热木土拉·麦麦提+古丽尼尕尔·买合木提+努尔波拉提·胡安+艾斯卡尔·艾木都拉

摘要:语音合成是哈萨克文信息处理技术的一个重要研究领域。哈萨克文本中的阿拉伯数字转换为其读音文本是语音合成中重要的预备工作。该文利用规则库和N-gram,实现了文本当中的各类数字正确的转换到读音,为哈萨克语语音合成研究,提供了高质量的数字读音文本。希望通过该文提供的方法来提高哈萨克文以及相似特性的其他语种的语音合成的质量。
关键词:哈萨克语;数字读音;规则库;N-gram
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2017)14-0158-02
1概述
哈萨克语属于阿尔泰语系突厥语族的克普恰克语支,拼音文字,中国的哈萨克文借用了阿拉伯语和部分波斯文字母。哈萨克文信息处理技术在近几年来国家的支持下已取得了很多的进步,但现有成果离真正实现中国语言文字信息处理的要求还有很大的距离。语音识别是哈萨克文信息处理技术的一个重要研究领域,在当今信息社会有着广泛的应用前景。把哈萨克文本中的阿拉伯数字转换为文本(下文均简称数字转文本)是哈萨克语语音合成当中不可缺少的前期工作,其转换质量直接影响到语音合成的合成效果。虽然到目前为止在语音合成方面的研究工作取得了很多成果,但是数字转文本方面还存在很多问题,并且影响到了语音合成的质量。本文把哈萨克阿拉伯文作为主要处理对象,把哈萨克文本当中的数字转换为哈萨克阿拉伯文字形式。这为建立哈萨克文本的发音词典起了重要的辅助作用。
本文把數字按读法分为三大类:每一位单独转换,每两位一起转换和所有位数一起转换。按数字类型人工收集了包含八种基本数据类型的规则库,分别为:年、月、日、固定电话号码(不包含地区号)、固定电话号码(包含地区号)、地区号、手机号和身份证号。利用此规则库,权重累加的方式确定当前数字类型。按数字类型确定读法,并转换为文本。本文还考虑一个句子出现多种数字类型的情况,利用N-gram模型限制每种数字类型上下文匹配长度,减少数字类型判断的错误。
2哈萨克文数字读法规则
相同的数字在不同的文本中可有不同的含义和类型,因此读法也不一样。本文把数字读法类型分为三类,分别为:
第一种,是数量、等级、年、月、日之类的,读音有所有位数共同确定。比如:
3数字转换读音的方法
3.1建立数字读音库
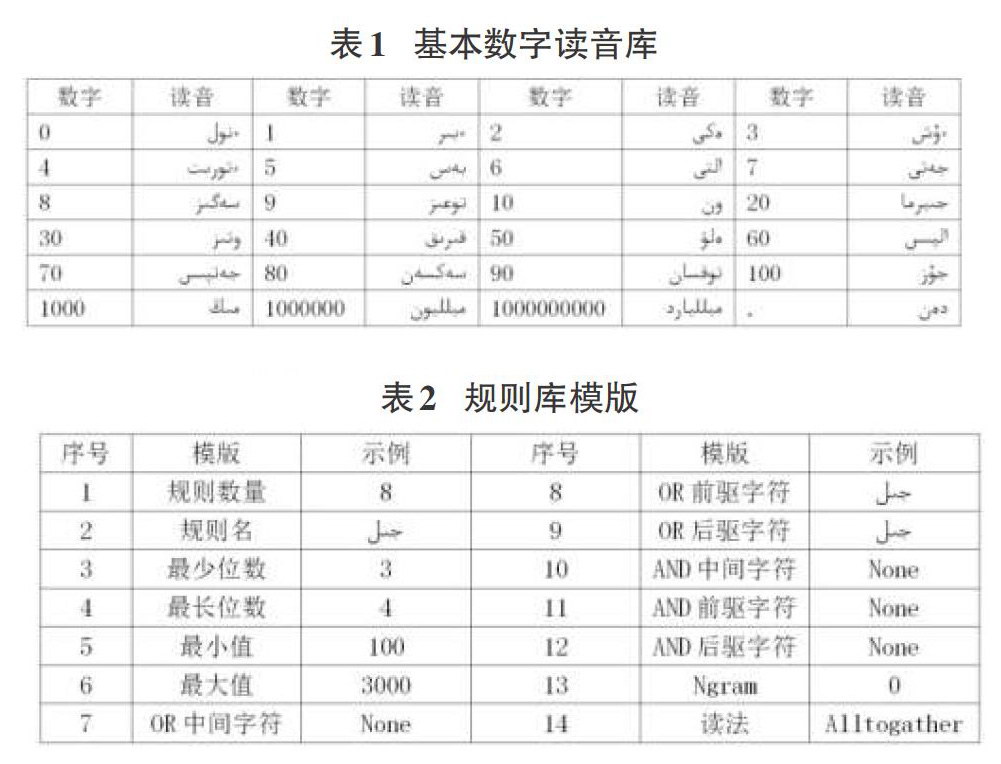
为了通过组合的方式方便快速地确定哈萨克文中的数字文本,建立了数字的哈萨克语读音库。词库包含了哈萨克语当中基本数字的读音,通过组合就能得到较为复杂数字的发音。用此数字读音库,递归的方式,进行各类数字的组合。基本数字读音库如表1所示。
3.2创建规则库
为了准确判断每一种数字的类型,按照一定的格式,以人工的方式建立的规则库。此规则库包含了数字该有的基本特性,可能有的次要特性和文本中要判断的N-gram模型的长度。下面以年这个数据类型为例,规则库的规则模版如表2所示:
表1中每一项具体含义如下:
1)规则数量:此规则库包含的N6-数字类型
2)规则名:当前规则名称
3)最少位数:当前类型数字最小的位数
4)最长位数:当前类型数字最长的位数
5)最小值:当前类型数字的最小值
6)最大值:当前类型数字的最大值
7)OR中间字符:数字之间可能包含的次要字符(多个字符用空格分开,没有时填None)
8)OR前驱字符:数字之前可能包含的次要字符(多个字符用空格分开,没有时填None)
9)OR后驱字符:数字之后可能包含的次要字符(多个字符用空格分开,没有时填None)
10)AND中间字符:数字之间可能包含的必要字符(多个字符用空格分开,没有时填None)
11)AND前驱字符:数字之前可能包含的必要字符(多个字符用空格分开,没有时填None)
12)AND后驱字符:数字之后可能包含的必要字符(多个字符用空格分开,没有时填None)
13)Ngram:判断数字类型时搜索的上下文长度(0表示全句,其他数字表示实际搜索上下文长度)
14)读法:当前类型数字的读法类型(Alhogather)
规则库中的规则数量值固定为8,代表本文涉及的8种数据类型(在规则库首部);规则名表示该规则类型名,便于建立和观察,如年。最少位数、最长位数、最小值、最大值用于判断数字类型基本性质。OR中间字符、OR前驱字符、OR后驱字符、AND中间字符、AND前驱字符和AND后驱字符用于计算数字类型的权重。每一种字符的权重赋为一,数据的权重是通过判断当前数据满足几个字符条件而累加得到。Ngram和读法用于搜索长度和确定该类型相应的读法规则。
3.3判别数字类型
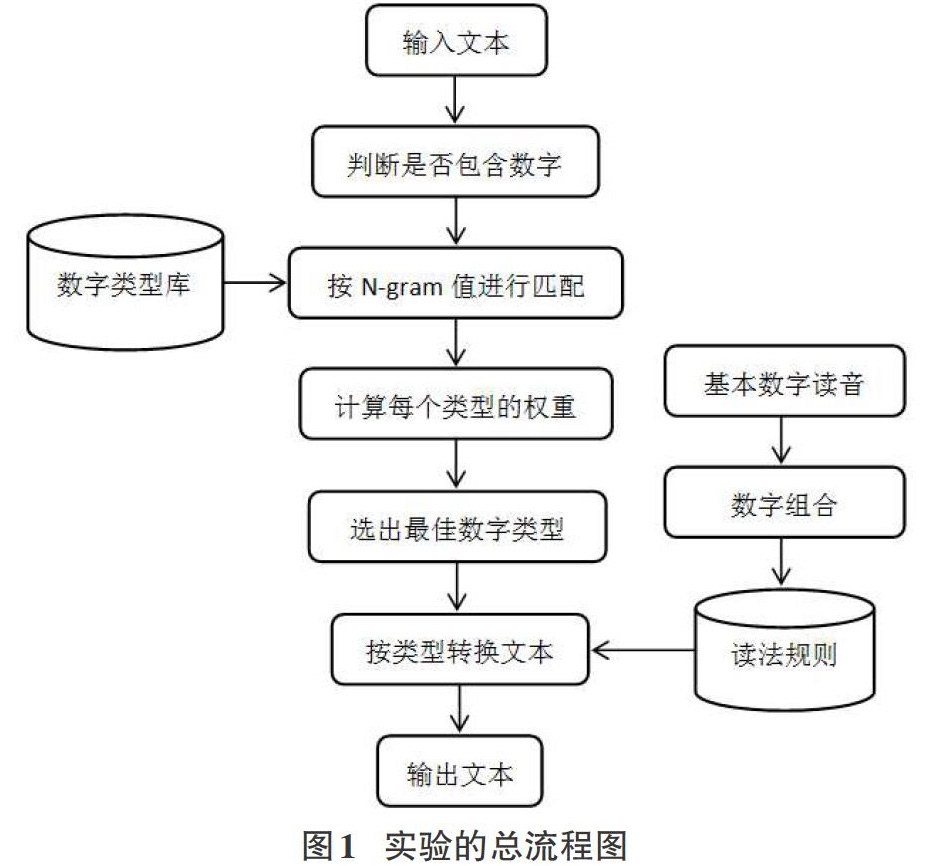
根据规则库对哈萨克文本语料中的每一句按N-gram长度进行匹配,确定当前句子符合规则库中的几条,从而得到当前判断选项相应的权重。重复以上步骤,得到所有数字类型的权重以后,选出权重最大的数字类型。按此类型的读法规则进行数字转文本并用阿拉伯数字的文本表示替换原文中的数字表示。实验的总流程图如下图1所示:
流程图所示,输入一句哈萨克语句,第一步:先判断当前句子是否包含数字,如果是,则确定句子中数字的位置,记录开始位置和结束位置。如果一个句子中有一个以上的数字,分别都记录开始和结束位置;第二步:按N-gram长度进行规则库的匹配,按规则库中条件字符是否存在,包含几条,来计算出相应的权重;第三步:按权重值的大小确定数字类型,利用数字类型和读法规则组成此数字的标准读音文本,并替换到原文本中。
4实验结果与分析
按上述流程图进行实验,用4000句哈萨克文本进行数字转文本。得到的实验结果如下表3所示:
由以上实验结果可以看出,用本文中提出的方法能够成功的把哈萨克文本中的大部分阿拉伯数字转换为其读音的文本。
5结论
语音合成是哈萨克文信息处理技术的一个重要研究领域,在当今信息社会有着广泛的应用前景。本文用规则库和N-gram,模型,把哈萨克文本中的数字转文本。此技术在哈萨克语语音合成的研究当中,为建立哈萨克文本的发音词典起到重要的辅助作用。本研究为用少量的工作量得到大部分数字读音,做出了正确的策略。与此同时本研究中的方法均可用在于阿尔泰语系的其他语言,如柯尔克孜语、乌兹别克语等。
虽然本文中的方法取得了令人满意的实验结果,但仍存在一些不足。因为数字类型除了在本文中提到的八种还有其他更为复杂的,因此需要在使用过程中继续优化和扩充规则库。
- 如何培养学生的几何直观能力
- 情境虚拟不等于忽悠
- 让数学课变得简约而不简单
- 让学生带着教材走向教师
- 在多次对比中实现数学知识的迁移
- 顺应学生思维,让数学学习真正发生
- 努力打造幸福的数学课堂
- 新人教版数学四年级上册“角的度量”教学难点破解
- 立足课堂教学,让数学活动经验深入人心
- 新型目标导控模式在“比的化简”教学中的初试
- 从“施教者”到“引导者”的转变
- “三试做、二交往、一检测”学习策略的实施
- 直观不是直接,简洁不能简单
- 以生为本 智慧引思
- 对话课堂,满足学生发言的欲望
- 以启导为动力,以自学为引擎
- 利用学生的错误创造精彩
- 建立于课前测评的教学实践研究
- 从学生的“迷糊处”入手,消除经验的负迁移
- 小学数学课堂教学生态分析
- 适时对比 问题引领
- 在解构中建构知识
- 小学数学前置性学习任务单的设计策略
- 研究教材编写意图 实现数学教育价值
- 把握数学本质 发展空间观念
- general counsel
- generalcounsel
- general creditor
- generalcreditor
- general election
- general elections
- general expenses
- generalexpenses
- general,general
- generalinsurance
- general insurance
- general insurer
- generalisation
- generalisations
- generalise
- generalises
- generalising
- generalist
- generalizabilities
- generalizability
- generalization
- generalizations
- generalize
- generalizer
- generalizers
- 欧洲第一钢琴家
- 欧洲管理学鼻祖
- 欧洲经济共同体
- 欧洲联盟
- 欧洲联盟杯
- 欧洲船都
- 欧洲花园
- 欧洲花园都市
- 欧洲诗歌的鼻祖
- 欧洲贝利
- 欧洲货币单位
- 欧洲足球之都
- 欧洲门户
- 欧洲隧道
- 欧洲音乐史上集古典派之大成者
- 欧洲音乐的总指导
- 欧洲首都
- 欧珀石之都
- 欧盟
- 欧盟共同农业政策
- 欧瞻
- 欧罗巴洲
- 欧美人忌讳“十三”
- 欧美各国
- 欧美国家的万圣节