国外社交媒体归档项目研究及启示
王志宇 袁馨怡

摘要:随着web2.0技术的不断进步和发展,微博、博客、微信等社交媒体平台越来越受到公众的欢迎。海量的社交媒体信息记录着大量零散的生活记忆和社会记忆。国外如美国、英国、澳大利亚等国家对社交媒体信息归档的研究处于理论与实践结合并不断深入的过程中,而我国目前还处在理论多、实践少的起步阶段。本文具体从捕获、鉴定、保存、利用方面分析了国外社交媒体归档项目,为今后我国的研究提供可行性的参考。
关键词:社交媒体归档Twitter归档社会记忆
作为延续人类社会记忆的形式,社交媒体信息在本质上具有与档案相同的属性,它反映了社会现象与人类活动,其内容应被归档保存,蕴含的潜在价值也应被挖掘。这种非结构化的社交媒体信息,其管理过程应以传统档案的归档方法为基础,但又与其存在差异。在对社交媒体信息档案化管理的道路上,美、英、澳等发达国家正在进行的归档项目值得我国档案部门研究与借鉴。一、社交媒体信息的捕获
(一)美国国会图书馆归档Twitter项目
美国是社交媒体信息归档研究的代表性国家,早在2010年12月8日,美国国家档案与文件署(NARA)在其官网上发布了《社交媒体战略》。该战略提到“社交媒体作为一种工具,能够使机构职能和服务公众的方式发生一定程度的转变。机构也会因此越来越公开、透明,促進机构间的参与及合作。它将帮助档案机构完成作为国家记录保存者的任务——保护国家文件记录,并由此增强对公众的可用性。”[1]同年4月14日,美国国会图书馆(LC)启动了Twitter归档项目,“LC与Twitter签署了《捐赠协议》,Twitter向LC捐赠自其建立时起的全部公开推文,归档对象即2006年3月至2010年4月的公开推文,美国国会图书馆作为此次归档主体。Twitter归档项目正式启动,消息首次通过LC官方推特账号@LibraryCongress发布。”[2]并在2013年1月发布了Twitter存档的白皮书,题为《Update on the Twitter Archive at the Library of Congress》,其目标是“采集并保存2006-2010年的tweets档案;建立一个安全可持续的计划,以接收和存储每天不断流动的推文流;并创建一个按日期组织所有推文文件的系统结构。”[3]国会图书馆和Twitter已经获得了通过捐赠存档社交媒体信息的权利。
(二)美国社交媒体信息捕获的保障
NARA在《社交媒体文件捕获最佳指南》中声明,“承诺响应联邦政府部分机构工作人员的要求与指导请求并予以兑现”[4],因此,可知社交媒体有一个独立的捕获主体就是政府机构,为社交媒体信息的捕获与归档工作提供机构保障。对此,“美国制定了《隐私权法》《联邦记录法》《信息自由法》,美国政府问责局颁布了《联邦机构所需的信息管理及保护的政策和程序GAO-11-60文件》、美国国家档案与文件管理署发布了《美国国家档案与文件管理署2014-02布告》”[5]等一系列法律法规,共同组成了美国社交媒体信息捕获归档的规范性法规体系。
可见,捕获社交媒体信息,首先需要明确捕获主体,是档案部门、政府机构还是多重主体,还要求具备法律政策、捕获技术的保障,否则社交媒体信息捕获并归档的实施很难步入正轨,然而目前来看我国只有《档案法及实施办法》《电子公文归档管理暂行办法》《文书类电子文件元数据方案》《电子档案移交与接收办法》等与社交媒体记录捕获归档有一定关系,但尚未制定与捕获社交媒体信息直接相关的法规政策。
(三)社交媒体信息的捕获技术
综合国外社交媒体归档项目的数据捕获与采集技术可以看到,对于社交媒体信息的捕获往往采用以下几种方式:1.可采用网页截图技术。这是一种常见的将信息以图片的形式捕获下来的技术,由于社交媒体信息多以HTML形式在浏览器中呈现,而保证其原始性最直接的办法就是网页截图。截图技术并不是很难做到的高深技术,但如何按归档需求截取海量且实时更新的社交媒体信息并将如此大批量的非结构化图片文件归档保存则是一种需要探索的管理方案。2.网络爬虫技术。“它是一种利用一定的规则,自动抓取万维网的信息的程序或者脚本”[6]的技术。其优点在于科学性,爬虫的捕获速度非常迅捷,也是最为广泛使用的捕获技术,很多国内外从事社交媒体分析的科研人员都采用网络爬虫的方式将社交媒体信息以JSON或XML等格式保存到电脑中并用数据挖掘技术予以统计和分析。3.使用API应用程序接口。此即由社交媒体运营服务器提供开放后台接口,将数据从后台数据库通过API直接下载到本地,这往往需要和社交媒体公司签订协约,令其对档案部门供应数据。此外使用RSS订阅、聚合的方法来捕获社交媒体信息也具有很多优势,如捕获信息准确、成本低、时效性强等特点,但需要社交媒体服务器提供数据聚合用到的Feed。二、社交媒体信息的鉴定
(一)美、英、澳的社交媒体信息的鉴定工作
对社交媒体的鉴定工作,各个国家在探索中逐渐形成了自己的显著特色。英国国家档案馆对社交媒体信息内容的归档规定,不是全部的推文都将被归档,其中的转载和评论不属于归档范畴,其归档范围包括正文和背景信息。澳大利亚和美国的社交媒体信息存档并不直接对其政府负责。“国家环境保护机构与美国海岸警卫队声明,与该部门无关的社交媒体信息政务性的言语应被删掉”[7],澳大利亚国家档案馆提出“鉴定技术与方法政策随着工具的变化而选择,还将对有关部门进行咨询”[8],澳大利亚和美国在国家级方面暂时还没有准确的标准制定,因此在具体选择归档哪些社交媒体信息方面具有自主性,与此同时要遵循国家及有关部门的相关规定与法律政策。
社交媒体信息归档的法规中,在鉴定这一环节,澳大利亚和美国的有关档案部门相继规定了社交媒体信息的鉴定标准,这一标准具体到价值鉴定,其中的核心思想是“机构与业务相关性”。但是应用到实际问题中,该问题被当作导向及大纲性的建议,所产生的作用及后果还需要进一步研究。在2010年美国国会图书馆发起Twitter归档项目的时候,其Twitter归档对象是从2006年3月到2010年4月全部的公开推文,但事实上,它并不会采集私人用户信息以及删掉的推文,网页链接的信息包括网址及图片也不会被归档。
(二)社交媒体信息鉴定主体与对象
相对于传统档案的鉴定,社交媒体信息鉴定主体更加的多元化。首先,社交媒体用户应积极识别他们发布的信息的价值;其次,档案工作人员及档案部门,应制定法规政策、标准等来规范社交媒体信息的鉴定工作,对总体鉴定工作进行指导;再次,社交媒体平台应依据档案部门制定的法规政策等标准,其相关技术人员进一步完善鉴定功能;最后,第三方技术公司应做好社交媒体信息鉴定的辅助工作,辅助档案部门及社交媒体平台的鉴定工作,起到技术支持的作用。
从鉴定对象来看,与传统档案不同,传统档案的鉴定对象是档案。但由于社交媒体平台所产生的是“信息”“记录”,这种社会记忆是非结构化的,所以鉴定对象由“档案”“文件”转化为“信息”“记录”,这种非结构化数据的管理问题也需要新的技术和方法来解决。
(三)社交媒体信息鉴定标准与工具
依据科学的衡量来制定有力的鉴定标准,就国内而言,社交媒体信息归档还处在理论阶段,而各学者对此标准也各抒己见,主要分为以下几类:“按照定义表述分,包括价值标准和真伪标准;按照应用性分,包括操作与理论标准;按照内容分,包括技术与内容标准;按照主体分,包括政府版标准和公众版标准。”[9]其中理论性标准是指导社交媒体信息鉴定的基础标准,它包括来源、价值与关联。
社交媒体信息具有实时性且信息量大的特征,根据社交媒体信息的特点与鉴定原则标准,各鉴定主体在判定社交媒体信息后,由社交媒体信息保存系统与社交媒体平台提供的鉴定工具进行鉴定,其工具主要有两种:“一是只读电子记录表,就是在保存社交媒体信息的系统中具有固定格式的只读表格;二是读写电子记录表,是指在保存社交媒体信息的系统中具有固定格式的可读写表格。”[10]三、社交媒体信息的保存
(一)英、澳的社交媒体信息的保存工作
“根据1983年英国档案法,并通过为期两年的项目实验,从2014年5月8日开始,英国国家档案馆网络档案管理部门(UKGWA)已在Twitter和Youtube上正式统一为英国中央政府部门提交社交媒体平台文件。标志着档案馆开始积累并永久保存复杂的社交媒体信息。”[11]在项目启动时,该社交媒体档案库共有视频资源七千个,从2008年到2013年9月的Twitter文件共六万五千多份,多为大型的历史活动,如2012年的伦敦奥运会、女王的加冕典礼等。英国的在线社交媒体库保存的文件包含网页链接、发布日期和时间、JSON和XML文件等详细信息,同时为方便公众利用还将数据格式转为开放的CSV格式。这也是英国国家档案馆在此次初次尝试对政务社交媒体进行归档保存,其在与欧洲网络记忆基金一起应对社交媒体归档保存等技术问题时,使用共同研发的收集工具以确保文件内容和结构的原创性。
“1996年,澳大利亚图书馆开始建设国家网页档案馆项目。澳大利亚中央政府机构所有相关的网络档案都由澳大利亚国家图书馆负责收集,是该项目的重点,存档内容除网页信息外,还包括详细的出版者信息、允许存档的日期、收集频率、存档的元数据等,并于2014年3月开始对公众开放数据库。”[12]图书馆的归档方法采用网页快照的形式,公众可以通过在线平台搜索政府社交媒体信息来检索。“澳大利亚国家档案馆对政务社交媒体的归档缘由基于数字连续性理论。数字连续性理论强调社会数字信息的长期可用以保障社会数字記忆的延续性。”[13]以这个理论为基础,澳大利亚国家档案馆制定了政府社交媒体的归档政策,其中明确了政务社交媒体的信息保存的三个要点:1.对数字信息可以通过在线和离线以及可移动介质进行保存;2.以云计算技术进行云端存储时应受1983年澳大利亚档案法的约束,云端存储的数据应真实、准确、值得信赖,应与云服务商签定明确的存储规范合同;3.严格的数据外包服务规定。除此以外政策还明确了存储数据设备的物理保护规范等。
(二)社交媒体文本信息的存储
鉴于国外对社交媒体信息的存储方法与社交媒体信息的特点,为了有效地对其利用,选择一种能长期保存信息的技术方法尤为重要。近年来的NOSQL类型的数据库被越来越多地使用在非结构化数据存储上,而针对海量社交媒体数据存储的特点,国外社交媒体归档项目多采用Mon? goDB作为存储数据库工具。“MongoDB是一种强大、灵活、可扩展的数据存储方式。”[14]它能够存储比较烦琐复杂的数据类型,能够实现对海量数据的存储管理,其采用BSON的数据存储格式,是JSON的一种拓展格式,支持嵌入复合型的数据类型,且支持非常松散的数据结构,这使得MongoDB十分适合文档的存储与查询,在利用时也十分方便灵活。但是,到目前为止,由于MongoDB中的单个BSON对象小于16MB,因此该方法较适用于存储小文件。
(三)社交媒体信息中非结构化大文件的存储
社交媒体信息除了文本往往还包含图片、视频等非结构化的大型文件,这种大型文件(如大图像文件和视频文件)无法直接保存到MongoDB文档中。但通过分布式存储技术,可使用MongoDB把大文件拆分成小块的GridFS机制,以完成较大文件的存储。对于社交媒体信息本身而言,其格式存在差异,文件自身的大小也不能标准统一化,MongoDB的GridFS机制在处理大文件的时候,具有很好的扩容性,甚至可以存储成百上千万的海量文件。“GridFS文件系统是用于在MongoDB数据库中存储大文件的规范”,GridFS文件系统的工作原理是“该文件被分成几个小块,每个块通常大小为256k,每个块作为单独的记录存储在块集合中。对于文件,将有一个文件块与若干块。”[15]为了便于访问与检索,社交媒体的大文件信息必须按规则组织与存入,并与原包含相关内容社交媒体信息进行数据关联与挂接。四、社交媒体信息的开发与利用
(一)美、英、澳的社交媒体信息的开发与利用工作
目前美、英、澳等发达国家已经建立了完善的社交媒体库,不但实现了对社交媒体资源的有序化和统一化的管理,其平台的构建还方便了利用者对目标资源的利用与开发。
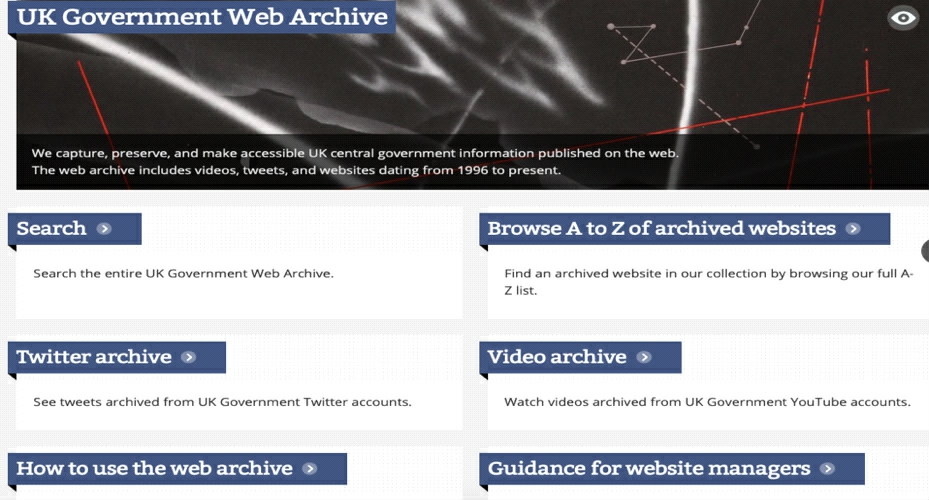
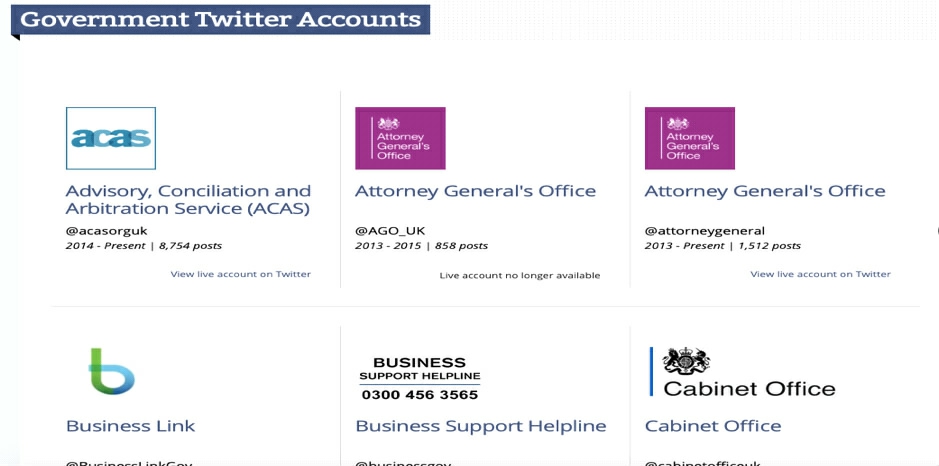
2014年英国国家档案馆开放了在线社交媒体库——英国政府网络档案馆(UK Government Web Ar? chive),如图1所示。通过访问英国国家档案馆媒体库网站,能够很直观地看到一系列查询功能,主要部分包括了Twitter库和YouTube视频库、存储在Twitter上的推文和YouTube上发布的视频,如图2、图3所示,作为政府的在线档案馆,这些已归档的社交媒体信息以英国政府相关政务文件为主,在以不同类型政务活动为分类依据的条件下,浏览者可以以英国政府官方各部门的Twitter账号和YouTube账号发布的内容为线索进行浏览。
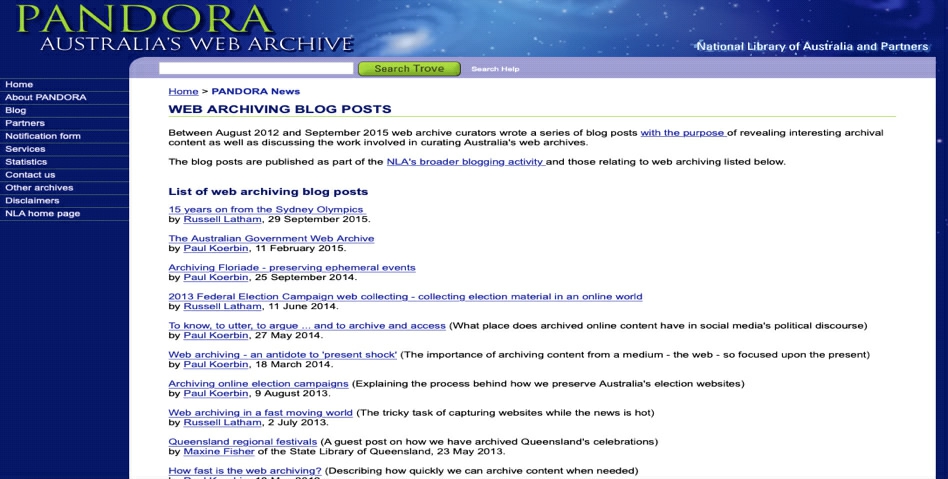
澳大利亚国家图书馆自2012年以来就使用PAN? DORA网络归档系统存档在线博客文件,有选择地存档博客文章,并创建“社交媒体网络档案库”,如图4所示。该网站的服务内容可追溯到1996年PANDORA档案系统开发计划的实施,由于澳大利亚国家图书馆在互联网技术发展的过程中不断开发与完善了PANDAS(PAN? DORA数字存档系统)网页归档管理系统,使澳大利亚国家图书馆与档案馆的网页信息的收集和归档项目变为现实,并通过网站的形式提供检索与利用。
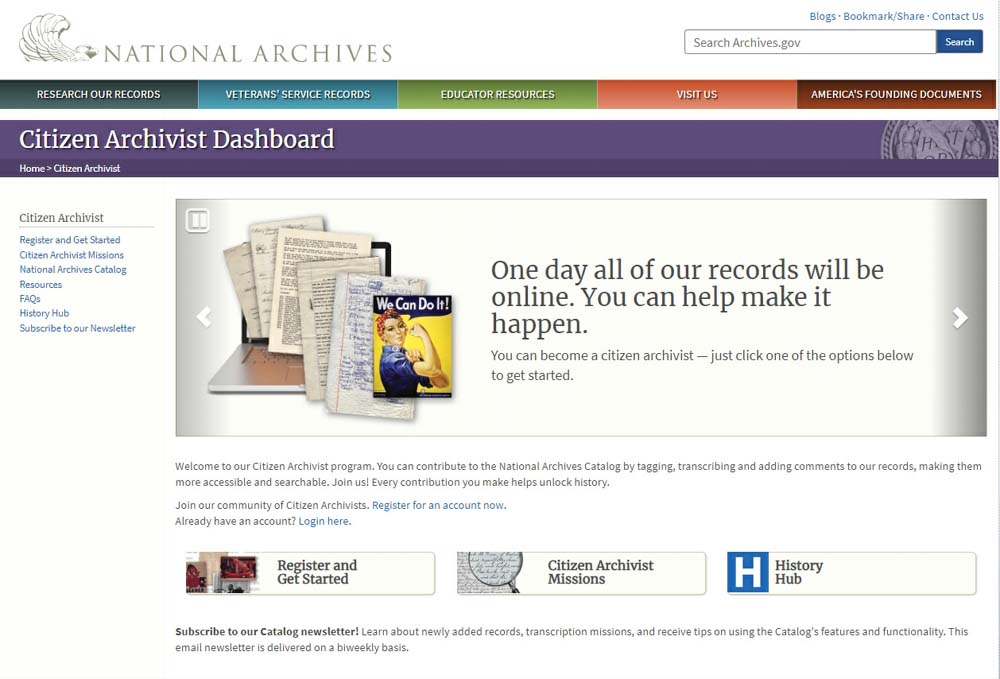
在2011年12月24日,美国国家档案馆根据“众包”的理念,鼓励大众参与到档案馆的各项事务中来,从而创立了一个公民档案员平台:“我们的档案”(Our Ar? chives),如图5所示。“这是一个专门为研究者、历史学家、档案工作者、Citizen Archivist(公民档案员)建立的维基网站。”[16]这个网站是美国国家档案馆“开放政府计划”的一部分,也是Citizen Archivist项目的资源整合平台。该网站分五个模块,其中涉及档案管理内容的主要有档案著录、档案编纂、档案数字化等,这样使得大众可以参与到美国国家档案馆的各项工作中来。
(二)社交媒体信息专业领域的智能化开发与利用
社交媒体信息在专业领域中的应用,如网络信息挖掘、大数据舆情以及智能化分析等领域的开发与利用是目前在数据分析领域非常热门的。借鉴国外先进的理论与技术,并结合我国现有的研究水平来积极开展我国的社交媒体归档信息的智能化利用工作是十分必要的。目前对社交媒体数据分析的应用主要包括社交媒体信息关键词抽取、社交媒体信息主题分类、情感分析、构建用户画像、网络舆情分析、人类行为预测分析、网络营销等方面。
随着web2.0的不断发展,社交媒体平台的使用愈来愈普及,作为延续人类社会记忆的形式,社交媒体信息在本质上具有与档案相同的属性,其价值应该被予以重视。对这种非结构化的社交媒体信息的档案化管理工作而言,在归档过程中以归档传统电子档案理论和方法为依据,但又与其存在着显著差异,美、英、澳等发达国家在对社交媒体信息無论是从捕获、鉴定、保存还是开发利用等方面都做得相对完善,对它们的社交媒体归档项目的研究对于我国的相关工作的开展有着重要的参考价值和启示。
*本文为国家社会科学基金项目“非结构化电子文件管理研究”(16BTQ089)研究成果之一。
注释及参考文献:
[1]U.S.National Archives and Records Administration, Social Media Strategy [EB/OL].[2010- 12- 8].https:// www.archives.gov/social-media/strategies/2010.
[2]万凯莉.美国Twitter存档项目对我国社交媒体信息归档的启示[J].浙江档案,2014(5):8-11.
[3]周文泓.社交媒体信息档案化管理的挑战与对策探析——基于美国国会图书馆Twitter档案馆项目的调查与启示[J].档案管理,2018(6):51-53.
[4][7] NARA. White Paper on Best Practices for the Capture of Social Media Records [EB/OL].[2013-5-28]. https://www.archives.gov/files/records- mgmt/resources/ socialmediacapture.pdf.
[5]张江珊.美国社交媒体记录捕获归档的思考[J].档案学研究,2016(4):119-123.
[6]常家豪.基于社交媒体的安全态势信息采集方法[J].网络安全技术与应用,2014(7):5-9.
[8]National Archives of Australia. Your Social Media Policy -what about Records.[EB/OL].[2018-11-14]. http://www.naa.gov.au/information- management/managinginformation-and-records/types-information/social-me? dia/social-media-policy/index.aspx.
[9][10]万凯莉.论社交媒体信息的档案化鉴定[J].档案学研究,2016(1):62-66.
[11][13]王焕.国外政务社交媒体文件归档研究[J].档案学研究,2015(6):99-105.
[12]张晓娟,李沐妍.政务社交媒体文件的管理模式研究[J].信息资源管理学报,2018,8(3):45-53.
[14]红丸.MongoDB管理与开发精要[M].北京:机械工业出版社,2012.
[15]李兴武.大数据下MongoDB数据库数据文档存储去重研究[J].数字技术与应用,2017(9):99-101.
[16]施少钦.美国国家档案馆“Citizen Archivist”项目研究及其启示[D].福建师范大学,2012.
作者单位:辽宁大学历史学院档案系
