蔡振海 张静

摘要:随着大数据和人工智能的火热,编程语言Python的热度也迅速攀升,在各大编程语言排行榜中位居榜首。越来越多的人想了解和学习Python语言。该文从Python的安装,常用库(Requests)的安装、使用,网页爬虫通用代码框架的构造来介绍Python的特点。使感兴趣者更加容易了解和使用Python。
关键词:Python;网页爬虫
中图分类号:TP393? ? ? ? 文献标识码:A
文章编号:1009-3044(2019)23-0036-02
开放科学(资源服务)标识码(OSID):
Design and Implementation of a Web Crawler System Based on Python
CAI Zhen-hai1, ZHANG Jing2
(1.Jiangsu Vocational Institute of Commerce, Nanjing 211100,China; 2. Nanjing Technical Vocational College, Nanjing 211100, China)
Abstract:With the popularity of big data and artificial intelligence, the programming language Python is also rapidly rising, ranking first in the list of major programming languages. More and more people want to know and learn Python. This paper introduces the characteristics of Python from the installation of Python, the installation and use of common libraries (Requests), and the construction of common code framework for web crawlers.Making it easier for interested people to understand and use Python.
Key words: Python; Web crawler
近年来,Python语言迅速崛起,其简洁、免费、易学习、兼容性好等特点以及其面向对象、函数式编程、过程编程、面向方面编程,受到众人的喜爱【1】。Python是一种广泛使用的脚本语言,它自身带有requests等爬虫的基础库,尤其是Python在人工智能领域的优势,使得其战略地位迅速提升【2】。教育部公布的《2019年教育信息化和网络安全工作要点》透露:今年将启动中小学生信息素养测评,并推动在中小学阶段设置人工智能相关课程,逐步推广编程教育,也将编制《中国智能教育发展方案》。了解、学习、使用Python语言是成为相关领域人才的必经之路。
1 网页爬虫的设计
网页爬虫通过一定的规则自动从众多的网络资源中爬取所需信息,它通过模仿浏览器对网页的URL地址访问的方式,不需要人工操作即可获得所需数据【3】。通过安装相关软装和库,即可实现简单的网页爬虫功能。
1.1 Python的安装
目前Python的版本已经更新到3.X,登录Python官网,根据操作系统选择相应的版本下载。本文以3.7.2版本为例在Windows操作系统上进行介绍。下载后执行Python安装可执行文件,选择安装目录,同时一定要记住在安装界面勾选Add Python 3.7.2 to PATH选项,否则在使用时会报错。
安装成功后,打开命令提示符窗口,输入Python后回车,当界面显示Python版本号,则表明Python安装成功。
1.2 requests的安装
为了爬取网页内容,需要安装requests库。以管理员身份运行命令提示符窗口,输入PiP install requests后回车,系统会执行安装requests库操作,当出现Successfully installed requests-2.21.0时,表示requests库安装成功。在使用时,需要输入import requests引入该库。
1.3 网页的爬取
安装好Python和requests库后,就可以实现简单的网页爬取功能。本文主要使用requests库中的一个非常重要的get()方法。该方法能构造一个向服务器请求资源的Request对象,并将响应对象返回,该对象是ResPonse类型。我们可以通过响应的对象所携带的数值来判断请求是否成功,若值为200,则表明请求成功,否则表示失败,当然也能通过返回的具体的数值来判断失败的原因。在使用get()方法时,需要向其传递参数,最重要的就是URL参数,即:所要爬取的网页的链接。该方法还有其他可选参数,可根据实际情况进行选择。
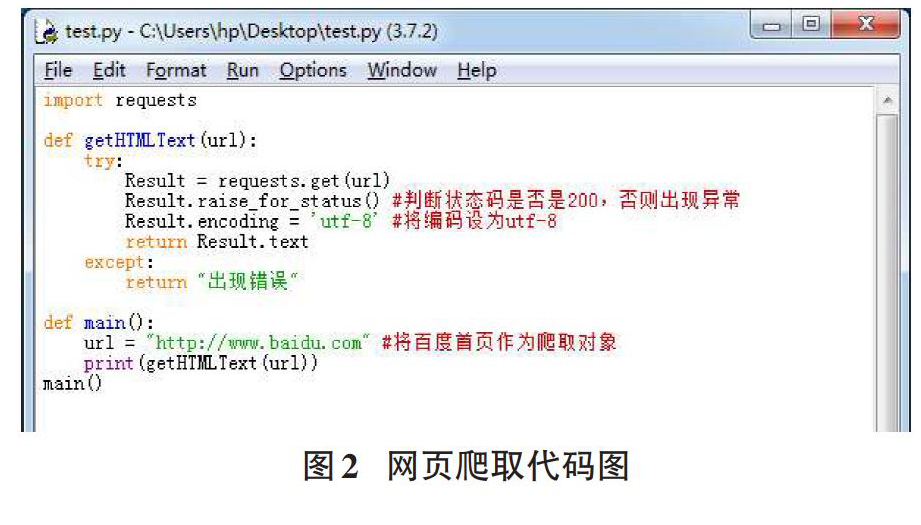
若要显示所爬取网页的信息,需要用到ResPonse的text属性,该属性是HTTP响应内容的字符串形式,即:get()方法中传入的参数URL所对应的页面。在进行网络连接时,通常会出现异常,通过raise_for_status()进行异常处理。同时为了正确显示网页内容,还需对网页编码进行修改,以免发生乱码情况。网页爬取的伪代码如下:
1 导库,将需要使用的requests库引入
2 确定需要爬取的网页URL
3 requests.get(URL)——>Result? ?//将爬取的对象返回
4 异常处理
5 utf-8——Result.encoding? ? ?//采用utf-8编码,避免出现乱码
6 打印网页内容
1.4 网页爬虫的具体实现
首先定义带参的页面爬取函数,该函数通过requests库的get()函数爬取所需页面内容,同时在该函数中做了异常处理,防止程序出现意外情况。并将编码方式设为可输出中午形式的utf-8形式。其次主函数中将结果进行打印输出。具体代码和如结果如下图所示:
2 结束语
本文通过对Python及requests库的安装和使用完成了简单网页的爬取功能的实现,通过对实际页面爬取的操作,加深了对Python的理解,提升了学习Python的兴趣。本文只是简单的实现了页面的爬取,对于Python强大的数据爬取功能将会在后期的文章中进行详细介绍。
参考文献:
[1] 仇明. 基于Python的图片爬虫的程序设计[J]. 工业技术与职业教育, 2019(3).
[2] 贾棋然. 基于Python专用型网络爬虫的设计及实现[J]. 电脑知识与技术, 2017(12).
[3] 李琳. 基于Python的网络爬虫系统的設计与实现[J]. 信息通信, 2017(9).
【通联编辑:唐一东】
- 提高农村小学科学课堂教学有效性的策略
- 探究高考数学题对高中数学教学的启示
- 论问题驱动在高中数学中的应用
- 试析“微课”视角下的翻转课堂模式在高中英语教学中的应用
- 浅析核心素养视角下初中数学高效课堂构建策略
- 七年级学生英语阅读能力的培养
- 互联网+背景下中职护理专业学校家校共育模式的创新研究
- 高中物理概念教学的实践研究
- 高职“沟通技巧顶岗实训课程化”课程建设及能力实训分析
- 游戏化教学在初中信息技术教学中的实践探索
- 提高阅读能力的有效途径
- 新时代高职院校创新创业教育融合探析
- 拨开云雾见天日
- 论小学音乐教学中如何落实素质教育
- 自主合作学习在高中语文教学中的运用
- 寻找教育的智慧之光
- 加强小学语文传统国学教学的必要性研究(1)
- 初二信息技术教学中学生自主学习能力的培养路径分析
- 农村初中语文教学中学生心理问题探
- 优化幼儿园户外教学实践活动的方法探究
- 浅谈信息技术在英语教学中的应用
- 高中数学课堂教学中的提问艺术
- 浅谈小学语文有效地教育教学策略
- 浅谈小学语文教学中的爱国主义教育
- 高中数学教学中培养数学思维能力的实践研究
- happen again
- happened
- happening
- happenings'
- happenings
- happen-on
- happen on/upon sb/sth
- happens
- happen to
- happen to do sth
- happen upon
- happier
- happiest
- happily
- happiness
- happy
- happy camper
- happycamper
- happy-go-luckiness
- happy-go-lucky
- happy go lucky
- happy hour
- happy hours
- happy-hours
- harangue
- 统言无别,析言有别
- 统计
- 统计修辞学
- 统计公报的写法
- 统计学
- 统计学之父
- 统计学家
- 统计指数
- 统计指标
- 统计方法
- 统计法
- 统计语言学
- 统计语音学
- 统计量
- 统计风格学
- 统记
- 统详子
- 统货
- 统购
- 统购统销
- 统贯
- 统辖
- 统辖军队
- 统辖天下
- 统辖己职