进入2016年,在国家政策导向和大数据技术发展的整体趋势下,“大数据”已经成为最火热的词汇,引爆各行各业。上至国家战略层面,下到大数据产业链的各个环节,都开始对大数据进行研究与探索。作为人才的高地与源头,中国教育领域的大数据建设也迅速提上议程,成为今年教育信息化最热的话题。
那么教育行业该如何根据自身特性去建设、落地教育大数据,大数据到底能为现代教育带来怎样的价值与效益?在此,本人根据三盟科技近几年在教育大数据上取得的一些研发成果、教育大数据应用落地过程中遇到的问题及建设方法经验,浅谈一下教育大数据到底该如何真正落地,并与业内同仁共同分享,一起探讨,共同助力教育大数据快速健康良性发展。
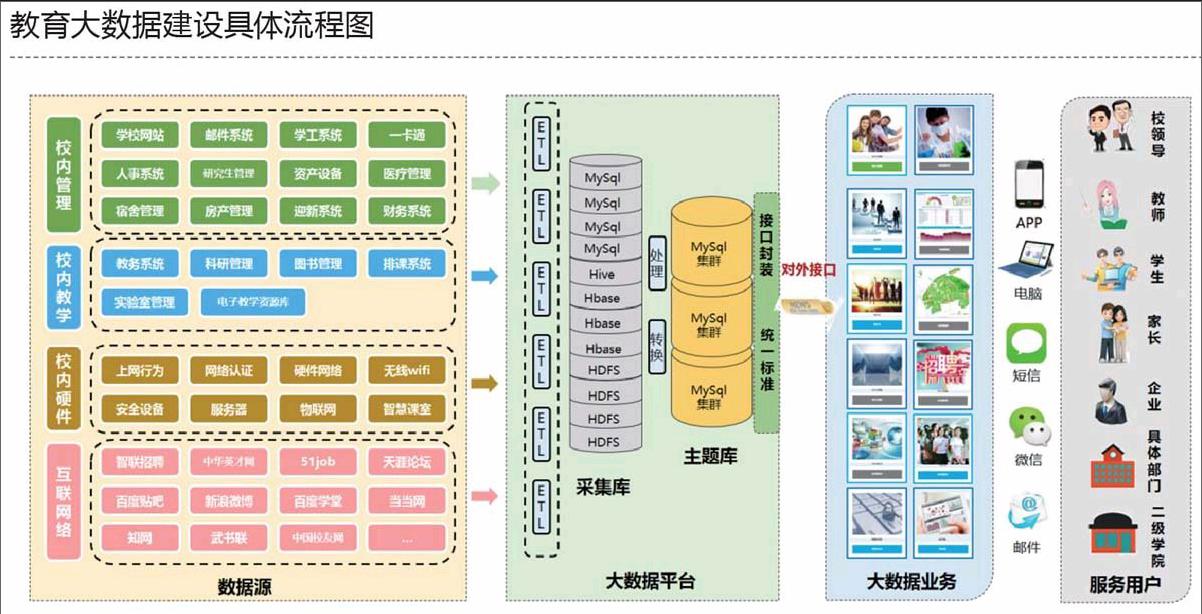
教育大数据整体建设流程
如上图所示,教育大数据能够真正落地,主要经历了对数据源层数据的采集整理、大数据平台的搭建、业务的开发,然后通过移动APP、电脑、短信、微信、邮件等方式为具体的教育用户服务。
数据源层数据的采集整理
教育大数据系统的构建基于学校沉淀的数据,只有将学校散落在各个系统里的数据进行集中采集,统一存储,然后进行深度挖掘和分析,才能真正让这些数据为教育教学和管理所用,服务到教育用户。
目前,数据源层的数据主要来自校内管理、校内教学、校内硬件和互联网络四个层面。其中校内管理、校内教学业务系统产生的数据,以结构化为主,是学校管理教学的核心数据,现阶段很多高校自建的数据分析平台,数字化校园厂商提供的大数据服务主要是基于这部分数据;校内硬件设备、互联网上的数据,包含了大量的半结构化和非结构化数据,也是数据源极其重要的一部分,是现在教育大数据发展的重要方向。
大数据平台的搭建
在完成数据的采集以后,需要把采集到的四类数据统一存储到大数据平台,然后对这些采集到的数据进行清洗、整理、转换,统一标准,接口封装,最后提供统一的对外接口,为具体的大数据业务提供所需的数据。
考虑到所采集的数据特性,统一的大数据平台需要包括结构化数据中心和非结构化数据中心两个部分,同时要求数据仓库平台是分步式,并且是多数据库整合模式,以满足高校多种类型的数据源,较高的数据处理和存储要求,以及新增数据的持续扩展。同时还需要支持图形化管理,用于校内管理人员日常运维管理。
大数据业务开发
大数据业务的开发可以说是大数据能为教育行业真正所用的最重要的一环,只有结合每个学校的特性与需求,开发出所需的业务应用模块,我们的学校管理者、教师、学生才能真正感受到大数据的存在,才能利用大数据去变革传统教育教学管理模式,为学校各级领导、教师、学生带来宏观层面以及微观个体的综合服务。
目前,三盟科技主要研发出了“学校概况”、“我的大学”、“行为画像”、“综合预警”、“舆情分析”、“招生就业”和“安全大数据”等七大业务应用模块,分别从教学就业、学生服务、学校管理三大维度,为学校构建了整体的大数据环境,实现了“因材施教”的个性化教学、全校可视化和预测性管理,学生综合性和精准性的就业服务等,充分利用和呈现了大数据在教育行业的应用价值,构建了持续化的发展能力。
特别值得一提的是,由于高校各部门需求差异大,因此高校大数据讲究标准化与开放性,以便各类公司、学校部门师生均可以参与,共同开发出所需的大数据分析业务。2016年开始流行的高校大数据服务大厅理念,可以预见其将成为未来的发展趋势。高校大数据服务大厅除了提供大数据分析结果服务外,还能够提供原始数据服务,因此技术上需要大数据仓库平台提供统一的服务接口。学校老师、各类公司不用关心数据存储的具体位置,也不需要学习Oracle、hadoop等数据库,只需要使用最简单的SQL语句就可以调用整个数据仓库的相关数据,进行大数据业务的开发;开发出的大数据分析业务,通过电脑、手机、邮件等现阶段主流方式,为学校用户、校外社会用户提供服务。
教育大数据具体实现技术
教育大数据真正应用与落地,在技术实现层面,主要涉及到大数据建设的五大关键领域,包括数据采集、清洗和质量管理、存储及建模、分析及挖掘、展现和应用,同时涉及整个软硬件环境和安全保障整体性设计。 由于篇幅有限,在这里,我们主要谈一下数据的采集、清洗和建模三个部分:
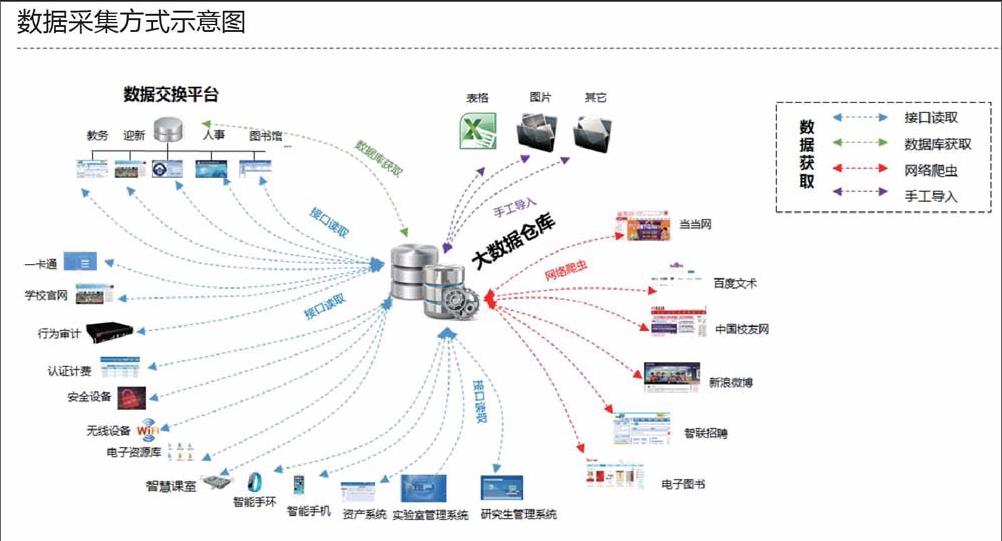
数据采集
教育大数据系统的数据源分为业务系统、硬件设备、互联网三大类,数据格式类型丰富;每類数据源的数据量大小和数据质量差异很大,需要采用不同的存储技术;同时还面临业务系统间独立建设、相互割裂、数据标准不统一、数据接口难协调等问题。因此,教育领域的大数据系统需要根据数据特点和应用要求,定制设计大数据系统的数据采集方案,规划和设计每个系统的采集方式、采集频率、存储方式和采集时间等。
针对高校数据类型丰富、应用服务复杂、数据特点差异大等情况,三盟科技开发了一套数据采集工具,对当前已经构建的信息系统、硬件设备和互联网的数据进行采集。数据采集的接口包括DB接口、Socket接口、Webservice接口、Syslog接口等,在这过程中对采集到的数据进行质量监控和管理。对于非系统化的数据,比如表格、文字等,可以通过人工方式录入到大数据系统。总体而言,数据采集包括系统专有接口、数据库接口、网络爬虫和手工导入四种方式,具体采集方式的选择原则如下:
接口读取
对于实时性要求较高的系统,需要通过接口进行采集,如一卡通、上网行为审计、认证计费设备等。
数据库获取
对于静态性强的系统,如教务系统,可以采用数据库读取的方式,但是这种方式工作量较大,而且实时性不高。
网络爬虫
互联网上的数据,如新浪微博、当当网、就业网站等。
人工导入
非系统的数据可以人工导入大数据系统。
目前,很多学校已经建设了数据交换平台,整合了高校常见的业务数据。因此,这类学校可以通过数字化校园厂家提供的数据字典或者视图,直接从数据交换平台中获得所需要的相关数据。
数据清洗
由于学校数据源缺乏有效的数据分析技术,同时在数据录入时,可能会存在因输入错误、数据来源不同而导致的各类“脏数据”,所以,通过数据清洗,对“脏数据”进行剔除或修正,提高整体数据质量显得十分必要。
教育数据清洗的对象主要包括传统的关系型数据库,XML半结构化数据,以及以视频、音频、文本和其他形式存在的非结构化数据。常见的数据问题主要包含残缺数据、错误数据和重复数据三大类。由于学校业务系统之间数据源的差异性,这就需要根据实际情况定制出适合该校的数据清洗规则和流程,从而保障数据质量。以下是高校数据源清洗的通用流程:
1、分析数据源的数据是否满足业务规则和定义,是否存在非正常的数据结构;
2、读取采集后的结果集,进行数据属性适配;
3、获取数据清洗规则;
4、进行数据匹配;
5、正常数据放入清洗结果集,异常数据放入异常结果集;
6、把结果集入库,并记录清洗结果。
数据建模
数据建模是抽象描述现实世界的一种工具和方法,是通过抽象组织实体及实体之间联系,来表示现实世界中事务相互关系的一种映射。数据模型是整个数据底层建设中的关键部分,数据仓库的数據模型架构与数据仓库的整体架构紧密关联,不仅是对业务进行抽象划分,更是对实现技术进行具体的指导,它涵盖了从业务到技术实现的各个部分;根据数据建模分阶段的设计,数据仓库的数据建模一般分为业务建模、概念建模、逻辑建模、物理建模四个阶段:
第一阶段:业务建模
划分高校业务,一般按照业务部门(如后勤处、教务处、图书馆等)划分,并界定各部门之间的业务工作、理清部门之间的关系。
深入了解各业务部门的具体业务流程并将其程序化。
提出改进业务部门工作流程的方法并程序化。
数据建模的范围界定,数据仓库项目的目标和阶段划分。
第二阶段:概念建模
抽取关键业务概念,并将之抽象化。
将业务概念分组,按照业务主线聚合类似的分组概念。
细化分组概念,理清分组概念内的业务流程并抽象化。
理清分组概念之间的关联,形成完整的概念模型。
第三阶段:逻辑建模
业务概念实体化,并考虑其属性内容。
事件实体化,并考虑其属性内容。
说明实体化,并考虑其属性内容。
第四阶段:物理建模
针对特定物理化平台,做出相应的技术调整。
针对模型的性能考虑,调整Hadoop平台与Mysql平台。
根据管理需要,结合特定平台,做出相应的调整。
生成最后的数据结构实例并完善。
在教育大数据建设中,数据建模设计要将学校的一卡通、教工、图书馆、后勤管理、科研等现有数据系统进行统一整合。不同业务系统均有各自固有的数据模型,为了让数据模型更好地适应现有环境、具备较好的数据处理速度,数据原型可采用雪花模型或范式模型进行设计。根据上图的设计方法,教育大数据系统设计的核心共享库、分析库与采集库均遵循上述方法进行数据建模与数据实例的建立。
以上便是教育大数据落地过程中涉及到的部分技术。当然,影响教育大数据真正落地的因素有很多,这里只谈到了很少的一部分,而且还存在很多未知的领域,有待我们去共同探讨。总之一句话,教育大数据发展潜力巨大,实施落地意义重大,将为我们的传统教育变革带来无限可能。
- 城乡建设用地增减挂钩项目审批系统的构建
- 喀左县平房子村脱贫攻坚实践探索
- 高等农业院校科技兴农问题研究
- 沈阳经济区农产品“三品一标”发展策略研究
- 辽宁粮油主导产业发展形势分析
- 辽宁省农产品质量安全监管服务平台的构建与应用
- 辽宁绿色农业发展探讨
- 辽宁省农产品检测机构的转型与发展
- 以农产品加工业推动现代农业产业园三产融合发展的思考
- 辽宁省区域生态循环农业发展典型模式探讨
- 新疆地区林业保护与发展措施
- 花生机械化收获模式及机具研究
- 果园自走式施肥开沟机田间性能试验研究
- 新型样冲结构设计与应用
- 多功能铺膜滴灌播种施肥机的设计
- 2BSM210型水稻种膜覆膜直播机的设计研究
- 轮盘式切碎器自动磨刀装置的设计
- 农业农村部:到2025年水产养殖机械化水平总体达到50%以上
- 凤城市玉米高产栽培现状与对策
- 卓越农林人才培养背景下教学科研互动促进教学模式研究
- 食品专业创新创业人才促进解决“三农”问题的对策
- 辽宁乡村文化发展的制约因素与对策
- 检验检测实验室安全管理机制、制度及措施
- 社会嵌入视角下农业经济增长影响因素分析
- 新农村建设背景下的农业经济管理
- foal
- foaled
- foaling
- foals
- foam
- foamable
- foamed
- foamer
- foamers
- foamier
- blearinesses
- bleary
- bleary-eyed
- bleat
- bleated
- bleater
- bleaters
- bleating
- bleatingly
- bleats
- bled
- bleed
- bleeding
- bleeding-edge
- bleedings
- 鸩醴
- 鸩鸟
- 鸩鸟【同义】总目录
- 鸪
- 鸫
- 鸬
- 鸬慈
- 鸬鸠之仁
- 鸬鸠之平
- 鸬鹚
- 鸬鹚不打脚下塘
- 鸬鹚笑
- 鸬鹚酒
- 鸭
- 鸭信
- 鸭儿
- 鸭儿广
- 鸭儿盒盒
- 鸭农
- 鸭卵
- 鸭叫声
- 鸭吃大椒
- 鸭吃田螺鸡吃谷——各自修来的福
- 鸭吃砻糠——一场空欢喜
- 鸭哩哩