分布式文件系统在铁路信息系统中的应用
陈斐 李锐 王成福 冷晔
摘要:随着铁路信息化技术快速发展,对分布式存储的可靠性和鲁棒性要求越来越高。文章设计一种分布式文件存储备份系统,能够实现应用层块级(文件级)重删、快照、克隆,细粒度下连续数据保护功能。该系统采用分布式高可用高可靠架构,并能实现快速在线动态扩容。与主流分布式文件系统相比,能快速实现适合铁路信息化场景下大规模分布式存储并取得更好的性价比。
关键词:分布式文件系统;重删;快照;克隆;连续数据保护
1.概述
随着铁路信息化技术的飞速发展,铁路IT系统产生的数据越来越多,对存储的容量和可靠性要求越来越高。铁路信息化系统中,存储的文件多为小文件(小于64 M),写入后无需修改,并且数量繁多,需要低延时访问。目前优秀的开源分布式系统,比如(Hadoop Distributed File System,HDFS)等,虽然能够很好地满足分布式可靠存储的需要,但并不适合低延迟数据访问,也无法高效存储海量小文件,不支持多用户写入及修改文件,并且不支持快照和重复数据删除技术。而且,虽然Hadoop属于开源技术,但软件的安装和部署并不廉价。由于其管理工具和支持服务方面的不足,使用过程中容易产生额外费用。为了更好地存储数据并分析数据,针对铁路信息系统的需求和特点,设计一种分布式文件系统,以满足铁路各系统的需求。
2.系统架构与运行原理
系统采取cs架构,基于应用层文件级的备份恢复系统。分为客户端,配置服务器,元数据服务器集群,存储服务器集群4部分。集群中,所有服务器本地文件系统采用ZFS,ZFS是一款128 bit文件系统,可有效利用大容量廉价的SATA磁盘,具有端到端安全性,存储池自动可伸缩特性,同时还拥有自优化,自动校验数据完整性,存储池/卷系统易管理等很多优点,同时避免RAID5著名的“WRITE-HOLE”缺陷,并较ext3系统运行速率提高约30%-40%。
2.1Meta Svr和配置服务器核心数据结构
Meta Svr采用数据库方式持久存储数据,以表结构的方式存储元数据。系统初始化运行时,元数据全部load到内存中。系统采用一致性Hash算法,将数据和负载均衡到多台机器中。对每一台机器,又采用主备双机备份方式,提高可靠性,形成一致性HASH环+主备的混合架构。任意一台机器宕机,slave机器能够马上切换成Master状态提供服务。
MetaSvr中还运行ZOOKEEPER服务,处理全局的数据存储服务器集群的块ID生成,块分配,回收,以及和数据服务器的心跳交互和数据校验。ZOOKEEPER是APACHE软件中类似GOOGLE CHUBBY的分布式协调服务,采用FastPaxos协议,实现了去中心化的高可用分布式锁服务。
Metasvr中存储信息主要分为文件HASH信息表、块HASH信息表、文件块映射信息表、块存储信息表,数据服务器空间使用情况表等。
2.2快照/克隆的实现
整个系统的快照/克隆分为存储集群的快照/克隆和MetaSvr和配置服务器的快照/克隆。
存储集群底层采用ZFS文件系统,可以方便地实现无限制的快照数量,随时进行数据备份。同时,也可以基于快照方便地实现存储集群中的底层文件系统克隆。
MetaSvr数据服务器和配置服务器生成快照时,只需做一次checkpoint操作,对cache中的数据刷入数据库保存;然后底层zfs执行一次快照/克隆操作即可完成。
系统执行快照动作时,首先执行MetaSvr上和配置服务器上的快照动作,再执行存储服务器上的快照动作。元数据服务器执行快照时短暂缓存写动作,读不影响。影响时间由底层ZFS执行速度决定。由于zfs快照开销特别小,属于0(1)常量时间级别,所以影响很小。如果对整个系统实行间隔较小的连续快照,则可以实现一定粒度下的CDP连续数据保护。
3.并行扩展与关键算法
3.1Meta Svr的分布式并行扩展
整个Meta Svr是系统的关键部分。如果宕机或不可用,则整个系统不可用。而且,随着数据量的增大,当内存容量不能满足HASH表计算要求,或后端存储不能满足元数据存储要求,则Meta Svr集群需要能够快速并行扩展。
在Meta Svr集群中,所有元数据服务器共享命名空间,采用一致性HASH算法自动分配和迁移数据。其相比普通hash的主要优势在于在添加或移除节点时,保证尽量少的cache失效(数据迁移及均衡)。在一致性哈希算法中,每个节点都有随机分配的ID。在将内容映射到节点时,使用内容的关键字和节点的ID进行一致性哈希运算并获得键值。缺点是客户端查询元数据策略要进行更改。可以采取版本升级方式进行,每次备份恢复前Meta Svr查询配置版本是否更新,若更新则自动拉取和更新配置策略数据。
3.2文件名字和ID生成算法
文件名字和ID在Meta Svr生成。由于文件名字在服务器端生成,因而可用采用比较特殊的生成算法,可以将文件名字直接解析为文件ID。客户端读取解析ID后就可用直接去MetaSvr服务器查询数据,减少了和配置服务器的交互,从而也提高了文件的访问速度。由于铁路信息系统中很多小文件并不需要自己命名文件名,因此,这种将数据块位置隐含在ID的方式,可以极大地提高了小文件的访问效率。
只有对于那些需要自己命名的客户端文件,才需要在读取时读配置服务器获取文件ID。
3.3存储服务器分布式并行扩辰
存储服务器可采用SSD设备作最终的存储服务器本地文件系统的二级缓存,提高系统的读写速率。
当存储服务器集群容量需要扩展时,只需要简单地增加机器,并将状态上报给所有MetaSvr即可。MetaSvr集群会立即将新增加的空间分配给写请求。当存储服务器宕机时,会失去和MetaSvr的心跳,MetaSvr服务器会将此机器所有的数据副本均衡分布到其他机器中去。
3.4小文件优化算法
对于小文件的写,有两种优化算法。一种是将多个小文件打包成大文件,减少MetaSvr元数据的数量;另一种就是采用特殊的文件名生成算法,文件名中就蕴含着文件ID,减少和配置服务器的交互。
4.系统原型
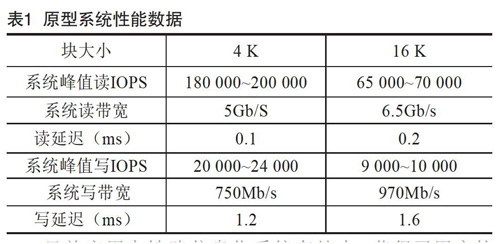
构建了一个30左右台普通服务器(2.6 GHz赛扬双核,2G内存),存储容量在百TB级别的分布式存储集群。使用自研的测试工具,在块大小为4 K,16 K,10个客户端同时读写情况下(75%读,25%写),其性能参数如表1所示。
目前应用中铁路信息化系统存储中,获得了用户的好评。
5.結语
本文实现了一种带快照,重删技术的分布式文件系统,能够有效的避免单点故障,并实现快速在线动态扩容。针对海量的小文件,优化了写入性能。服务器底层文件系统采用先进的ZFS系统,使单机存储容量极大提高,并保证了数据的端到端一致性,使单机数据可靠性和读写速度都得到了极大提高。同时,单机存储容量可在线动态扩展,集群容量也可以在线动态扩展,极大地简化了运维的复杂度。
