高雄 何利力
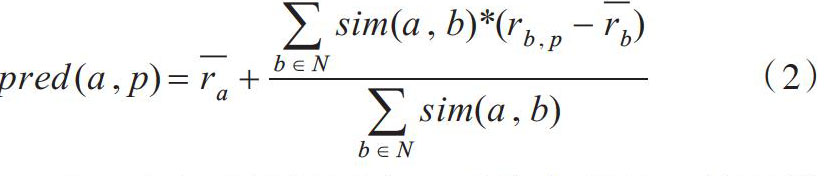


摘 要:对于有个性化推荐需求的电子商务系统,传统协同过滤推荐算法对商品的用户项目矩阵构建比较单一,难以解决数据稀疏以及推荐结果精度较低等问题。为此,提出一种改进的基于信任度的协同过滤算法,根据用户历史行为,对用户项目评分矩阵进行细分量化,综合考虑用户间关系,引入信任因子维持用户信任关系中的非对称性,通过共同评分项计算用户评分信任度。最终融合信任度与信任因子,计算获得最佳邻居集并产生最终推荐列表。在淘宝官方UserBehavior数据集下进行实验,结果表明,该算法降低了推荐稀疏性,提高了推荐精度。
关键词:协同过滤;电子商务;信任因子;信任度;商品推荐
DOI:10. 11907/rjdk. 182836 开放科学(资源服务)标识码(OSID):
中图分类号:TP312文献标识码:A 文章编号:1672-7800(2019)007-0075-05
Research on Commodity Recommendation Algorithm
Based on Improved Trust Metrics
GAO Xiong, HE Li-li
(School of Information Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China)
Abstract: For the e-commerce system with personalized recommendation requirements, traditional collaborative filtering algorithm has a simple construction of the user item matrix of the commodity, which is difficult to solve the problem of data sparseness and low accuracy of recommendation results. For this reason, an improved trust recommendation algorithm is proposed with trust metrics. According to the historical behavior of the user, the user project scoring matrix is subdivided and quantified, and then the relationship between users is comprehensively considered. The trust factor is introduced to maintain the asymmetry in the user trust relationship, the user's trust is calculated by the common score item, and finally the trust metrics and the trust factor are integrated to calculate the best neighbor set and generate the final recommendation list. Experiments were carried out under the official UserBehavior dataset of Taobao. The results show that the proposed algorithm reduces the recommended sparsity and improves the accuracy of the recommendation.
Key Words: collaborative filtering; e-commerce; trust factor; trust metrics; commodity recommendation
基金项目:浙江省科技厅(重大)项目(2015C03001)
作者简介:高雄(1994-),男,浙江理工大学信息学院硕士研究生,研究方向为计算机应用技术;何利力(1968-),男,博士,浙江理工大学信息学院教授、博士生导师,研究方向为制造业信息化、企业智能。
0 引言
随着互联网的发展,在线电子商务系统也得到了广泛应用,在为用户提供大量商品的同时,也带来了信息过载的问题,海量商品为用户选择带来极大困难。推荐系统是解决信息过载问题的主要方法之一,根据推荐机制的不同,推荐系统分为基于内容的推荐、协同过滤推荐、基于知识的推荐与混合推荐等,其中协同过滤(Collaborative-Filtering,CF)算法应用最为广泛。传统基于用户的协同过滤算法通过一系列步骤计算相似度,选择最近邻,最终生成推荐[1-2]。如黄莹[3]、贾忠涛等[4]分别将协同过滤应用于电影推荐中;归伟夏[5]研究了基于Hadoop的协同过滤在电商系统中的应用。然而,在电子商务系统中,用户和项目数量往往十分庞大,而用户购买或评价过的商品数量有限,因此造成了评分数据极其稀疏。目前常用的相似度计算方法尽管已考虑了用户评价标准的复杂性,但在数据稀疏时精度仍然较低,且在某些情况下无法反映用户真实的相似性[6-8]。对此,研究者提出了各种不同解决方案,如申凯丽[9]提出基于用户偏好的免疫推荐算法,但依然没有解决电子商务系统中商品稀疏导致的覆盖率问题;黄涛[10]利用复杂网络中的结构相似性度量用户之间的相似性;王祥德等[11]提出非精确拉格朗日乘子法对稀疏矩阵进行填充,从而改进SVD协同过滤算法;Massa P[12]将信任度引入到类似计算中,但其仍局限于用户必须自己维护与邻居的信任关系;李良等[13]提出一种基于评分信任度与偏好信任度的推薦方法,综合考虑用户间的共同评分项目与非共同评分项目;蒋宗礼[14]、刘胜宗[15]通过信任关系的传递规则,分别用不同方法融合了用户相似度和信任度;Yang和Zhu [16]提出结合用户信任与社会相似性的协同过滤算法;Lu[17]对全局信任度与局部信任度进行计算,挖掘用户的潜在信任关系,以提高推荐准确性。
目前大多数关于信任的研究中,信任关系都是事先给定的,即用户间通过关注等方式设定好信任关系。但实际的电子商务系统中并没有给定用户之间的信任网络,并且每个预测评分是基于最近邻居给出的评分进行计算的,没有考虑测试用户对最近邻居给出评分的接受性。Neal &? Stephen[18]提出一种可信赖的KNR算法,该算法允许用户通过评估其收到评分信息的效用,以了解彼此信任程度,若目标用户与最近邻关于某个项目评分越接近,则信任度越高。然而其没有考虑到用户间的信任关系是不对称的,且线性计算方法使用户间的信任关系相对平滑,影响了推荐性能。另一方面,目前的电子商务系统中对于商品评分仅局限于购买与否,若用户购买则在评分矩阵中置为1,没有则置为0。该方式很大程度上限制了对用户购买行为中潜在信息的挖掘,影响了推荐精确性。
综上所述,本文提出一种改进的基于信任度的协同过滤推荐算法。针对电子商务系统,采集用户对商品的历史行为,进行量化处理后,首先计算反映用户之间非对称关系的信任因子,其次根据用户共同评分项目改进用户间的信任度计算方式,最终融合信任因子与信任度,选取最近邻并产生推荐列表。在天猫官方数据集下进行实验,结果表明,本文算法有效缓解了数据稀疏性,提高了系统推荐的准确性,具有一定的实际意义。
1 传统协同过滤算法
在传统基于用户的协同过滤系统中,推荐过程大致可分为3步:①建立用户—项目评分矩阵;②计算目标用户与其他用户相似度,得到用户的最近邻居集;③根据其最近邻居集对项目的评分信息,预测目标用户对评分项目的评分,选取评分最高的TOP-N个项目推荐给用户。具体步骤如下:
1.1 用户—项目评分矩阵建立
用户—项目矩阵可表示为一个n*m维矩阵,如表1所示。n行表示用户数为n,m列表示项目数为m。第i行第j列元素rij表示用户i对项目j的評分为rij,其值与项目内容有关。如果是商品,通常表示订购与否,如1表示订购,0表示未订购;如果是评分类如电影等,可按等级进行划分,如1~5,评分越高表示用户对其喜爱程度越高。如果用户i未对项目j进行评分,则rij值为0。
表1 用户—项目评分矩阵
1.2 最近邻寻找
最近邻居集通常利用TOP-N方法进行选取,即通过对用户之间的相似度进行排序,选取排名最靠前的N名用户作为邻居用户。计算用户相似度的方法很多,目前广泛应用于协同过滤算法的有3种,即余弦相似度、修正余弦相似度和皮尔逊相关相似度。
本文采用皮尔逊相关相似度作为传统协同过滤的最近邻计算方式,其表达式如式(1)所示。
[sim(a,b)=p∈P(ra,p-ra)(rb,p-rb)p∈P(ra,p-ra)2p∈P(rb,p-rb)2] (1)
其中sim(a,b)表示用户a和用户b的相似性,值的区间为[-1,1]。P表示用户a、b的共同评分项目集合,ra,p、rb,p表示用户a、b对项目p的评分,[ra]、[rb]分别表示用户a、b对项目的平均评分。sim(a,b)绝对值越接近1,表示用户之间相似性越强,反之则越弱。
1.3 评分预测
在找到最近邻居集之后,通过式(2)对用户a的未评分项目p进行评分预测。
[pred(a,p)=ra+b∈Nsim(a,b)*(rb,p-rb)b∈Nsim(a,b)]? (2)
其中pred(a,p)表示目标用户a对推荐项目p的预测评分,rb,p是目标用户a最近邻居集中用户b对项目p的评分,N表示用户a最近邻居集中的用户个数。通过式(2)可以发现相似性在协同过滤算法的整个过程中至关重要,同时测试用户对最近邻居评分的接受性对于预测评分也很重要。
2 改进信任度的协同过滤算法
2.1 信任因子计算
传统信任关系认为用户之间的信任是相同的,如果用户A信任用户B,则用户B也会信任A,且两者信任程度是一样的。然而在现实生活中,通常用户A、B的信任程度是不等的,如用户A信任用户B,相反用户B并不一定信任用户A,或用户B信任用户A,但是两者信任程度并不相同。在电子商务系统中,传统方法在计算用户之间的信任相似性时,只利用了用户共同评分项目数量这一属性,如式(3)所示。
[θab=Ia?IbIa?Ib]? ? ? ? ? ? ? ? ? ? (3)
其中Ia、Ib分别表示用户a、b评分过的项目。从式(3)可以看出,对用户a、b的信任相似性仅通过两用户之间共同评分过的数量在其所有评分项目数量中的占比进行衡量,显然在该计算方法中,用户a、b的互相信任程度相同。但根据之前提到的信任程度具有非对称性特点,对上述公式进行修正,提出非对称的信任因子计算方式,以更好地衡量用户之间的信任程度,如式(4)、式(5)所示。
[θab=Ia?IbIa*Ia?IbIa?Ib]? ? ? ? ? ? ? (4)
[θba=Ia?IbIb*Ia?IbIa?Ib]? ? ? ? ? ? ? (5)
式(4)、式(5)分别计算了用户a对b的信任相似度和用户b对a的信任相似度,其中融入了用户各自评分项目总数的影响,考虑了共同评分项目在各自评分项目中的占比。
2.2 信任度计算
用户在选择信任对象时,不仅会考虑评分项目数,还会考虑具体评分数值,通常评分多少也代表了用户对项目的认可程度。为了更准确地计算用户间的信任度,需要考虑用户公共项目以及评分数值。文献[18]中对信任度的计算方式基于最近邻推荐的贡献,提出目标用户相信对其产生过积极影响的用户,并保留未知作用的用户。允许用户通过评估其收到评分信息的效用,了解彼此信任程度,并动态选择目标用户的邻居集。但其默认了用户间信任的对称关系,且出于对结果的考虑,实验设计较为简单,只关注了线性信任度的案例。为了能更好地凸显用户间的信任关系,应该从更高层次考虑,本文给出用户间的信任关系如式(6)所示。
[value(a,b,i)=(rai-rbi)22(Max-Min)]? ? ? ? ? ? (6)
式(6)中,value(a,b,i)表示用户a在项目i上对用户b的信任。其中Max为评分最大值,Min为评分最小值。若用户a、b在项目i上的评分差距较大,则表现出的信任程度相对较低,反之评分差距较小则信任程度相对较高,从而更明显地体现出b的影响。其中ra,i、rb,i分别为用户a、b对项目i的评分。因此,用户a对用户b的信任度可定义为公式(7),n代表用户a评分过的所有项目数。
[trust(a,b)=i=0nvalue(a,b,i)n]? ? ? ? ? ? ? ? (7)
2.3 改进的信任度协同过滤
在综合上述信任因子与信任度计算公式后,将改进后的信任度计算公式与信任因子融合,得到用户a对用户b的评分信任度如下:
[simt(a,b)=trust(a,b)*θab]? ? ? ? ? ? ? (8)
同理,用户b对用户a的评分信任度为:
[simt(b,a)=trust(b,a)*θba]? ? ? ? ? ? ? ?(9)
在得到最终的评分信任度后,本文采用TOP-N方法选取用户的最近邻居集,即将用户的信任度值按照降序排列,选取排名最靠前的N个用户作为目标用户的邻居集。然后根据用户邻居集,利用公式(10)计算得出最终推荐结果。其中,simt(a,b)表示计算得出的评分信任度。
[pred(a,p)=ra+b∈Nsim(a,b)*(rb,p-rb)b∈Nsim(a,b)]? ? ? ? ? (10)
本文具體推荐流程如图1所示。
图1 推荐流程
3 实验与分析
3.1 数据处理与评估标准
针对电子商务系统,在传统协同过滤算法中,对于商品类推荐都是基于用户购买与否进行评估预测的。例如对于某商品,若用户购买,则评分为1,否则为0。但该做法难以避免地增加了数据稀疏性,无法保证结果的准确性。因此,本文提出对用户购买行为进行细分量化,将用户浏览商品、收藏、加购物车以及购买分别设为评分1、2、3和4,以不同权重表示用户对商品的关注度,形成评分梯度,从而避免将购买作为唯一评判标准。
本实验采用淘宝官方的Userbehavior数据集,该数据集是淘宝用户行为数据的子集,包含了2017年11月25日~12月3日之间有行为的约100万随机用户的所有行为。数据集组织形式与MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品类目ID、行为类型等组成。为保证实验的可行性与准确性,本文从中提取25万条数据进行处理与筛选,去除用户只浏览过的商品,以避免实验数据的稀疏性,得到最终的实验数据集如表3所示。
表2 实验数据集描述
实验采用以下两种指标体系评估算法性能:
(1) 平均绝对误差(MAE)。MAE[19]通过比较预测值与用户实际评分之间的偏差以测量预测准确性,具体定义如式(11)所示。
[MAE=i=1Npi-qiN]? ? ? ? ? ? ? ? ? ? (11)
(2)均方差误差(RSME)。RSME[20]通过计算预测评分值与用户对该项目真实评分值的平方偏差以测量准确性,对推荐要求更加严格,如式(12)所示。
[RSME=1ni=1n(pi-qi)2]? ? ? ? ? ? ?(12)
在式(11)、(12)中,{p1,p2,…,pn}对应用户预测评分集合,{q1,q2,…,qn}对应用户实际评分集合,N是测试集中的项目数,用户预测值与真实评分都不为0。MAE与RSME的值越小,表示推荐精度越高。
3.2 实验设计与结果分析
为评估本文提出算法的准确性,将数据集划分为80%的训练集与20%的数据集。训练集用于训练算法中的相关参数,测试集用于评估结果准确性。
实验1:为验证购买行为量化对提高推荐精度的有效性,设计对比实验。对量化处理后的数据集应用传统协同过滤算法,命名为UCF;对未经量化处理的数据集应用传统协同过滤算法,命名为NUCF。实验结果如图2所示。
图2 量化前后MAE对比
图2为量化处理前后的MAE柱状对比图。横轴表示最近邻数量,纵轴表示MAE具体值。可以看出,相比于NUCF,UCF整体在MAE值上低很多,说明对商品数据进行量化处理后再进行推荐,结果要精确得多。这是由于只考虑购买的商品时,用户项目矩阵会显示出巨大的稀疏性,而量化后的矩阵会产生更多评分项。
实验2:将本文提出算法命名为AUTCF,为了验证AUTCF的精确性,选择3种算法进行对比实验:①传统基于用户的协同过滤算法UCF,采用皮尔逊相似度计算方法;②文献[18]中提出的基于最近邻的信任度算法TrustCF;③文献[13]中提出的评分信任度算法SUCF。实验在经量化处理后的数据集上进行,得到各种指标结果如图3所示。
图3 不同算法MAE对比
图3为MAE的对比图,横轴为最近邻数量,纵轴为平均绝对误差MAE。根据实验结果可以看出,随着N值逐渐增加,TrustCF、SUCF与本文TUTCF算法的MAE值均呈先下降后上升的趋势,且均低于传统协同过滤算法,表明信任度的引入确实有利于提高推荐精度;在N值相同的情况下,AUTCF算法相比于TrustCF、SUCF算法以及传统UCF算法,在平均绝对误差上始终更低,显示出较为明显的优势,而且在N=50时达到了最优性能,MAE值接近0.66。原因为UTCF是在量化后的数据下进行实验的,而且在信任度计算过程中,不仅考虑了用户之间非对称的信任关系,还使用户间的信任度关系更加尖锐,存在潜在信任的邻居表现得更加积极,信任度较低的邻居作用更加弱化,同时保证了用户信任值计算过程中不会因差值太小而给计算带来误差。
- 我国开征环保税的绩效研究
- 论会计人员职业继续教育对专业素质的影响
- 个人所得税模式改革研究
- 中小企业税负问题研究
- 房地产企业全面预算管理若干问题探讨
- 我国新兴行业服务贸易存在的问题及改进建议
- 无人经济商业模式的特征分析
- 杭州市与“一带一路”沿线国家物流协作优化研究
- 从中美贸易战看中国对外贸易的发展
- 浅谈大数据在社区养老服务中的运用
- 改进蚁群算法的冷链物流配送路径模型的量化分析
- 自媒体时代品牌的在线口碑传播
- 影响企业并购绩效的问题研究
- 论高管薪酬与企业内部控制
- 企业财务管理之营运资金管理研究
- 浅谈水利管理人才的开发
- 劳资管理工作中的系统工程思维与管理应用
- 拟上市民营企业若干税收问题的探讨及政策研究
- 浅析配送中心提高分拣效率的策略
- 广西JG集团绩效考核现状及评析
- 企业财务重述与外部审计师相关性研究
- 互联网+时代,“以学生为中心教学法”在高职《管理会计》课程的应用研究
- 对市场经济条件下剩余价值理论的科学认识
- 高中生消费观念对学校周边经济的影响
- 风电场劳动定员方法研究
- mediating
- mediation
- mediator
- mediators
- mediatorship
- mediatorships
- medic
- medicaid
- medical
- medical care
- medical center
- medicalcertificate
- medical cerˌtificate
- medicalinsurance
- medical inˌsurance
- medically
- medicals
- medical treatment
- medical²
- medical¹
- medicare
- medicated
- medication
- medications
- medicinal
- 停止行动而休息
- 停止议论
- 停止说话
- 停止运用
- 停止进行
- 停止雇用
- 停止飞
- 停止飞翔
- 停止饮酒
- 停止,中止
- 停步
- 停步不前
- 停步不前,好像脚被缠住了一样
- 停殡
- 停毒
- 停气
- 停水
- 停泊
- 停滞
- 停滞不前
- 停滞不动
- 停滞不动的云
- 停滞无进展
- 停滞积压
- 停滞缓慢