栗征征


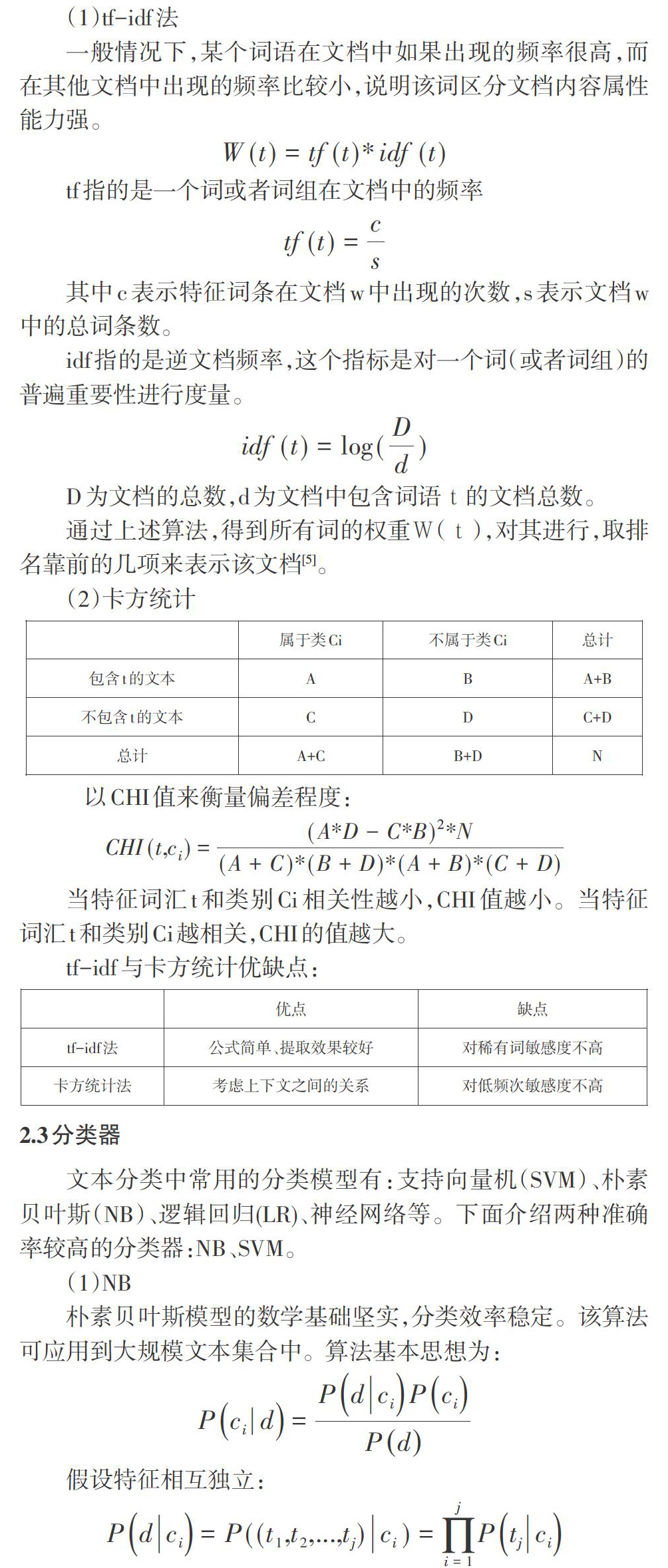
摘要:在大数据时代,随着网络上的文本数据日益增长,文本分类技术显得越来越重要,是文本挖掘领域的热点问题,具有广阔的应用场景。文本分类方法的研究开始于20世纪50年代,一直受到人们的广泛关注。该文从文本分类的流程出发,简要介绍文本分类的一般流程以及每一步骤中涉及的主要技术。主要包括预处理部分的分词、去停词和文本表示方法、特征降维和分类算法,分析了各种方法的优缺点并总结。
关键词:文本分类;预处理;特征降维;分类算法
中图分类号:TP3? ? ? ? 文献标识码:A
文章编号:1009-3044(2021)01-0229-02
1文本分类简介
概念:文本分类是自然语言处理中的重要学科,其目的是在已知的分类中,根据给定文本内容自动确定其所属文本类别的过程。
文本分类可分两个阶段:训练与测试,每个阶段又涉及预处理、特征降维、训练分类器三个步骤。预处理包括分词、去停词、文本表示等;特征降维主要用到的方法有词频-逆文档频率(tf-idf)、卡方统计等;目前主流的分类器包括:支持向量机(SVM)、朴素贝叶斯(NB)、K近邻等[1]。如图1所示。
预处理:将文本数据转换为计算机可处理形式。
特征选择:由于文本内容复杂,难以用简单的方法表示,一般情况下文本的特征会达到很高的维度,特征选择可以降低维度从而使运算速度和准确率得到提高。
分类器:对分类器进行训练。
2关键技术
2.1 预处理
预处理主要包括两大部分:分词、去停用词和文本表示。
(1)分词、去停用词
分词。中文文本与英文文本的分词区别在于英文可以根据空格来将词语分开,中文则需要用一定算法来讲文本分为词序列。分词是自然语言处理的中的第一步,对中文来说更为重要。在目前的文本分类研究中,大多使用成熟的分词系统如jieba分词,來进行分词的工作,可以取得较好的效果。
去停用词。在文本中会使用无实意的虚词、代词、名词等,这些词的出现频率高,而且对文本的分析无太大影响,更会加重运算负担,因此需要将此类词语去除[2]。
(2)文本表示
文本表示:将文本转化为计算机能够识别的数据的过程称之为文本表示。
文本表示模型主要有:
布尔模型:用0或1来代表特征词的权重。当某词语在文档中出现过时,该词的权重值为1。
向量空间模型:向量空间模型利用特征向量表示文本,文本集合中的词条作为表示文本的特征项。
向量空间模型又分为独热表示与分布式表示。独热表示或称浅层表示,是最简单的向量空间模型,独热表示用一个维度为词典大小的向量来表示所有词。词语m的向量表示为:m在词典中的索引位置为1,其他位置为0[3]。
独热表示简单易懂,因此其缺点也比较明显,一是:向量的维度为字典大小,容易造成维数灾难;二是:任意两个词之间都是孤立的,无法表示上下文关系。
分布式表示目前比较热门的为基于神经网络的分布式表示,即词嵌入(word embedding)。
传统的独热表示仅仅将词符号化,不包含任何语义信息。词嵌入表示方法与独热表示不同的地方在于它可以刻画词与上下文的关系,用向量代表词[4]。它的表示模型有CBOW( Continuous Bag-of-Words)和 Skip-gram 模型等,目前的实现工具主要用word2vec。
2.2特征降维
目前主要的特征降维方法有:词频-逆文档频率(tf-idf)、信息增益(IG)、X2统计等。
如图2所示,5条分类线都可以实现将样本分为两类,但是由SVM得到的分类器H与两个类别的间隔较大,因此有较好的分类性能。
SVM是二分类器,将其运用到多分类时需要进行拓展,主要有两种方法,分别是:
直接求解法:修改目标函数,将多分类任务的所有面的参数求解看作一个中体,在解该最优化问题时,一次性实现多类分类。
间接求解法:
将多分类问题分为多个二分类任务,即组合若干二分类器,主要思想有两种:
①任意两类使用一个SVM来进行分类,即有m个类别就需要训练m(m-1)/2个SVM分类器。
最终进行分类任务时,将所有分类器进行统计,得票最多的即为该文本所属类别。
②每一个类别与其他所有类别为一组,有m个类别就分为m组,对每一组都构造一个分类器,最终进行分类任务时,将所有分类器进行统计,概率最高的即为该文本所属类别。
(3)SVM与NB优缺点总结
3总结
随着数据的爆照式增长,文本分类越来越重要。本文阐述了目前文本分类任务的各部分工作,简要介绍了文本预处理、特征降维和分类器的原理这三个方面。随着技术的更新,分类的效率及准确率还会有进一步的提升。
参考文献:
[1] 徐冠华,赵景秀,杨红亚,等.文本特征提取方法研究综述[J].软件导刊,2018,17(5):13-18.
[2] 高宁杰.基于SVM模型优化的互联网新闻自动分类研究[D].开封:河南大学,2019.
[3] 贺心皓. 基于支持向量机的文本分类研究[D].成都:成都信息工程大学,2019.
[4] 王旌舟.中文文本分类技术研究及应用[D].成都:西南交通大学,2019.
[5] 曾奇.面向微博的短文本分类算法研究[D].成都:电子科技大学,2019.
【通联编辑:代影】
- 林业可持续发展中低碳环保营林工程价值分析
- 浅议农作物病虫害防治中存在的问题及其对策
- 肇庆市省级现代农业产业园+乡村旅游发展现状概述
- 关于城市高品质园林工程的项目管理思考
- 以文化创意推动甘肃民族文化旅游业发展
- 浅析城市运营公司人力资源的量化管理
- 商业银行的营销渠道创新
- 关于水利水电工程施工过程的安全管理分析
- 精细化管理在建筑工程施工管理中的应用
- 沈阳红色旅游品牌传播问题与对策分析
- 基于多元逐步回归的煤炭价格预测研究
- 大数据时代企业人力资源绩效管理创新
- 关于如何做好生态城市规划设计的探讨
- 建筑工程管理中工程造价的管控
- 事业单位开展政工工作的思路与创新策略分析
- 浅析企业租赁经营业务设备精细化管理
- 试析卫生计生档案管理
- 厨房管理的常见问题与管理策略
- 项目精益化管理模式探索
- 浅谈存货管理对中小企业的影响
- 从市场营销角度看石油化工产品的销售管理
- 大数据时代下企业经营管理模式与发展研究
- 冠智电子有限公司存货管理中存在的问题及对策研究
- Z公司营运能力分析
- 商业银行反洗钱内部控制研究
- suckers
- sucking
- suckless
- sucks
- suck up to sb
- sucrose
- sucroses
- suction
- suctional
- suctioned
- suctioning
- suctions
- sudden
- suddenly
- suddenness
- suddennesses
- suddens
- suds
- sudsable
- sudsed
- sudses
- sudsing
- sudsless
- sue
- sueability
- 软气
- 软气氛
- 软水
- 软沓沓
- 软沙
- 软泡硬磨
- 软洋洋
- 软流层
- 软浪
- 软润
- 软湿
- 软溜溜
- 软滑
- 软火
- 软炊
- 软烂
- 软烟罗
- 软熟
- 软片
- 软片儿
- 软玉
- 软玉娇香软香温玉
- 软玉温香
- 软环办
- 软环境