基于神经网络技术的违规视频自动识别关键技术
摘 要 以严重危害公共安全的暴恐视频作为研究对象,针对音视频检测技术特点和难点,重点研究对视频识别影响最大的视频预处理环节,提出基于神经网络技术的视频特征分类方法。
关键词 违规视频;预处理;神经网络;机器学习
中图分类号 G2 文献标识码 A 文章编号 2096-0360(2018)05-0037-02
随着网络视听产业的快速发展,人们可以利用互联网通过多种渠道观看网络视听节目。大量的视听节目满足着不同人不同的文化需求。但互联网上的视听节目良莠不齐,很多暴恐节目威胁社会稳定,危害未成年人成长和身心健康。及时发现并处置暴恐视听节目是网络视听监管的重要工作。然而,面对海量的视听节目,单靠肉眼监看、人工审核显得杯水车薪,监管效果也不理想。因此,研究利用人工智能技术自动识别记录暴恐视频节目,解决人工监看識别效率不高的现状成为一项亟待解决的重要课题。
1 暴恐视频检测特点
目前,同视频识别的其他方面例如淫秽色情节目识别、人脸识别相比,暴恐视频识别研究相对较少。一般来讲,主要通过图像识别和音频识别两个方面来完成。
1)基于音频的检测方法。声音被数字化后的音频对判定视频内容有着重要参考。声音可以看作N个正弦波频谱的叠加。和视频相比,音频频谱相对简单。音频提取、计算和存储相对容易。此外,音频的生理特征也可以为识别提供帮助。一些暴恐视频伴随着特定的声响。例如惊呼、狂叫、呼喊、哀嚎、爆炸和打斗声等。还有一些暴恐视频播放带有明显特征的背景音乐和旁白解说。这些声音同正常视听节目声音存在明显差异。我们可以通过比较特征音频对待检视频做出初步判断。比如利用隐含马尔可夫模型理论(HMM)等统计学方法分类识别,通过Markov链以及每一状态的记录,生成概率密度函数。实现对视频节目中枪声、炮声、爆炸声的检测分类。近些年,也有通过贝叶斯网络分类识别的方案,尽管方法简单高效,但由于对音频质量要求相对较高,抗扰能力差等特点并不被普遍使用[1]。
2)基于视频的检测方法。基于视频的检测方法本质上是对视频数据中鲁棒性较强的特征进行分类检测。包括视频样本取样和自动分类两个方面。视频检测关键是视频样本特征的提取。一般分为基于局部特征区域和基于全局特征区域。基于局部特征区域是通过找出视频中时空趣味点(STIP),然后比较趣味点特征[2]。基于全局特征区域是利用形状模型提取人物形状,对人物动作进行估计,从而判断人物行为的检测方法。视频分类是按照不同视频特征进行逻辑区分。因此视频样本特征选取是关键,直接关系视频检测的效果。好的样本选取原则可以将不同类视频良好隔离;具有相似特征的视频则呈现紧密分布。
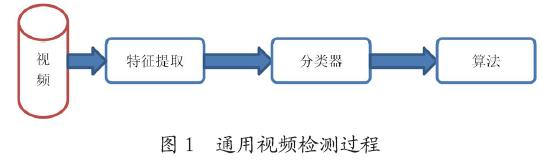
3)综合应用音视频数据检测。通用视频检测过程可分为视频样本特征提取、分类器和算法的选择。通用模型如图1。
在实际应用中,综合应用音视频数据检测判定可以得到更为理想的效果。通过对燃烧火焰、沙漠瓦砾、枪支火药和血液这些特有的画面信息和哭喊、爆炸、特征音乐等标记进行综合检测识别。通过联合训练的方法,构成组合分类器实现对暴恐节目的精准识别。
2 视频特征提取预处理
为便于视频特征提取以及分类器分类,待检测视频首先要经过预处理。预处理是视频识别的重要步骤。主要有关键帧截取、图像增强、灰度变换与直方图均衡和降噪处理等方式。一般通过计算机和硬件配合完成。
1)关键帧截取。视频可以看作连续图片的组合,当图片的变换速度超过人眼的视觉暂存时间后。人们看到就是一个连续的视频节目,而非一张张图片。关键帧截取可看作逆过程。主要有灰度颜色匹配法和直方图相似性比较法。基于灰度颜色模板匹配的方法原理简单,比较两帧对应点的灰度颜色数据的变化。缺点是当画面内容变化速度较快时,差异值容易超过设定阈值,从而造成误检。基于直方图的比较方法是目前常用的比较方法。该方法是将各帧之间的各个像素的灰度、亮度分为N个等级,再针对每个等级统计的像素数做成直方图,通过比较从而做出判断。
2)图像增强。图像增强是视频预处理的重要步骤。由于很多暴恐视频图像并不是在摄影棚完成。而图像识别要求图像清晰度必须超过识别阈值,关键特征才有可能被识别出来。图像增强就是要有效提高视频特征度,从而有利于提取特征参数,更有利于计算机处理识别。可以这样理解,图像增强就是增加图像清晰度,去除冗余信息,突出有效信息的过程。
3)灰度变换与直方图均衡。灰度变换是指将图像的整体或是局部的灰度范围从(x,y)到(m,n)的转换。目的是使图像目标细节更清晰。灰度变换提高画面对比度而不改变画面内部的像素相对位置。直方图表示视频关键帧画面素强度分布,它代表不同像素强度点的密度。直方图均衡化可以理解为对图像各像素灰度级的拓展,提高原值的动态范围。直方图均衡化同样可以增加图像对比度,提高图像清晰度。
4)视频降噪处理。视频和图像在生产、传递和处理过程中不免会受到噪声干扰。影响视频和图像质量。这些噪声降低了视频的清晰度,表现为模糊、失真。视频元件的高斯噪声、图像切割造成的数据损失、视频高压缩率压缩都是产生噪声的原因。噪声降低关键帧关键特征的识别度,加大下一步处理的难度[3]。目前一般采用高斯滤波、均值滤波和双边滤波等方法过滤干扰。
3 暴恐视频神经网络分类模型
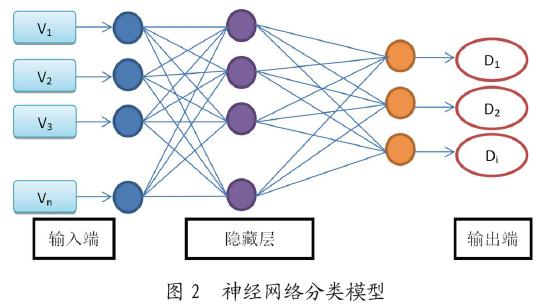
视频分类是依据待检测视频特征,判别视频所属分类的过程。是视频识别的关键环节。有效选择分类模型,并对模型参数进行准确设定则是关键中的关键。BP(BackPropagation)神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP神经网络实质上是完成分类器两端的映射联系。数学理论已经证明,三层以上神经网络可以高精度逼近非线性连续函数。BP神经网具有非线性映射能力。这为利用BP神经网络解决复杂的视频识别分类问题提供重要前提。BP神经网络的自动学习和容错能力也有利于分类模型的应用。在训练基于BP神经网络分类器时,分类器可以自动学习分类的“有效规则”,并自动记忆学习结果,应用到下一次的分类行为中去。此外,BP神经网络的个别神经元受损后,不会对整个分类结果造成很大影响。在提取待检测节目的音频、视频特征量后,我们要对不同类型数据进行矢量化。大量音视频特征矢量通过输入端进入分类器,输出端则对应视频的判定分类。在通过大量样本学习后,分类误差控制在合理范围以内。对待检视频Vn进行判断,得到判断结果Dn。如图2所示。
要想达到理想的分类效果,必须让神经网络分类器进行大量学习。BP神经网络具有很强的分类能力,可以将输入特征视频经过隐藏层通过非线性变换至新维度。从而简化问题,降低分析复杂性,进而将特征视频矢量逼近目标分类。最后完成视频识别的关键步骤。
4 结束语
恐怖主义是世界人民的公敌。随着网络视听技术的普及,越来越多的暴恐视频通过互联网传播,已经严重危害了国家安全和社会稳定。利用自动识别技术对暴恐视频进行识别判定对于保障互联网视频内容安全和净化网络环境具有重大意义。本文针对音视频识别特点,重点研究了视频预处理环节,进而提出采用BP神经网络模型对视频分类识别,达到自动识别暴恐视频的设计目的,并为利用人工智能技术解决视频自动识别问题提供了借鉴。
参考文献
[1]王真.基于多颜色空间信息融合和AdaBoost算法的自适应肤色建模研究[D].济南:济南大学,2012.
[2]詹剑锋,明子鉴,王磊,等.海云计算实验系统研究[J].网络新媒体技术,2012(6):3-8.
[3]王洪志.基于静态图像的人脸检测与识别系统的设计与实现[D].成都:电子科技大学,2010.
作者简介:齐忠文,国家新闻出版广电总局哈尔滨监测台。
