数据访问对象(DAO)和Mybatis共同构成了系统的数据持久层。其中,Mybatis是一个对象关系映射框架,它可以将数据访问对象的参数映射成关系数据库中的关系,也可以将关系数据库中的关系映射成对象。
四、Web系统的关键技术
1.存储结构设计
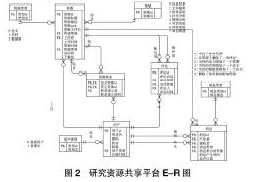
针对研究资源共享平台的需求,按照数据库概念结构设计的一般原则,通过分析系统实体之间的联系后,我们建立了实体-关系图(E-R图,Entity-Relation Model),如图2所示。该系统涉及用户、资源、评论等实体。其中,资源、资源联系、用户这三者是多对多的关系,即一个资源可以和多个资源建立联系,一个用户可以建立多个资源联系,一个资源也可以被多个用户建立联系。评论和资源有两个一对多的关系,一个是被引用关系,即表示一个资源可以被多个评论引用,另一个是被评论关系,表示一个资源可以有多个评论。 用户和消息也有两个一对多关系,一个是产生关系,一个是发送关系。一个用户可以产生多个消息,一个用户也可以接收多个消息。另外,一个资源也可以被多个消息引用。研究资源共享平台将这些实体进行了关系模式化。总共设计了9张数据表。
2.功能模块
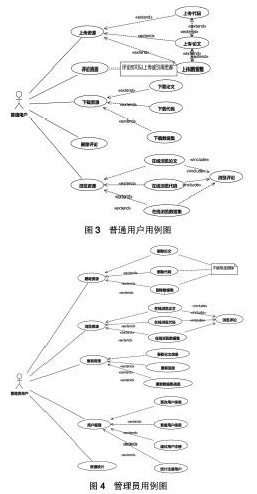
研究资源共享平台根据实际业务需求将用户分为两类,一类是普通注册用户,一类是系统管理员。这两类用户分别归属两大功能,即普通用户功能和管理员功能。如图3、图4所示。
(1)针对普通用户
对于普通用户,可以上传资源。资源包括论文、代码和数据集。论文以pdf形式上传至系统,数据集和代码以压缩包形式上传至系统。压缩包要求支持常用压缩格式,包括rar、zip、7z、tar。但对于系统中已经存在的资源,用户将不能再上传。
为了使用方便,为了能够在查看论文时就找到论文对应的代码或数据集,普通用户可以为论文附加代码或者数据集。同理,也可以为数据集或代码附加论文。无论是为论文附加代码/数据集,还是为代码/数据集附加论文,其所建立的联系是双向的。例如,为论文附加代码后,即代表也为代码附加了论文。
普通用户可以对资源进行评论。即普通用户可以为论文、代码或数据集发表评论。在发表评论时,可以仅仅发表文字,也可以在发表评论时引用一个资源。引用的资源可以是系统中已经存在的资源,也可以是临时上传的一个资源。此外,还支持用户删除评论,即对自己发表的评论进行删除。
普通用户可以下载系统中的资源。包括下载论文、下载代码、下载数据集。
普通用户可以浏览系统中的资源。包括浏览论文、浏览代码、浏览数据集及评论。
(2)针对管理员
管理员在资源浏览上,具有和普通用户一样的权限。即管理员也可以浏览系统中的所有论文、所有代码、所有数据集和所有评论。但是不能上传资源和为资源建立联系,亦不能发表评论。
管理员拥有修改资源信息的权限,即管理员可以修改资源的标题和资源的描述。
管理员可以删除资源。管理员可以对不喜欢的资源进行删除。但是删除前需要解除资源所有的附加关系。只有在一个资源没有被任何其它资源附加时,才能将该资源删除。即,如果删除的是论文,那么必须解除附加在论文上的所有代码和数据集才能完成对论文的删除。如果是代码或数据集,必须删除附加在其上的论文,才能将其删除。删除资源时,一并删除与其有关的评论、消息及磁盘上的对应文件。
管理员可以对用户进行管理,包括通过用户注册、查看用户信息、更改用户信息和统计注册用户。通过用户注册,即通过需要审核的用户。用户只有通过管理员的审核才能使用账号登录系统。查看用户信息,即查看用户的账号、密码、邮箱信息。更改用户信息,是对用户的账号、密码、邮箱的更新。统计注册用户,是对用户在系统中活动的统计,包括统计某个用户上传的论文数量、代码数量、数据集数量,上传了哪些论文、哪些代码、哪些数据集以及用户在系统中发表了多少评论。
管理员可以对系统资源进行统计。即管理员查看系统中资源数量,以及各个领域资源的分布情况。
3.基于SpringMVC的系统架构实现
该系统为典型的浏览器服务器体系结构,其中服务器后台基于SpringMVC和MySQL数据库,每个部分具体实现如下:
(1)请求分发器。该部分由SpringMVC实现,仅需要在web.xml中配置即可。配置后,Web容器将请求交由SpringMVC管理。
(2)视图解析器。可以为控制器配置一个默认的视图解析器,也可以使用注解指定视图解析器,例如@ResponseBody。本平台中同时将两者结合使用。
(3)控制器。控制器包含多个实例,每一个控制器处理一个业务逻辑,例如登录有对应登录的控制器,上传资源有上传资源的控制器。每个控制器是一个Java类中的成员函数,配置控制器不仅要在类上使用@Controller注解以表明它是一个控制器类外,还要在成员函数上映射一个URL,一般由@RequestMapping指定,当前端访问此URL时,就会调用相应的控制器(成员函数)去处理。
(4)服务层。服务层定义被多个控制器共同使用的功能,以便实现代码的复用以及功能的灵活组合。一般地,在Java类上使用@Service注解以表明这是一个服务层类。研究资源管理平台对服务层的实现甚少,仅实现了判断资源是否重复的服务。
(5)數据持久层。数据持久层负责与数据库进行交互,主要实现对数据库数据的增、删、改、查功能,实现了资源数据访问对象ResourceDAO、资源联系数据访问对象ConnectDAO等,同时通过同名的xml文件配置了对Mabatis的映射。
以普通用户资源上传为例。用户浏览资源上传界面(例如代码上传), 浏览器通过POST访问formUserJudge这个控制器。控制器调用resourceUtil,resourceUtil将计算上传资源的“标题与描述”和系统中存在资源的“标题与描述”的余弦相似性,通过判断相似性来决定上传的资源是否与系统中已有的资源重复。如果资源没有重复,浏览器再次发送POST请求调用formUserUpload控制器将文件上传至服务器,控制器会拷贝文件至服务器指定目录中,之后控制器返回给浏览器一个唯一的物理文件名。资源上传过程中,资源的逻辑文件名、资源标题、资源简介等信息通过POST提交给fromUserResourceUpload控制器,控制器将会把这些信息插入数据库中。普通用户上传资源的流程顺序图如图5所示。
另外,非法访问或传递非法参数可能使系统崩溃,为了系统安全,有必要在业务流程进入控制器之前,使用Interceptor和SpringAOP对访问权限及访问参数进行验证。如图6所示。
大部分业务过程都会判断有没有登录,如果没有登录,则不能继续访问,并强制浏览器跳转到登录界面。如果登录了,则会再次验证是否有相应的访问权限。如果遇到没有权限的情况,则认为是非法的访问。为防止不合法的参数进入控制器造成处理异常或存入数据库造成数据污染,在权限判定之后会进行参数的验证,即验证参数是否符合设定的格式、长度,例如判断邮箱格式。只有通过了权限控制和参数验证两重关口,请求才会被传送到控制器中继续处理业务逻辑。
4.Web系统的运行效果
本文以北京林业大学信息学院文本挖掘与智能信息处理研究团队为依托,设计并实现了一套研究资源共享平台,系统运行效果如图7、图8所示。该系统实现了资源的上传、下载,添加资源关联性,解决团队研究资源难以有效管理、高效共享的问题,提升了研究资源管理的效率。提供了较友好的人机交互界面,且易于上手使用。
目前,该系统已经在文本挖掘与智能信息处理研究团队的服务器上运行,获得了团队师生的肯定。该系统对推动我国高校研究团队的研究资源信息化管理具有重大意义。
参考文献:
[1]倪晓锋.基于SSM和Shiro的火电SIS系统的设计与实现[J].工业控制计算机,2019(9):131-132,134.
[2]黄秀文.Web应用系统中RBAC模型的研究与实现[J].武汉纺织大学学报,2015(3):90-94.
[3]张文龙,吴林辉,杨晨耀,蒋卫祥.基于SSM框架+vue的Web网盘系统的设计与实现[J].电脑知识与技术,2019(34):62-63,65.
[4]韩银锋.JSP技术实现上传压缩文件及文件相关信息并解压[J].电脑编程技巧与维护,2015(7):18-19.
[5]timvandermeij.PDF Reader in JavaScript.Mozilla Labs[EB/OL].https://github.com/mozilla/pdf.js, 2020-03-03/2020-03-04.
[6]張振亚,王进,程红梅,王煦法.基于余弦相似度的文本空间索引方法研究[J].计算机科学,2005(9):160-163.
(编辑:王天鹏)
- 基于社会学习理论的社会主义核心价值观培育
- 从行动到对话:走向主体间性的大学生思想政治教育
- 校企合作视野下的高职学生职业精神教育
- 基于现代职教理念对铁路货运组织教学工作的思考
- 学前教育专业实践教学资源开发与利用中存在的问题及对策探讨
- 服务地方的英语应用型人才培养模式的创新研究
- 地方师范院校体育课教学现状及对策研究
- PBL教学法在医学机能实验教学中的应用探索
- 依托精品课平台
- 高校英语教学中学生跨文化交际能力的培养策略
- 高校思政课问题教学中的教师主体性研究
- 全纳教育理念对高校思想政治教育教学的挑战与对策
- 新形势下增强“形势与政策”课教学实效性研究
- “情境教学”模式在中医护理个案分析带教中的应用体会
- 古代文学课程目标导向式教学的理论与实践
- 理工科“形势与政策”课实践教学实例模式探讨
- 教学方式多样化:切实提高“形势与政策”课的实效性
- 机械类对口本科教学方法探讨
- 可持续发展教育与高等教育的融合
- 建立通识教育课程体系促进开放教育专业建设
- 大学公共体育理论研讨课的设计与实践
- 高校图书馆管理模式应该变“书本位”为“人本位”
- 360度反馈评价在学生干部队伍建设中的应用
- 听证制度是高校学生管理工作的一种举措
- 加强内地高校少数民族学生的教育管理
- chum
- chummed
- chummier
- chummies
- chummiest
- chummily
- chumminess
- chumminesses
- chumming
- chummy
- chums
- chumship
- chunk
- chunked
- chunkier
- chunkies
- chunkiest
- chunkily
- chunkiness
- chunkinesses
- chunk-out
- chunks
- chunk's
- chunky
- church
- 加息减税
- 加惠
- 加意
- 加意卫摄
- 加成反应
- 加戴
- 加拉加斯
- 加拿大
- 加拿大时装之王
- 加拿大法语社会学之父
- 加持
- 加料
- 加日
- 加时赛
- 加权
- 加权平均数
- 加标记使区分
- 加械于颈
- 加棒
- 加楔子
- 加民
- 加水用文火煮使熟烂
- 加沙地带
- 加油
- 加油打气