张红军 王豫鑫 杨万里 祁永钊 李登明
摘要:随着互联网的不断发展,应用程序、数据正在迅速增长,大规模数据存储成为大数据技术研究重点,借助数据挖掘技术能更好地为决策者提供信息支撑。容错技术是大数据处理领域中一个前沿且极具挑战性的研究课题。该文依据当前的研究现状和进展,通过对大数据时代数据特征的分析,结合当前技术发展趋势,运用Python技术设计数据挖掘中代码容错技术的改进,并用算法进行实现。测试结果表明,该算法运行良好,系统的健壮性和可靠性大大提高,为大数据和数据挖掘提供理论基础,为海量数据的安全可靠挖掘提供科学有效的技术支撑。
关键词:大数据;容错技术;算法;关键技术;健壮性
中图分类号:TP312 文献标识码:A
文章编号:1009-3044(2020)09-0016-03
1 背景
随着互联网技术的快速发展,大量文字、图形、视频、音频、Web页面等多种类型复杂的数据信息在信息检索、社交网络、物联网、车载网等诸多新兴行业广为应用,数据规模呈爆炸式增长,数据量成为信息社会增长最快的资源之一。与其同时,数据挖掘近年来也引起信息产业界的极大关注,各行各业的人们迫切需要从大量数据中提取或转换为有用的信息和知识,并将获取的知识和信息广泛应用于各类领域。
由于分布式存储系统中节点数量宠大,不断增长的海量数据需要被安全可靠存储,常常会产生各类意外故障,导致数据节点失效情况频繁,采用容错技术可以避免部分存储节点失效的情况下,数据仍然能够正常读取和下载,因此,容错技术成为大数据挖掘处理中不容忽视的重要技术。
2 数据挖掘
2.1 相关概念
大数据是指在是指在一定时间范围内无法使用传统数据库工具对其进行捕捉、管理、计算、分析和处理的数据集合。大数据具有4V特征:Volume(大容量)、Variety(多样化)、Velocity(高速性)和Value(价值性)。
数据挖掘是在大数据中通过算法搜索隐藏于其中信息的过程,通常通过在线分析处理、机器学习、专家系统、网络爬虫、数据库、可视化和模式识别等诸多技术来实现。数据挖掘是人工智能(AI)研究的热点。
基金资助:河南省科技攻关项目(项目编号:182102210208);河南省高等学校重点科研项目(项目编号:18A520013);河南省教育科学十三五规划一般课题(项目编号:2018 -JKGHYB-0407);河南省高等学校青年骨干教师培养计划(项目编号:2018GGJS196);河南省教师教育课程改革研究项目(项目编号:2019-JSJYZD-041);国家级大学生创新创业训练计划项目 (项目编号:201913504001)
作者简介:张红军(1979-),男,河南平舆县人,副教授,硕士,主要研究方向为大数据技术;王豫鑫(1998-),男,本科生;杨万里(1998-),男,本科生;祁永钊(1998-),男,本科生;李登明(1998-)男,本科生。
容错技术是在系统在运行时,异常错误被激活的状态下,系统因其算法的健壮性,依旧能正常运行而不会出现崩溃死机等意外,其基本思想是使系统内潜在的差错对可靠性的影响缩小控制到最低程度。在一些应用场景,如航空航天、交通实时监控、金融服务、医疗救援等特定行业,一次系统错误的发生会带来无法估计的损失和后果,在这些系统的关键设计中采用容错技术,从而确保运行中突发的计算机错误不会导致整个系统的崩溃。
2.2 Python技术下的数据挖掘
作为一种面向对象的解释型计算机编程语言,PYthon以其开源共享、函数式编程、语洁简洁清晰、拥有功能强大的标准库和扩展库、计算生态等诸多特点一直位居各大编程语言网站排行榜前列。
Python拥有15万个第三方扩展库,其中jieba库、Json库、Requests库、Scrapy库、numpy库使得数据挖掘变得简单快捷高效。对于数据挖掘来讲,Python对数据清洗、数据探索、建立宽表、变量筛选、建模、模型参数优化、模型输出、模型投产等等一系列环节均有成熟的“包”进行支持,而在建模环节,除了对传统时序、Logistic、决策树等算法的支持,Python对于数据的处理速度均极大的超过了MySQL数据库。在实际的挖掘项目中,在面临着需要计算几千甚至上万特征值的情况下,通过Python将可以从代码量和运算速度两方面极大提高宽表制作效率,甚至完成传统SQL数据库难以完成的工作。
2.3 Python技术下的数据预处理
在进行数据挖掘之前,首先要做的一步是对已有数据进行预处理。数据预处理指的是对数据进行初步处理,把脏数据(即影响结果准确率的数据)处理掉,否则很容易影响最终的结果。如果连初始数据都是不正确的,那么就无法保证最后的结果的正确性。只有对数据进行预处理,保证其准确性,才能保证最后结果的正确性。常见的数据预处理方法包括缺失值处理、异常值处理和数据集成。其中异常值产生的原因往往是数据在采集时发生了错误,如在采集数字66时发生了错误,误将其采集成660。在处理异常值之前,需要先发现这些异常值数据,往往可以借助画图的方法来发现这些异常值数据。在对异常值数据处理完成之后,原始数据才会趋于正確,才能保证最终结果的准确性。
3 Python在数据挖掘中异常容错处理
3.1异常处理
异常(Exception)指程序运行过程中出现的非正常现象,如数据采集错误、数据分析错误、处理的文件不存在、网络传输错误等。如果这些错误得不到正确的处理将会导致数据挖掘系统崩溃并终止运行,合理地使用异常处理结构可以使得系统更加健壮,具有更高的容错性。由于异常情况总是不可避免,因此要求数据挖掘系统除了具备基本功能之外,还应具备预见并处理可能发生各种异常的功能,使软件具有较强的容错能力。
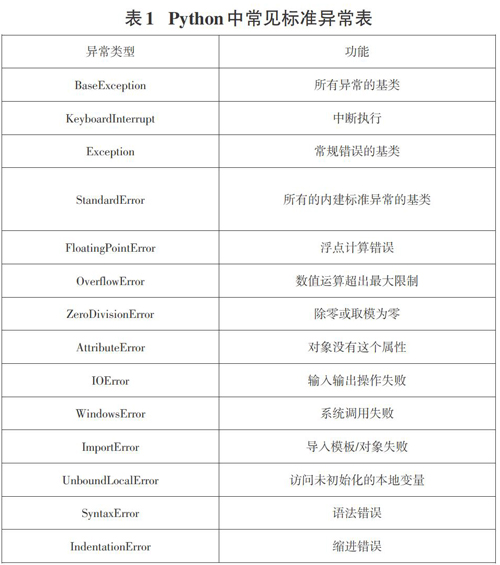
3.2 Python中常见标准异常处理
PYthon系统定义了一系列可能发生的异常类型,这些预定义的异常类型称为标准异常,当程序运行过程中发生标准异常时系统会显示相应的提示信息。常见的标准异常如表1所示。
3.3 异常捕捉与处理
Python提供多种异常处理机制的基本原理是:首先尝试运行代码,如果没有问题就正常执行,如果发生错误就采用容错机制尝试去捕捉和处理。
3.3.1使用try...except语句
这是异常处理结构中最基本的结构形式,其中try子句中的代码块包含可能会引发异常的语句,而except子句则用来捕捉相应的异常。
例如数据采集代码
Numl=eval(input(”input first number”))
Num2=eval(input(”input second number”))
当采集的数据为非数值类型,程序面临崩溃。
可改进为以下代码来实现代码容错
Try:
Numl=eval(input(”input first number”))
Num2=eval(input(”input second number”))
Except:
Print(”输入非数字,请重新输入!”)
3.3.2使用try...except...else语句
如果try中的代码出现异常并且被except语句捕捉则执行相应的异常处理代码,如果try中的代没有引导异常,则执行else块的代码。
例如数据采集代码
While True:
x=input(”input first number”)
Try:
x=int(x)
Except Exception as e:
Print(”error”1
Else:
Print(”You must input{0)”.format(x》
Break
3.3.3 使用try...excepL..finally语句
无论try中的代码是否发生异常,finallv子句中的代码总会得到执行。
例如下面代码,如果try子句的异常没有被except语句捕捉和处理,或者except子句或else子句中的代码出现异常,无论是否发生异常,finally子句中的代码总能被执行。
Def div(a,b):
Try:
Print(a/b)
Except ZeroDivisionError:
Print(”The second argument canno be 0”)
finally:
Print(”一1”1
4 Python数据分析中代码容错设计与实现
4.1 词频统计
在对网络信息进行自动检索和归档时,很多时候需要对给定的已采集的大量原始数据,统计其中多次出现的关键字,进行概要分析原始数据,或依关键字进行搜索,这种对关键字进行统计的方法叫词频分析。
4.2 jieba库的使用
jieba库是一款优秀的Pyhon第三方中文分词库,主要提供分词功能,可以辅助自定义分词词典。jieba库支持精确模式、全模式和搜索引擎模式三种分词模式。精确模式将语句最精确的切分,不存在冗余数据,适合做文本分析。全模式将语句中所有可能是词的词语都切分出来,速度快,但是存在冗余数据。搜索引擎模式在精确模式的基础上,对长词再次进行切分。
jieba是一个第三方库,需要在本地机电脑上进行安装。在联网状态下,在命令提示符下输入pip install jieba进行安装,安装完成后会提示安装成功。
4.3 算法实现
本算法以英文《Hamlet》(《哈姆雷特》)为例,统计其英文词频,算法分三个步骤:第一步,分解并提取英文文章的单词;第二步,对每个单词进行计数;第三步,对单词的统计值从高到低进行排序,输出前20个高频词语。在算法分析过程中,引入代码容错机制来避免因数据采集错误导致系统崩溃。
def get_text0:
txt= open(”hamlet.txt”,”r”,encoding= 'UTF_8,).read0
try:
txt= txt.lower()
for ch in…#$%&0++,一./=;<=>?@【\\]^-‘m~':
txt= txt.replace(ch,””)
return txt
except IOError:
print(”Error:沒有找到文件或读取文件失败”)
else:
print(”内容读取成功”)
txt.close()
file_txt= get_text0
words= file_txt.split0
counts={)
for word in words:
if len(word)==1:
conbnue
else:
counts[word]= counts.get(word,0)+l
items= list(counts.items0)
items.sort(key=lambda x: x[ll, reverse=True)
fori in range(5):
word,count= items[i]
print(”{0:<5卜>(1:>5".format(word,count)
4. 4算法测试
经测试算法运行良好,无异常,算法健壮性和可靠性大大提高。
5 结束语
大数据时代的到来,为各行各业带来了机遇与挑战。人们在从海量数据中挖掘自己有用信息的同时,数据的安全性和可靠性也逐渐成为社会关注的重点内容,计算机系统的可靠性研究对提高整个系统运行起到关键作用。本文通过围绕大数据技术、数据挖掘技术、容错技术和Python技术多方面展开讨论,结合算法代码详细分析了具体容错方法,通过算法优化分析,最终实现大大提高了计算机可靠性,从而保障计算机系统运行过程的安全性,以期为进一步研究计算机容错提供参考借鉴。
参考文献:
[1]李鑫,孙蓉,刘景伟.分布式存储系统中容错技术综述[Jl.无线电通信技术,2019,45(5): 463-475.
[2]吴庆民.大数据环境下数据容错技术研究与实现[D].北京:中国科学院大学,2016.
[3]杨娜,刘靖.面向云应用系统的容错即服务优化提供方法[Jl.软件学报,2019,30(4): 1191-1202.
[4]吴必造.基于Linux的智能家居控制终端系统的设计与实现[Dl.成都:电子科技大学,2013.
[5]孙黎,苏宇,张弛,等,分布式存储系统中的纠删码容错方法研究[J].计算机工程,2019,45(11): 74-80.
[6]刘新宇,李浪,肖斌斌.基于属性代理重加密技术与可容错机制相结合的数据检索方案[Jl.计算机科学,2018,45(7):162-166, 196.
[7]张志敏,吴军,严明玉.面向网络的快速容错恢复技术[Jl.计算机工程与设计,201 8,39(9): 2701-2706.
[8]谢建洲.计算机系统容错技术研究[Jl.电脑知识与技术,2016.12(6): 250-252.
[9]雷利香.计算机系统容错技术分析及研究[Jl.电子世界,2019(13): 177-178.
[10]陆阳,王强,张本宏,等.计算机系统容错技術研究[J].计算机工程,2010,36(13): 230-235.
【通联编辑:谢媛媛】
- 曲靖市“十四五”时期巩固拓展脱贫攻坚成果需关注的重点人群和重点问题
- 边疆少数民族地区巩固脱贫攻坚成果的有效路径
- “以人为本”统筹城乡解决相对贫困问题
- 疫情防控常态化下首都产业发展研究
- 石屏县异龙湖(高原湖泊)保护治理的实践与思考
- 坚持新发展理念引领县域发展新实践
- 树立正确政绩观,推动吉安烟草企业高质量发展
- 新形势下人民调解工作创新发展的方法和途径
- 关于发挥社区养老服务优势的思考
- 关于增强反腐倡廉教育针对性的一些思考
- 新时代企业工会工作思路
- 共青团宣传工作创新模式的探索研究
- “三转”形式下纪检机构如何有效发挥监督作用
- 税务部门征收非税收入:挑战与优化
- 实施网络强国战略,促进网络生态健康
- 史料与写作
- 新闻采访权保护探析
- 自媒体背景下衡阳高校网络舆情监控研究
- 移动新闻网络直播实践困境与对策
- 新媒体动画在虚拟展示中的应用及思考
- 加快研学旅行产品开发,带动县域文旅发展
- 夜游经济:延长文化旅游业的重要模式
- 校馆共建:博物馆与高职院校实践育人共同体
- 基于OBE理念的研究生文化自信培育机制初探
- 论女性意识在我国女性话剧中的嬗变
- scholarly
- scholars
- scholarship
- scholarships
- scholastic
- scholastically
- scholastics
- school
- schoolboy
- schoolboyhood
- schoolboyish
- schoolboyishly
- schoolboyishness
- schoolboys
- schoolboy / schoolgirl
- schoolboy/schoolgirl/schoolchild
- schoolchild
- schoolchildren
- schooldays
- schooldom
- schooled
- schoolery
- schoolest
- schoolful
- schoolgirl
- 站班
- 站的菩萨站一世,坐的菩萨坐一世
- 站着
- 站着不动
- 站着双臂交叉
- 站着射击
- 站着是一个人,睡倒还是一个人
- 站着死去
- 站着的菩萨站一世,坐着的菩萨坐一世
- 站着的跟坐着的很难说话
- 站着说话不害腰疼
- 站着说话不腰疼
- 站着说话不腰痛
- 站着说话不觉得腰痛
- 站稳
- 站稳脚跟
- 站立
- 站立、不动
- 站立不正
- 站立不稳的样子
- 站立时显得挺拔威严
- 站立时间之久
- 站立服务
- 站站儿
- 站笼