
摘 要:传统的匹配技术因规则和参数固定,匹配性能和效果很不理想。基于实时大数据和机器学习技术,提出了一种新的分布式智能匹配系统,该系统根据实时匹配成功率和用户反馈进行自我优化。实验表明,系统性能可水平扩展,匹配正确率显著提高。
关键词:智能匹配;实时大数据;机器学习;分布式协调;Spark Streaming
DOIDOI:10.11907/rjdk.171722
中图分类号:TP303
文献标识码:A 文章编号文章编号:1672-7800(2017)008-0005-04
0 引言
人们通过打车软件可以匹配到最佳司机出行,亦可通过拼单软件凑团优惠秒杀;金融机构根据海量历史交易构造模型,实时侦测诈欺交易;商户根据客户群体特征分析消费趋势,从而进行精准营销。这一切,都离不开匹配技术。
匹配指事物之间有相符合或相配合的关系,匹配技术旨在以一定的目标、遵循一定的规则建立事物之间的关联,从而产生“协同效应”[1]。匹配技术一般遵循如下流程:从不同的事物中按照一定的规则提炼出特征,然后按照一定的目标去组合这些特征,能够满足预期目标则表示匹配成功[2]。传统匹配技术采用固定的规则和方法,规则不会随着实际情况发生调整和改变。实时匹配成功率较低,未成功的匹配只有等待T+1日的批量流程完成处理,难以应对越来越多的(T+0)实时场景需求。实时大数据技术[3]可以将历史匹配记录和实时信息結合起来分析,动态调整匹配规则和方法,提升了匹配的实时性和成功率,也提高了匹配效果和用户体验。
实时匹配系统大多基于实时处理框架自行开发。滴滴的实时打车平台根据地理位置、历史评分撮合乘客、司机、代驾者,采用迭代反馈算法[4],算法分批次迭代进行,每次的参数都由系统动态生成。比如,系统在匹配失败后会适当增加距离,降低评分要求,通过调整参数提高匹配成功概率。滴滴打车平台基于Lambda架构[5]设计,将实时数据和历史数据结合应用,提升匹配效果,增强用户体验,同时获取更多有价值的数据。
微软的实时数据质量监控平台是典型的“模型匹配”[6]系统。平台后端连接实时机器学习算法,通过分析实时数据和历史数据,不断完善风险模型;将结果数据与风险模型动态匹配,可监控数据质量并发出预警。
实时匹配实现具有两个特点:①结合实时数据和历史数据共同分析;②可动态调整参数,优化匹配效果。但是,由于匹配技术多是公司的核心技术和商业秘密,现有成果大多闭源,对匹配技术的研究和应用也各自为攻,因此,业内尚未形成一个主流成熟的框架。
1 实时大数据
大数据(Big Data)技术是一种数据存储和分析技术,具有5V特性[7]。大数据技术能在每日几百TB的数据增长情况下高效分析数据,并从低价值密度的海量数据中挖掘出有利于企业战略的信息。
2011年兴起的流式计算[8],被称为是后Hadoop时代的实时云计算。大数据流式计算引擎将多种数据源的数据整合并切割成小块,进而对数据进行并行处理,在流数据不断变化过程中进行实时分析,捕捉并返回可能对用户有用的信息。流式计算技术百花齐放,种类繁多,如Yahoo的S4、Twitter的Storm、Facebook的Puma,以及被称为“Hadoop替代者”的Spark和Spark Streaming[9]。其中,S4不支持“至少递送一次”的规则[10],导致其有丢失事件的风险;尽管Storm应用较多,但其性能差强人意;相较而言,Spark Streaming采用“微批量”的处理技术,处理性能较高,应用非常广泛。此外,Spark和图算法、机器学习算法天然具备兼容性,生态发展较好。
Spark是一个类似MapReduce的并行计算框架,其核心数据结构是弹性分布式数据集(Resilient Distributed Datasets, RDD),提供比MapReduce更丰富的模型,可在内存中对RDD进行多次计算和迭代,并支持复杂的图算法和机器学习算法。
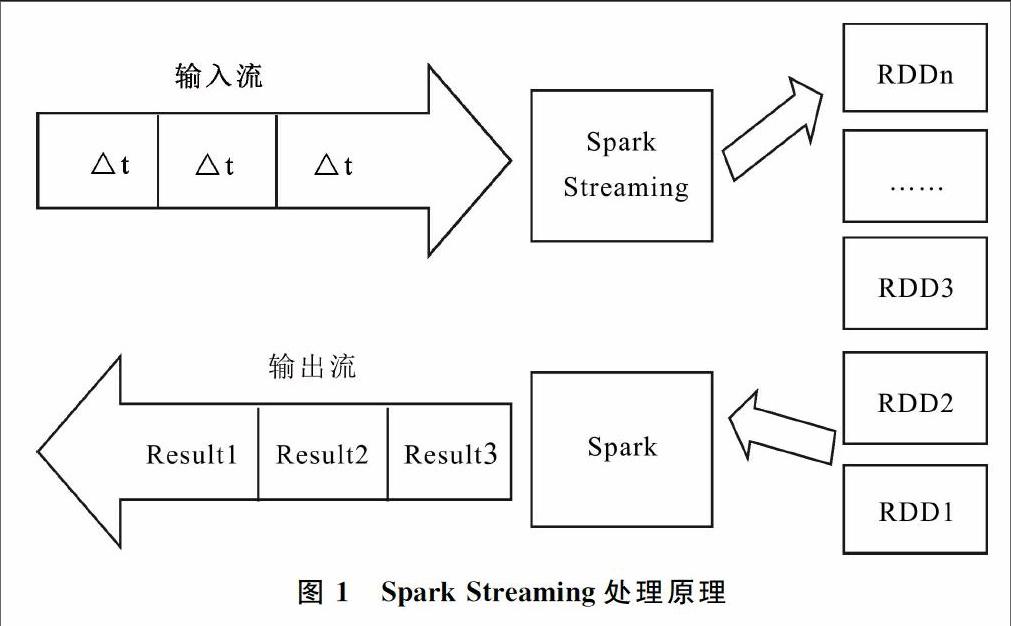
Spark Streaming是一个建立在Spark之上的实时计算框架,它扩展了Spark处理大规模流式数据的能力,复用Spark接口实现复杂的实时算法,且与Spark生态中的其它组件兼容性好。Spark Streaming处理原理如图1所示,将数据流按时间片划分为若干段数据,每一段数据作为一个RDD,处理引擎对每个RDD进行Filter、Map、Reduce等算法操作后,将其作为Spark Job提交给Spark引擎进行计算。Spark Streaming支持数百节点的分布式实时计算,具备计算的高可用、容错特性。因此,本文采用Spark Streaming作为主要的实时计算技术。
2 智能匹配系统
2.1 匹配流程
匹配系统流程如下:通过规则提取源消息的特征向量,放置于撮合引擎[11]中;撮合引擎以预先设定的目标匹配特征向量;如果匹配结果达到目标要求,则判定为匹配成功;否则,匹配失败,进入下一次匹配。
传统匹配技术采用固定的特征向量提取方式,在撮合系统中也使用固定的参数去匹配特征向量[12]。以拼单系统为例,用户有一张满500减200的优惠券,但预期消费只有300元,期望通过实时拼单系统找到附近的人一起共享优惠券,传统匹配技术算法[13]如下:
输入:特征向量
<优惠券金额,预期消费, 经度,维度>
输出:匹配结果
(1) 提取特征向量。
(2)将特征向量导入撮合引擎。
(3)撮合引擎根据预先设置参数(如向量权重,超时时间)匹配附近的人。
(4)匹配成功,则返回配对信息。
(5)匹配失败且未超时,则返回步骤(2)继续匹配。
(6)匹配失敗且超时,则返回匹配失败。
如果参数配置不合理,将可能导致客户等待时间太长、匹配失败、距离太远、总体消费金额太多等问题,从而导致客户流失。此外,由于客户向系统发送的数据仅是固定的特征向量,客户的其它信息(如历史消费次数、信用等级、消费路线等)并未在匹配算法中占有权重,可能使不诚信用户被频繁推送,从而导致拼单系统无法精准推送优惠券,用户体验效果不佳。
可见,传统匹配技术无法跟上服务升级速度[14],也无法满足需求的时效性和准确性,本文提出基于实时大数据的智能匹配系统,能有效解决以上问题。
2.2 匹配系统总体设计
2.2.1 节点设计
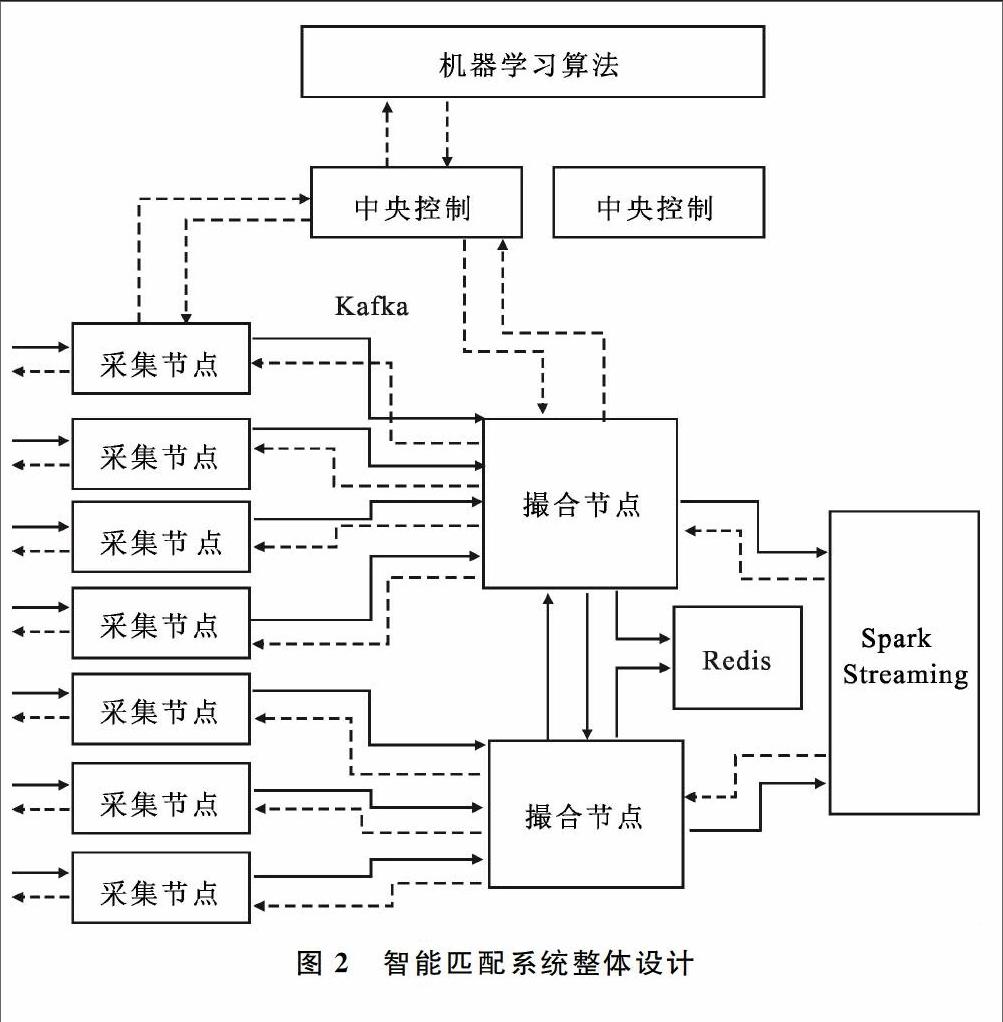
智能匹配系统采用分布式部署结构,有3类角色:
(1)中央控制节点:负责存放当前的特征提取规则以及匹配参数(向量因子权重、超时时间等),实时接收采集节点和撮合节点反馈,调用后端机器学习算法调整模型,并修正规则和参数。
(2)采集节点:负责从多个客户端收集用户请求信息,从中央控制节点获取特征提取规则,按规则对信息进行特征提取,并生成统一格式的报文通过Kafka发送给撮合节点。采集节点会收集用户的反馈信息,并向中央控制节点进行反馈。
(3)撮合节点:撮合节点负责接收采集节点发过来的信息,按照一定规则,以预先设定的目标进行撮合。撮合节点和中央控制节点保持通信,随时根据中央控制节点参数调整撮合行为。撮合节点根据匹配成功率、匹配效果向中央控制节点反馈。
2.2.2 运行机制
用户将匹配请求发送到采集节点,采集节点根据从中央控制节点获取的特征提取规则,对原始请求进行规则提取和规范化处理,得到特征向量,并将这些特征向量按不同主题发送给不同的撮合节点。撮合节点根据从中央控制节点获取的匹配参数(例如向量中不同特征的权重)及匹配目标,将采集节点传来的特征向量流封装成若干分布式弹性数据集(RDD)以及一系列操作[15],将其提交给Spark Streaming进行匹配处理。Spark Streaming分为多个微批次进行处理,每次处理后都会存在一些匹配失败的特征向量。撮合节点将这些向量暂时缓存在Redis[16],积累到一定数量后,根据机器学习算法结果调整参数,再次封装为RDD提交给Spark进行二次匹配。撮合节点还会根据匹配成功率、匹配效果向中央控制节点进行反馈,以帮助中央控制节点标记参数样本[17],进行自我优化。系统整体设计如图2所示。
以实时拼单系统为例。实时拼单系统能够帮助用户凑单消费优惠券,例如用户A发布了一个请求:持有一张满500元减200元优惠券,且期望消费300元。理想状态是系统能帮助A找到一位期望消费200元的搭档B,但实际情况可能找到的是消费230元的用户B。这次匹配也是成功的,只是匹配效果有所下降。此外,智能拼单系统能通过地理位置、历史评价等信息综合匹配,同时能根据用户反馈和实时匹配成功率进行自我优化。本方法中,多名用户各自提交原始请求到采集节点,采集节点根据特征向量提取规则提取出特征向量λ=<票券门槛,期望消费,经度,纬度,评价分>,将票券类型哈希后发送到某个撮合节点(哈希可以保证同一类型的票券都落在同一个撮合节点上)。采集节点同时也会接收用户的反馈信息,并通知给中央控制节点。撮合节点从中央控制节点获取匹配参数,例如向量中的5个因子对匹配结果的影响权重,将特征向量流封装为RDD,将匹配算法封装为基于RDD的运算,将其提交给Spark Streaming进行运算。本次运算未能匹配成功的向量将被缓存到Redis中进行下一次运算;同时撮合节点将向中央控制节点反馈匹配结果。
3 智能匹配系统实现
3.1 中央控制节点
中央控制节点主备2个,只有一个节点处于活跃状态,另一个节点随时处于待命状态,主备节点共享存储。中央控制节点用于存放当前的特征提取规则以及匹配参数(向量因子权重、超时时间等),实时接收采集节点和撮合节点反馈,调用后端机器学习算法调整模型,并修正规则和参数。机器学习算法持续接收反馈,不断迭代更新模型,直到模型稳定。每当规则和参数发生变化时,都会发起一次同步请求,将信息同步到采集节点和撮合节点。
3.2 采集节点
采集节点收集用户原始请求,并根据最新的提取规则提取出特征向量,将向量规则化后通过Kafka发送给撮合节点。采集节点同时会收集用户的反馈信息,比如匹配结果是否满意、等待时间是否太长等,同时向中央控制单元汇报。
采集节点可通过Redis缓存一些用户请求,然后集中进行处理后发至Kafka队列,以提升系统吞吐量;接收数据时,也可一次接收多个用户请求,再逐一通知给用户,如图3所示。
3.3 撮合节点
撮合节点封装了核心匹配算法。Spark Streaming将撮合节点接收到的流数据划分成段,每一段对应一个RDD,撮合算法只需要定义基于这些RDD的运算即可。简单撮合算法思路是:先对数据集进行排序,然后从头遍历数据集,对每一个元素从尾部寻找和它匹配的元素;如果匹配,则移除匹配成功的所有元素,如果不匹配,则该元素进入下一次匹配。整个过程迭代数次,直至结果集稳定,伪代码如下:
sort(dataSet)
while(iteration_times>0)
do
for( element in dataSet)
find element from the dataset match the destination from the tail
if(match)
remove matched elements
fi
done
done
由于传入的向量是多维度的,上述代码需要修改为:在满足既定条件情况下,按照其它因子选取最优解。例如在拼单系统中,两名用户的凑单金额高于消费券的最低消费额即为匹配成功,但是两位用户的距离和信用评价将影响最优匹配结果,而这些因子的权重是由中央控制节点提供的。撮合节点不断反馈匹配成功率和匹配效果,以使中央控制单元不断优化参数,具体实现如图4所示。
此外,RDD中应包含实时数据和历史数据。算法在处理用户的实时请求时,可根据用户的关键域信息(例如用户ID、活跃时间等)从HBase中查询到该用户的历史请求明细,并分析该用户的信用、行为、消费习惯、偏好等特征,从而为用户选择更合适的匹配对象。
撮合节点对一个RDD的匹配计算不一定让所有消息都完美匹配,那些没有匹配成功的消息将被缓存进Redis,加入下一次匹配。
4 实验分析
4.1 实验环境
实验节点标准配置:主处理器4核心3.2GHz主频,内存16G;实验载体为本文实时拼单系统;以卷积神经网络(CNN)作为后端机器学习引擎的实现技术。
4.2 实验1:性能测试
实验目的:测试本系统性能和水平扩展性。
实验配置:(初始)4个采集节点,2个撮合节点,40节点Spark集群。
实验过程:①客户端不断增加模拟用户请求,直至性能瓶颈;②横向扩容采集节点和撮合节点,观察实时TPS。
实验数据:初始配置(6节点),匹配成功的TPS峰值为4.2万左右;扩容系统至9节点,TPS峰值为6.5万左右;扩充系统至12节点,TPS峰值为7.9万左右;最终扩充到21个节点时,TPS的峰值为12万左右。实验结果如图5所示。
图5 性能测试 图6 动态优化
在该过程中,系统处理延迟基本处于稳定状态,随机用户的期望匹配延迟小于1.6s。
实验结论:本系统处理性能优异。根据已公布数据,本系统相比于滴滴实时匹配系统,相同集群规模的吞吐量提升了41%,处理延迟减少了25%~60%。
实验分析:本系统采用Spark Streaming微批量处理技术,相比于滴滴的Smaza,极大提升了处理能力;采用流批数据并行处理的设计思想,极大减少了处理延迟。
4.3 实验2:动态优化
实验目的:证明本系统可根据实时匹配率和用户评价进行反馈式学习,不断优化自身参数,提升匹配效果。
实验配置:4个采集节点,2个撮合节点,40节点的Spark集群,20节点的CNN深度学习网络。
实验过程:启动系统,记录实时匹配成功率和TPS,持续60分钟。
实验现象:开始时匹配成功率较低且剧烈震荡,随着深度学习算法的运行,参数不断调整,成功率开始显著提升,60分钟时趋于稳定,成功率大约在78%左右,实验结果如图6所示。
实验结论:本系统能根据实时匹配结果进行自我优化,能够自动提升匹配成功率。
实验分析:本系统能根据实时匹配结果进行反馈式分析,动态调整匹配参数,增加匹配成功率;并能结合用户的历史信息进行分析,做到“投其所好”,提供更人性化的匹配结果。
5 结语
传统的匹配技术因规则和参数固定,匹配性能和效果很不理想;基于实时大数据的匹配技术是各公司的核心技术和商业秘密,现有成果大多闭源,研究和应用也各自为攻,尚未形成一个主流成熟的框架。本文提出了一种基于大数据匹配技术的通用技术框架。该框架易搭建,采用分布式架构,支持水平扩展,性能优异,相对于业界主流系统,吞吐量提升了41%,匹配延迟减少了25%以上;结合实时数据和历史数据分析,匹配结果更精确;后端搭配机器学习算法,可主动优化匹配效果。
参考文献:
[1] 朱海燕, 蔡铭, 金连甫. 网络化制造系统中的服务智能匹配技术研究[J]. 计算机工程与应用, 2004, 40(18):137-140.
[2] 郭会, 王丽侠. 基于个性化需求的拼车路径匹配算法研究[J]. 计算机技术与发展, 2017(1):57-60.
[3] 邱雪涛, 赵金涛. 基于实时大数据处理的交易欺诈侦测的研究[J]. 软件产业与工程, 2013(4):36-40.
[4] 顾军华, 任超, 谭庆. 基于正反馈机制的遗传算法[J]. 计算机工程与应用, 2007, 43(14):73-74.
[5] 苏树鹏. 基于Lambda架构的移动互联大数据平台架构的设计与应用[J]. 企业科技与发展, 2016(6):66-68.
[6] 方幼林, 杨冬青, 唐世渭,等. 数据仓库中数据质量控制研究[J]. 计算机工程与应用, 2003, 39(13):1-4.
[7] 孟小峰, 慈祥. 大数据管理:概念、技术与挑战[J]. 计算机研究与发展, 2013, 50(1):146-169.
[8] 孙大为. 大数据流式计算:应用特征和技术挑战[J]. 大数据, 2015, 1(3):99-105.
[9] 夏俊鸾, 邵赛赛. Spark Streaming:大规模流式数据处理的新贵[J]. 程序员, 2014(2):44-47.
[10] NEUMEYER L, ROBBINS B, NAIR A, et al. S4:distributed stream computing platform[C].IEEE International Conference on Data Mining Workshops,IEEE Computer Society, 2010:170-177.
[11] 吴媛,李雄德, 陈正军. 信息供需互助平台中智能撮合算法研究与设计[J]. 中国陶瓷, 2009(4):36-38.
[12] 唐亮贵,李双庆, 程代杰. 基于多主体的撮合交易模型及算法研究[J]. 计算机工程与应用, 2003, 39(23):145-147.
[13] 李世梁.实时全额支付系统中基于基本环的高效多边撮合算法分析和设计[J]. 计算机应用与软件, 2016, 33(9):296-300.
[14] 佚名.大數据时代[J]. 中国电子科学研究院学报, 2013, 8(1):27-31.
[15] S GUPTA. Learning real-time processing with spark streaming[EB/OL].http://www.bokus.com/.
[16] CARLSON J L. Redis in action[J]. Media,johnwiley, 2013(3):157-159.
[17] 尹宝才, 王文通, 王立春. 深度学习研究综述[J]. 北京工业大学学报, 2015(1):48-59.
- 初中文言文阅读教学语感化研究
- “真学课堂”视角下小学语文课堂教学策略探寻
- “课程思政”视域下高职语文教学改革探索
- 巧用情景教学法,提高初中语文教学有效性
- 基于整本书的高中语文阅读教学研究
- 李白的走与留
- 在深度学习视阈下谈小说整本书阅读指导
- 阅读“真”童话,滋润儿童精神世界
- 浅析如何在中职语文教学中培养学生的职业素养
- 新高考背景下高中语文整本书阅读有效指导策略探讨
- 小学语文与经典名著融合浅析
- 语文核心素养下课外阅读对提升高中生素质的启示
- 题西林壁
- 课外阅读的秘密
- 触摸汉字的脉搏
- 传统汉字构形理论在小学低年级识字教学中的运用策略研究
- 思维训练,高中语文阅读教学的诉求
- 基于任务情境的写作教学探究
- 小学语文群文阅读教学和课外阅读指导融合策略的初探
- 初中语文阅读教学中的策略探究
- 高三语文写作教学中类型作文教学法的应用探析
- 关联阅读在教学中的应用
- 小学语文阅读教学中读写结合教学模式的应用分析
- 高中语文学生阅读能力培养策略
- 初中语文写作教学中如何有效应用情景教学
- elderly
- elders
- elders'
- elderships
- elder²
- elder¹
- eldest
- elearning
- elect
- electability
- elected
- electee
- electees
- electee's
- electing
- election
- electional
- electioneering
- elections
- elective
- electively
- electiveness
- electivenesses
- electives
- elector
- 显显
- 显显令德
- 显显翼翼
- 显晦
- 显暴
- 显服
- 显服蟒袍
- 显朝
- 显本事
- 显本领的时候了
- 显比
- 显民
- 显没
- 显派
- 显涂
- 显灵保佑
- 显烈
- 显焕
- 显然
- 显爵
- 显父
- 显状
- 显猷
- 显王
- 显现