辛珂 李文竹 刘心

摘要:准确的短期用水预测是优化供水系统的基础,对城市水资源实时调度和城市供水系统调度有着重要意义。为了克服传统的神经网络预测模型训练时间长、易于陷入局部最优的预测结果,且在少量数据样本情况下预测精确度不足的缺点,本文提出了一种基于遗传算法一极限学习机的城市短期用水预测方法。在引入相关影响因素的基础上,用擅长全局搜索和并行搜索的遗传算法对极限学习机参数进行寻优。结果表明,本模型的预测精度较高,日均绝对百分比误差仅为2.19%,具有较强的实用价值,为未来水资源实时调度提供理论依据。
关键词:遗传算法;极限学习机;短期用水量;预测模型
中图分類号:TV213 文献标识码:A
文章编号:1009-3044(2020)13-0217-04
1引言
水利是国民经济和社会发展所必需的基本要素,为社会的发展、粮食和生态环境安全提供重要保障。随着人口不断向大中型城市迁移,各城市对于水资源的需求量也大幅度增加。城市供水系统的自动化运营是未来的一种发展趋势,而用水量预测在整体城市供水系统的设计、规划、管理和运行中起着重要的作用,是供水策略、运行调度、优化设计的关键性参考。因此,国内外有大量的研究试图准确可靠的预测城市用水量,并提出了多种预测方法,如:回归模型、人工神经网络与差分整合移动平均回归结合模型、时间序列、BP神经网络模型等。早期Braun根据柏林某个居民区的历史用水数据,提出了结合自回归方法和考虑附加参数的回归模型和基于季节自回归综合移动平均(SARIMA)模型的建模方法;杨晓俊利用时间序列分析中的移动平均模型和指数平滑模型;对柳林泉的还原泉流量进行了较为准确的预测;牟天蔚嘲提出一种基于深度学习框架的小波深度信念网络fsw—DBN)时间序列模型,对新开河日供水量进行较为精确的预测;鞠佳伟选择了影响因素明确、计算简单、可随时修正参数的多元线性回归预测方法,建立了预测结果相对误差较低的日供水量预测模型;郭强用贝叶斯准则优化了传统BP神经网络预测模型,避免了传统BP神经网络再预测时易陷入局部极小化和收敛速度慢的问题。
随着智能算法理论的发展,神经网络理论在水量预测领域得到了创新发展和应用,但传统的智能算法如BP神经网络存在着极易得出局部最优解以及收敛速度较慢的不足;人工神经网络(ANN)神经网络鲁棒性不高,预测模型缺乏长效性和扩展能力等。基于此,提出通过遗传算法(GA)优化极限学习机(ELM)的短期用水量预测模型(GA-ELM预测模型)。该方法通过GA对ELM模型的初始连接权值和隐含层神经元阈值进行优化,与其他传统的智能算法相比,具有更快的学习速度,更好的泛化性能,并且ELM模型自身也有较强的鲁棒性。最后通过北京市城区自来水水厂数据进行算例仿真并与传统BP神经网络预测模型及传统ELM模型进行比较,验证所提出的短期用水量预测结果的准确性。
2城市日用水量主要影响因素分析
2.1城市日用水量的影响因素
城市用水量通常包括生活用水、公共用水以及工业用水。而对于城市日用水量与时间、温度、气温、节假日等影响因素密切相关,具有复杂性、非线性、时变性的特点,主要表现为:
(1)气温变化会导致城市内居民用水量变化。在温度较高条件下,居民生活方式可能会发生改变,例如饮用水量以及清洗用水量会提升,导致生活用水量可能会呈上升趋势。
(2)天气的变化会影响居民的生活方式及生活行为,导致用水量发生相应的改变,同样也会对城市绿化用水、道路洒水和水库蓄水产生影响。
(3)节假日因素,在节假日居民在室内活动的时间会比在工作日时间长,因而居民生活用水会有增幅,同时企业用水可能会下降。若无法定假日,可将每周内的用水量视为周期性变化。
综上,城市日用水量应存在以每日为单位的短期周期性变化以及以年为单位的长期周期性变化。因此,本文着重研究气温、天气及节假日与城市日用水量之间的关系。
2.2主要影响因素筛选
3基于GA-ELM的短期用水量预测模型
极限学习机神经网络具有预测精度高、训练速度快的特点,但由于极限学习机模型中网络结构的输入层神经元与隐含层神经元之间的连接权值和隐含层神经元阈值是随机赋值的,这会导致当给定连接权值定值为0时隐含层节点失效。而隐含层神经元的节点数量过低会降低预测结果的预测精度,过多则会出现过拟合现象。基于此本文选用寻优效果显著的遗传算法对极限学习机神经网络的权值和阈值进行最优筛选,得出GA-ELM预测模型。
3.1 ELM神经网络原理
3.2 GA改进ELM算法步骤
由3.1中叙述的模型可知,ELM算法模型的初始输入层与隐含层的连接权值和阈值是随机产生的,这就会造成某些时候ELM算法输出矩阵H不是满列秩,使得模型中某些隐含层节点无效,这样就可能会降低ELM预测算法模型的有效性和准确性。针对这一问题,在计算输出权重之前,对输入权重和阈值进行基于遗传算法的筛选,遗传算法(GA)是一种模拟生物种群遗传变异进化过程的一种自适应搜索技术,根据适者生存、优胜劣汰的自然法则,将所需求解的问题转为生物种群进化的过程,过程中根据概率论方法可以自适应的改变搜索方向,以较快的速度找出最优解。通过GA对ELM进行优化,理论上可以保证输出矩阵H的列满秩,并且可以在一定程度上提高学习速度、预测精度、测试精度和整体网络结构的鲁棒性。
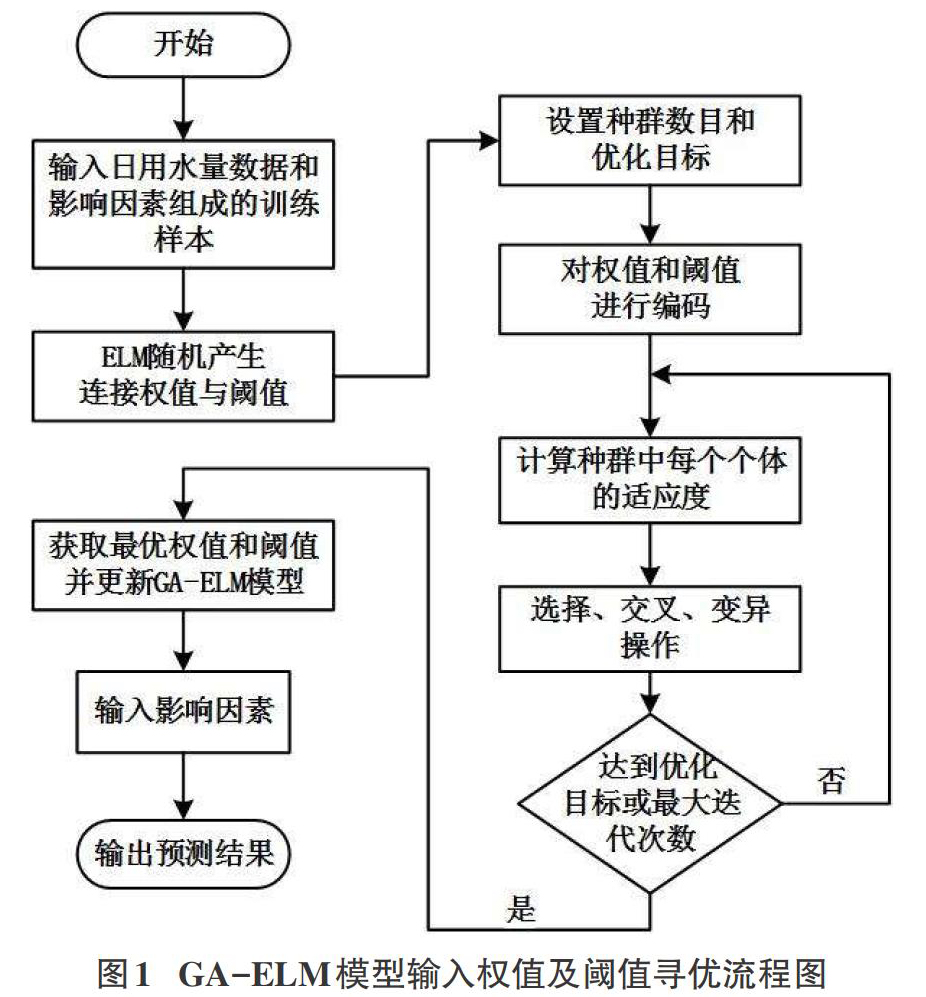
对ELM模型的权值及阈值参数寻优流程图如图1所示。
具体实现主要步骤如下:
步骤一:将日用水量数据和影响因素作为训练样本输入。
步骤二:根据输入的训练数据建立随机产生连接权值与阈值的ELM神经网络。
步骤三:设置遗传算法的种群数目和优化目标。优选地,选取误差作为适应度函数,优化目标为达到目标误差。
步骤四:对ELM模型的输入层与隐含层的连接权值和隐含层阈值进行二进制编码。
步骤五:对种群进行训练,并计算种群中每个个体的适应度值。
步骤六:根据适应度值,对种群进行选择、交叉、变异,从而产生子种群,GA的初始参数:种群大小s为60;交叉概率Pc=0.9;突变率Pm=0.01;GA的迭代次数为120;目标误差(均方误差/VISE)为1×10-4。将子种群的个体插入父种群,替代父种群中适应度值最小的个体,得到新种群,同時迭代次数加1。
步骤七:判断是否满足结束条件。是则进行步骤八,否则返回至步骤五。结束条件设置为达到优化目标或达到最大迭代次数。
步骤八:对参数进行解码,根据得到的最优输入层与隐含层的连接权值和隐含层节点阈值更新GA-ELM模型。
步骤九:将影响因素输入到预测模型,得出预测结果。
4仿真实验
4.1样本数据
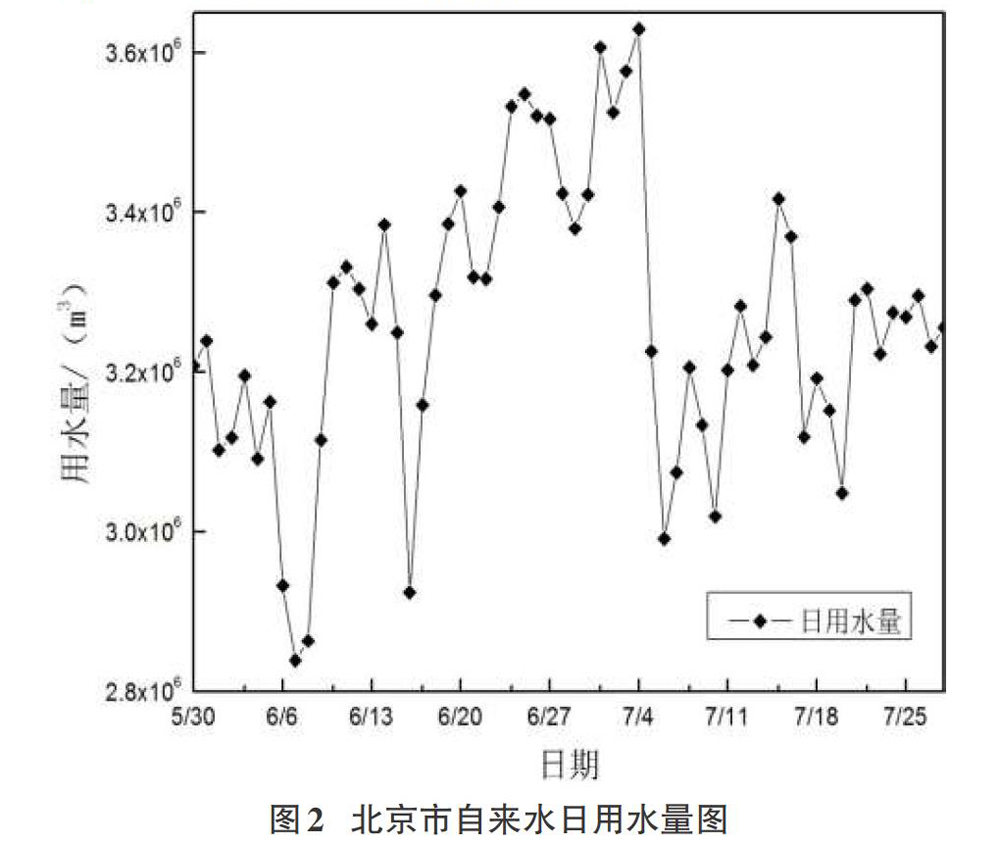
本文仿真数据为北京自来水集团市区水厂2019年日供水量数据,每日为一个样本点,按照季节类型应该春季、夏季、秋季和冬季4种类型,仅以2019年5月30至7月28日用水量量作为样本数据,共60天,如图2所示,以此数据为基础建立GA-ELM预测模型并将当日最高气温和最低气温作为模型影响因素输入以提高预测模型的预测精度。
本文以夏季模型为例,共计60d的样本数据。本文仿真实验是基于北京自来水集团市区水厂历史用水数据进行的,因此在选择合适的输入日用水量数据时十分谨慎,尽量使用涵盖所有情况的数据。本次选择的60d样本数据没有丢失数据和异常数据,其次,因北京市日用水量数据过于庞大而影响因素数据相对较小,在仿真实验中要进行数据和影响因素的归一化处理。
4.2参数设置
由于ELM网络拓扑结构关键在于隐含层节点数目的确定,本文初选数目6、10、12、14、15等多种方案进行实验比较,分析个方案下模拟结果与期望目标之间的均方误差、绝平均对误差及平均绝对百分误差等指标,选取性能较好的方案,确定ELM隐含层神经元个数为12,结合输入输出因子数量,故网络拓扑结构确定为2-12-1。
4.3对比模型及评价标准
为了评估本文所提出的北京市短期用水预测的模型预测结果的准确度,决定采用三种被普遍认可的评价标准,分别为可以更好地反映预测误差的实际情况的平均绝对误差(MAE)、直观统计误差的值的平均绝对百分误差(MAPE)以及常用来作为机器学习模型预测结果衡量标准的标准误差(RMSE)。MAE可表明预测值误差的实际情况,MAPE可用来表示分析测试结果的精密度,RMSE则能反映一个数据集的离散程度和稳定性。
4.4结果与分析
GA-ELM预测模型与传统BP神经网络预测模型、传统ELM预测模型输出结果与性能分析结果如表2所示,输出结果的每日绝对百分误差结果图如图3所示。
从表2中可以看出,GA-ELM预测值平均误差(MAE)相较于其他两种预测模型最低,在庞大的百万立方用水量数据下,平均误差在71758.878立方米已经是很可观的数字。由平均绝对百分误差可以看出,在模型预测精度上也是GA-ELM精度最高,达到2.19%,传统的ELM预测模型相对于传统BP神经网络预测模型优势则并不明显。由均方根误差(RMSE)可以看出,GA-ELM预测模型的损失量相对于其他两种模型最小。为了进一步说明GA-ELM模型的预测精度,图3给出三种模型的每日绝对百分比误差对比图。
从图3中可以直观地看出,BP神经网络预测模型最大绝对百分比误差在7月23日为6.52%,ELM神经网络预测模型最大绝对百分比误差在7月26日,达到了6.36%,甚至高于同一天的BP神经网络预测模型,而在7月28日,BP、ELM神经网络预测模型的绝对百分比误差达到最小,分别为2.23%和1.4%,但仍然高于GA-ELM预测模型的0.32%,整体上看,GA-ELM模型每日的绝对百分比误差都要远小于另外两种对比预测模型。综上,GA-ELM短期用水预测模型的每日预测结果稳定性、预测精度远高于其他两种模型。
5结语
城市日用水量具有较明显的不确定性和随机性,传统的神经网络预测方法的预测精度未能达到相对精确的预测结果,本文提出了一种基于遗传算法一极限学习机的短期城市用水量预测模型,利用极限学习机算法训练速度快,泛化性能强,无须调整参数的优点,并结合遗传算法优化其输人权值和隐含层神经元阈值的改进方法,改善了该预测模型的训练过拟合或隐含层缺失的隐患,进而提高了模型的预测稳定性和预测精度。将该预测模型的预测结果与其他两种预测模型的结果进行对比,结果表明GA-ELM预测模型的预测精度较高,具有较强的实用价值,从而为未来水资源调度和需水预测提供新思路。
- 有机蔬菜种植技术及病虫害防治措施
- 晚熟柑橘种植技术要点
- 基于市场经济条件下营林生产问题分析与对策
- 中华虎凤蝶在白石砬子国家级自然保护区生长周期调查研究
- 苹果褐斑病发病特点及综合防控技术
- 探析影响造林成活率的主要因素
- 名优乌龙茶制作工艺及品质要求
- 设施葡萄根系与叶片管理关键技术
- 水稻种植及病虫害防治技术
- 推广种植节水小麦 助力农业绿色发展
- 减肥技术在农作物栽培的科学应用
- 水稻病虫害绿色防控技术
- 2019年铁岭县基层农技推广补助项目玉米培训基地示范总结
- 秸秆栽培食用菌资源循环利用关键技术推广
- 优质玉米栽培技术与病虫害防治研究
- 玉米种植技术推广的意义及途径
- 甘薯优质苗繁育技术
- 防止耕地“非粮化”稳定粮食生产
- 水库大坝工程防渗施工技术要点
- 新时代党建引领乡村振兴的实践逻辑研究
- 绿色植保技术在农业生产中的实践探究
- 小型灌区农田水利渠道现浇矩型断面施工分析
- 生态农业气象服务的需求与对策
- 生态农业发展下的农业环保技术应用研究
- 关于重金属引起的土壤污染问题与治理策略分析
- distinctiveness
- distinctivenesses
- distinctly
- distinctly remember
- distinctness
- distinctnesses
- distinguish
- distinguishabilities
- distinguishable
- distinguishablenesses
- distinguishably
- distinguish-between
- distinguish-by
- distinguished
- distinguishedly
- distinguisher
- distinguishers
- distinguishes
- distinguish-from
- distinguishing
- distinguishing feature/mark/characteristic
- distinguishment
- distinguishments
- distinguish yourself
- distort
- 冒充打猎人
- 冒充斯文
- 冒充有功劳
- 冒充有能力而受禄
- 冒充欺骗
- 冒充鹰凶
- 冒冒
- 冒冒失失
- 冒冒失失的样子
- 冒冷汗
- 冒凉腔
- 冒出
- 冒出来的清泉——几把土堵不死
- 冒刃
- 冒刃卫姑
- 冒制
- 冒功
- 冒功受赏
- 冒功邀赏
- 冒势
- 冒取
- 冒号
- 冒名
- 冒名接脚
- 冒名来领取