刘守唯 孙力群

摘要:校园消费行为每天产生大量交易数据,这些原始数据蕴含隐藏着在学生生活管理、后勤服务和保障、关联活动预警、商户类型布局预测、商户活动评估和过程考核中的管理价值。大数据技术为我们提供了在丰富有效的手段去挖掘这些原始数据宝藏,开展充分有效的数据分析和利用。该项目是由该校大数据竞赛团队设计开发的校园消费行为大数据分析系统,对接该校智慧校园建设项目,通过hadoop,hive,scikit-learn、flask、echarts等大数据分析、开发和可视化技术开发大数据分析系统。该文阐述了采用的技术平台和项目架构,并重点介绍了数据分析阶段的设计思路和理念。
关键词:校园消费;大数据;数据分析;机器学习;hive;hadoop
中图分类号:TP311 ? ? ?文献标识码:A
文章编号:1009-3044(2020)31-0051-02
1背景
传统校园卡系统具有身份识别和电子钱包等功能,实现了校内统一身份认证和消费统一管理,校园卡使用数据完全记录了使用者在校内的消费情况和行为轨迹,通过对校园卡数据的挖掘分析[1],对高校数据决策具有十分重要的意义。随着支付宝、微信等第三方支付的推广应用,已逐渐占据校园消费主导地位。学生在校园的各类学习和生活消费行为,只要是经过业务系统的,都完整记录了消费明细数据。当前的高校信息化建设已经进入了一个以“智慧校园”建设为主题的新时期[2]。这些数据价值的挖掘与分析,往往只做了简单的统计报告。数据内在的、隐性的价值、各类数据之间的关系分析没有揭示出来,每天生成的海量数据没有进行高度价值化的挖掘分析,数据反映的问题只能靠管理人员的经验和直觉才能发现,并且已有较大的滞后性。我们开发目标就是针对这些痛点和难点,采用通用化的产品级平台+配置式定制开发+增值式数据服务的开发模式。我校使用的第三方支付为禧宝公司使用的支付宝系统。通过开发模拟客户端程序,定时采集每天发生的业务数据,增量保存至HDFS文件系统中,供进一步清洗、分析。
校园消费行为大数据分析系统产品技术架构采用分层模块化的大数据生态圈组件。基础计算平台采用高可用性Apache Hadoop。结构层次如图1所示。校园大数据分析平台采用多层架构, 将大数据处理、数据交换与共享、基于关系型和统计型大数据存储、权限管理、大数据分析挖掘进行有效整合, 贯通校园大数据管理和应用的各个环节, 从而适应于多维异构环境下校园大数据处理要求, 实现海量数据的高效管理[2]。
2通用分析功能设计
2.1 数据及其分析结构
数据采集程序通过Python采集和清洗后的数据需要导入到hive表进行分析处理,在基础统计部分,我们主要使用hql语言进行分析,根据不同分型类型,编写分析脚本,当一定周期的数据收集清洗完毕,会触发调用脚本执行分析任务。
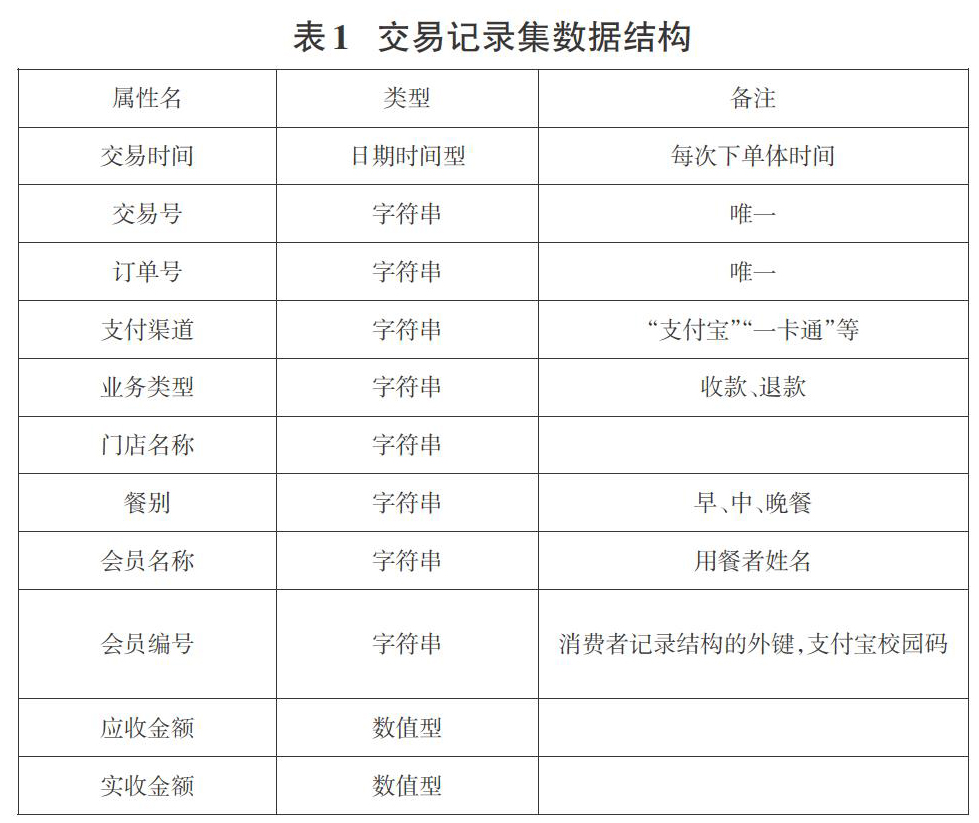
實现流程:将采集、清洗后的数据利用Sqoop将数据导入Hive(Hdfs),编写HQL语句对数据进行分析运算,利用Sqoop将最终数据从Hive(Hdfs)中导入Mysql中。表1为待分析数据集的数据结构
业务流水数据可利用会员编号关联从学校业务系统导入的学生信息记录,主要包括学号、姓名、性别、籍贯、专业、届别、班级。用于进行学籍数据相关的消费特征分析。以下说明这几个分析条件要素。
分析类型。如销售额,周平均销售额,日平均销售额,每单平均销售额。价格区段、单数、日平均单数等。
商户范围。分析统计时选择涉及的商户范围,选定商户范围内的消费记录作为分析基础。范围粒度为食堂、门店和窗口三级,覆盖了各管理层级的关切数据域。
时间范围。时间范围的选择从年、学期、月、教学周到自定义起始日期,覆盖了各类逻辑时段区间。为用户提供方便的同时,也为分析算法的灵活和响应性设计提出了挑战。
分析单元。用餐时段,分早、中、晚3个时段。时间单位,分每年,每学期,每月,每周,每天。商户单位,分按每个食堂,按每个商户,按每个窗口。以上均包括“不限”含义。通过综合分析,我们发现大量分析统计需求的语义是基于分析单元,可为餐段、时间单位、商户单元,例如:分析2020学年第一学期(时间范围)第一食堂(商户范围)每天(时间单元)中餐(餐段单元)每个门店(商户单元)的平均销售额(分析类型)。通过以上选项组合,可以覆盖常用的分析单元。
2.2分析过程示例
2.2.1利用hive导入数据
1)创建表
Create table all_table(code string, jye string, time string, winname string,type string)row format delimited fields terminated by ‘,
2)导入数据
Load data inpath ‘/output/data/part-r-00000 into table all_table;
2.2.2编写HQL数据分析脚本
HQL脚本主体就是SQL风格的语句,完成指定分析任务,本文以计算某一时间段每人平均销售额为例。(交易时间字段格式:2020-12-1 18:56)
取出类型为消费的数据,并将食堂窗口尾号去掉
insert overwrite table xf
select code ,abs(jye),time,regexp_replace(winname,'[0-9]+','') from all_table where type ='消费';
计算这一时间段每人的销售额
select count(distinct code) from xf
where
split( split(time,' ')[0],'-')[0]>=起始年 and split( split(time,' ')[0],'-')[0]<=截止年
split( split(time,' ')[0],'-')[1]>=起始月 and split( split(time,' ')[0],'-')[1]<=截止月
split( split(time,' ')[0],'-')[2]>=起始日 and split( split(time,' ')[0],'-')[2]<=截止日;
计算每单平均销售额
Select sum(money)/count(*) from xf;
计算日平均单数
Select count(*)/count(distinct split( split(time,' ')[0],'-')[2]) from xf;
2.2.3利用Sqoop將分析后数据导出到Mysql
bin/sqoop export \
--connect jdbc:mysql://localhost:3306/test --username root ?--password 123456 \
--table result --num-mappers 1 --export-dir /user/hive/warehouse/demo.db/staff/ \
--input-fields-terminated-by '\t' //hive文件分隔符
3机器学习分析可视化应用
机器学习,一言以蔽之就是人类定义一定的计算机算法,让计算机根据输入的样本和一些人类的干预来总结和归纳其特征和特点,并用这些特征和特点和一定的学习目标形成映射关系,进而自动化地做出相应反应的过程[3]。这个反应可能是做出相应的标记或判断,也可能是输出一段内容——图片、程序代码、文本、声音,而机器自己学到的内容我们可以描述为一个函数、一段程序、一组策略等相对复杂的关系描述。
本系统采用机器学习算法,根据历史数据,选择适用模型预测商户的未来销售业绩、学生的消费喜好等分析需求。机器学习库使用scikit-learn,开发业务预测模块,嵌入flask的数据可视化网站,将预测结果以echarts图表方式呈现[4]。例如在基于历史数据的销售预测中,可使用线性回归算法构建预测模块。以下为核心代码段。
3.1在flask项目中定义机器学习线性回归预测模块[5]consumePredction.py
def predConsume(month, consume):
consumePred_X = np.array(month).reshape(len(month),1)
consumeRred_Y = np.array(consume)
regr = linear_model.LinearRegression()
regr.fit(consumePred_X, consumeRred_Y)
consumePred_x_pred = np.array([49,50,51,52,53]).reshape(5,1)
consumePred_y_pred = regr.predict(consumePred_x_pred)
return consumePred_y_pred
3.2 flask项目中使用SQLAlchemy定义数据对象映射[6],记录各月的销量
class MonthConsume(db.Model):
__tablename__ = "Months"
id = db.Column(db.Integer, primary_key=True)
month = db.Column(db.String(3))
value = db.Column(db.Integer)
3.3各层组件协作,使用ORM对象提取训练集,调用线性回归模型完成销量预测,将预测数据json化处理后推送给客户端可高视化应用
@app.route('/findAll')
def findAll():
MonthConsumes = MonthConsume.query.all()
Months = [rec.month for rec in MonthConsumes ]
MonthNumber = [rec.value for rec in MonthConsumes]
cosumePreNum = MonthPredction.predConsume(Months,MonthNumber)
return jsonify({"Month":[1,2,3,4,5],"MonthNumber":cosumePreNum.tolist()})
4系统研发小结
校园消费大数据系统的分析开发我们较多得使用了hive分析工具,能应对大部分的大数据查询分析。同时在需要使用机器学习模型进行预测和分类的场景下,我们结合scikit-learn,把机器学习任务封装成flask后台的计算模块。将计算结果以网站图表的方式友好呈现给用户。由于客户查询分析的随机性,如果每次查询分析都从第三主支付平台接口提取原始业务记录,或即使保存至本地,时间开销都会很大。因此,下一阶段,将研究按时间、空间分层的方式缓存基本分析单元。使系统对客户响应更加友好。
参考文献:
[1] 范媛,蔡敏.大数据背景下学生消费水平分析模型的建立[J].电脑知识与技术,2020,16(8):5-7,20.
[2] 王亚楠.大数据背景下数据挖掘技术在高校中的应用——以校园卡系统为例[J].华中师范大学学报(自然科学版),2017,51(S1):9-12.
[3]DatapiTHU.轻松看懂机器学习![EB/OL].(2018-08-20)[2020-08-08].https://blog.csdn.net/eNohtZvQiJxo00aTz3y8/article/details/81880441.
[4] 宋文文,孙力群.大数据可视化数据加载模式比较分析[J].电脑知识与技术,2019,15(36):11-12.
[5] Jaques Grobler.Linear Regression Example.[EB/OL].[2020-08-08].https://scikit-learn.org/stable/auto_examples/linear_model/plot_ols.html.
[6] Michael Bayer.sqlalchemy官方教程[EB/OL].[2020-08-08].https://www.sqlalchemy.org/library.html#tutorials.
【通联编辑:谢媛媛】
- 由“M收购库卡”看中国机器人发展
- 外商直接投资对服务业工资差距影响
- 家装企业进入新零售行业的策略分析
- 工资集体协商中常见问题分析及解决方法探讨
- 旅行社发展个性化定制旅游影响因素与提升策略
- 供应链金融内涵与风险管理研究进展分析
- 全渠道零售模式下消费者行为及管理策略
- 基于shapley模型的农产品供应链利益分配
- 餐饮业网络营销模式创新研究
- 提高电力企业思想政治工作效果的新思路分析
- 以哈尔滨为例分析宠物寄养的问题与出路
- 城市发展史的视角下中小城市的发展因素分析
- 新收入准则对企业的影响研究
- 新时代国有企业人才培养模式探讨
- 上市公司股权激励实施效果研究
- 浅谈企业信用在企业市场营销中的重要性
- 供给侧结构性改革下的红河州工业发展探究
- 人口结构变化和我国保险业发展分析
- 金华数字娱乐产业招商策略研究
- 新媒体环境下民办高校学生就业信息网络建设研究
- 1+x证书制度下高职会计专业人才培养模式改革研究
- 我国历史文化名镇旅游开发模式可持续性研究
- 华为父亲节广告短片《长大吧!老爸》多模态话语意义建构分析
- 威宁县农户生产行为选择研究
- 关于兴城市旅游资源现状的调查
- dissimilar
- dissimilarities
- dissimilarity
- dissimilarity's
- dissimilarly
- dissimulation's
- dissimulator's
- dissipate
- dissipater, dissipator
- dissipaters
- dissipates
- dissipating
- dissipativities
- dissipativity
- dissipators
- dissociate
- dissociated
- dissociates
- dissociating
- dissociation
- dissociative
- dissolution
- dissolution's
- dissolvabilities
- dissolvability
- jǐng
- jǐnɡ
- jǔ
- j 人
- j.博士
- (:-|k-
- :-|k-
- k
- k:-)
- ka
- kai
- kan
- kang
- kao
- ke
- kei
- ken
- keng
- kenɡ
- key
- key pals
- kgb
- kgb
- kick
- kill