李伟 孙新杰 刘志芳
摘? 要: 网络视频数据的快速增多,使得个性化智能推荐变得十分必要。为了便于用户在视频网站上发现自己喜欢的内容,提出通过数据挖掘来分析用户对电影的评分行为,采用基于项目的协同过滤算法,利用评分数据构造用户项目评分矩阵,计算电影项目之间的相似度,来预测用户对电影的评分并且给出结果推荐。实验运行结果表明,该方法对电影的推荐效果较好。该研究构建的基于数据挖掘的电影智能推荐系统能够帮助用户快速发现所喜欢的电影。
关键词: 数据挖掘; 智能推荐; 协同过滤; 评分矩阵
中图分类号:TP391.3? ? ? ? ? 文献标志码:A 文章编号:1006-8228(2019)05-61-02
Abstract: With the rapid increase of network video data, personalized intelligent recommendation becomes very necessary. To help users find their favorite content on video websites, this paper proposes to analyze users' rating behavior on movies by data mining, using project-based collaborative filtering algorithm, constructs the user item rating matrix by using the rating data, and calculates similarity between movie items to predict users' rating on movies and give the result to recommend. The experimental results show that the method has a good effect on the recommendation of movies. The intelligent film recommendation system with data mining can help users quickly find their favorite movies.
Key words: data mining; intelligent recommendation; collaborative filtering; rating matrix
0 引言
随着大数据时代的到来,网络上的数据量呈爆炸式增长,用户很难找到自己想看的电影[1]。虽然很多视频网站提供搜索引擎来让有明确目标的用户直接搜索电影,但是对于无明确目标的用户而言,则需要一种帮助,能让他们去发现可能喜欢的电影,因而诞生了智能推荐系统。郑诚等[2]提出基于互信息的推荐研究方法,陈平华等[3]研究融合知识图谱表示学习进行推荐,但是这些都还存在实践应用的问题。
本文提出构建电影智能推荐系统,通过数据挖掘的方法来分析用户的行为,推荐给用户适合的电影内容。
1 关键技术
电影智能推荐的关键技术是推荐算法,目前,推荐算法主要有基于内容的推荐、协同过滤推荐和基于网络结构推荐等算法,而协同过滤算法是当前研究最多的推荐算法。协同过滤推荐分为基于用户和基于项目[4],由于当采用基于用户的协同过滤时,计算复杂度会随着用户数目的增加变得越来越大,因此需要研究采用基于项目的协同过滤来构建电影智能推荐系统。
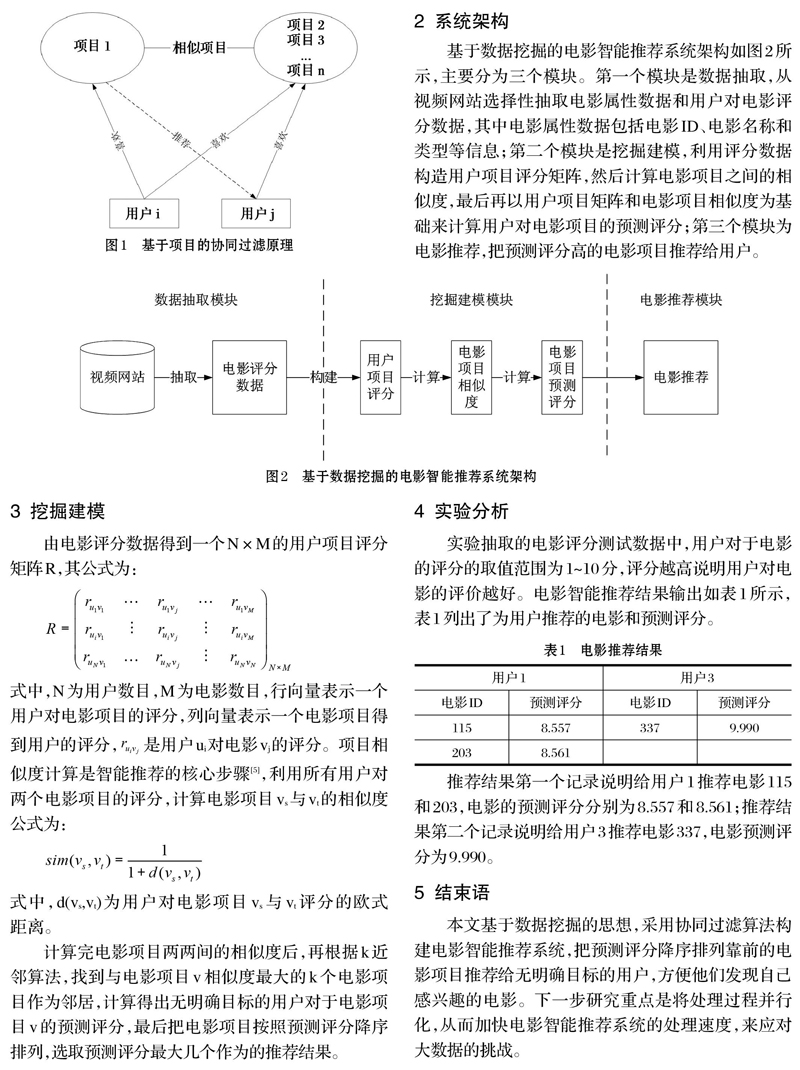
基于项目的协同过滤算法的核心思想是利用与项目相似度最高的k个邻居项目的评分加权平均计算得到用户对该项目的预测评分。其原理如图1所示,喜欢项目1的用户i还喜欢项目2、项目3、…、项目n,因此项目1到项目n的相似度较高,它们为相似项目,用户j也喜欢项目2到项目n,因此可以将用户j还没有发现的项目1推荐给该用户。
2 系统架构
基于数据挖掘的电影智能推荐系统架构如图2所示,主要分为三个模块。第一个模块是数据抽取,从视频网站选择性抽取电影属性数据和用户对电影评分数据,其中电影属性数据包括电影ID、电影名称和类型等信息;第二个模块是挖掘建模,利用评分数据构造用户项目评分矩陣,然后计算电影项目之间的相似度,最后再以用户项目矩阵和电影项目相似度为基础来计算用户对电影项目的预测评分;第三个模块为电影推荐,把预测评分高的电影项目推荐给用户。
3 挖掘建模
由电影评分数据得到一个N×M的用户项目评分矩阵R,其公式为:
式中,N为用户数目,M为电影数目,行向量表示一个用户对电影项目的评分,列向量表示一个电影项目得到用户的评分,是用户ui对电影vj的评分。项目相似度计算是智能推荐的核心步骤[5],利用所有用户对两个电影项目的评分,计算电影项目vs与vt的相似度公式为:
式中,d(vs,vt)为用户对电影项目vs与vt评分的欧式距离。
计算完电影项目两两间的相似度后,再根据k近邻算法,找到与电影项目v相似度最大的k个电影项目作为邻居,计算得出无明确目标的用户对于电影项目v的预测评分,最后把电影项目按照预测评分降序排列,选取预测评分最大几个作为的推荐结果。
4 实验分析
实验抽取的电影评分测试数据中,用户对于电影的评分的取值范围为1~10分,评分越高说明用户对电影的评价越好。电影智能推荐结果输出如表1所示,表1列出了为用户推荐的电影和预测评分。
推荐结果第一个记录说明给用户1推荐电影115和203,电影的预测评分分别为8.557和8.561;推荐结果第二个记录说明给用户3推荐电影337,电影预测评分为9.990。
5 结束语
本文基于数据挖掘的思想,采用协同过滤算法构建电影智能推荐系统,把预测评分降序排列靠前的电影项目推荐给无明确目标的用户,方便他们发现自己感兴趣的电影。下一步研究重点是将处理过程并行化,从而加快电影智能推荐系统的处理速度,来应对大数据的挑战。
参考文献(References):
[1] 海阔,海翔宇.电影大数据国际文献综述[J].新闻爱好者,2018.5:92-96
[2] 郑诚,徐启南,章金平.基于互信息的推荐系统方法研究[J].微电子学与计算机,2018.35(12):76-79
[3] 陈平华,朱禹.融合知识图谱表示学习和矩阵分解的推荐算法[J].计算机工程与设计,2018.39(10):3137-3142
[4] 李伟,石云,孙新杰.基于Hadoop的协同过滤算法的并行化研究[J].六盘水师范学院学报,2017.29(3):46-49
[5] Jiawei Han, MIcheline Kamber, Jian Pei.数据挖掘:概念与技术[M].机械工业出版社,2012.
- 传统中国的家族义务与功能
- “道器关系”中的中华文化图景
- 礼乐文化的身体原型
- 试论丝绸之路经济带对促进我国西部族际政治整合的积极作用
- 陕西人与丝绸之路
- 塞壬的歌声
- 徐松“西域三种”论略
- 五四桐城学案的回顾与再思考
- 论普列汉诺夫的马克思主义观
- 文化抵抗与工人阶级文化重塑
- 山水画的南北与东西
- 司法网络舆论的分析与对策
- 压力与选择:当代中国国家治理的演进逻辑
- 危机传播与媒体执政的中国经验
- 生态城市:资源型城市转型发展的路径选择
- 中国—东盟区域经济一体化的文化动因及应对策略研究
- 中国民生支出规模适度性评析及需求预测
- 词为心声,字为心画
- 唐诗的漆艺书写:一种知识社会学考察
- 姜嫄“履巨人迹”新说
- 孙中山与公职候选人考试深度剖析
- 近代中国律师对外交往的先声
- 中国大运河的历史变迁、功能及价值
- 《庄子》《吕氏春秋》重文研究
- 男性美的基质
- severenesses
- severer
- severest
- severing
- severish
- severities
- severity
- sever links/connections/relations/ties
- severs
- sew
- sewabilities
- sewability
- sewable
- sewables
- sewage
- sewaged
- sewages
- sewed
- sewer
- sewered
- sewering
- sewerless
- sewerlike
- sewers
- sewery
- 瓦片覆盖的屋脊
- 瓦版
- 瓦特
- 瓦特·泰勒起义
- 瓦特小时计
- 瓦玉集揉
- 瓦玉集糅
- 瓦瓦祖拉
- 瓦甒
- 瓦甓之道
- 瓦着
- 瓦石
- 瓦砚
- 瓦砾
- 瓦砾遍地
- 瓦窑
- 瓦窑堡会议
- 瓦粮
- 瓦缶黄钟
- 瓦缸里使锤——使不上劲
- 瓦罐
- 瓦罐不离井上破
- 瓦罐不离井上破,将军多在阵前亡。
- 瓦罐不离井上破,将军难免阵中亡
- 瓦罐不离井上破,将军难免阵前亡