基于MongoDB的文本分类研究
陈德森 杨祖元
摘要:文章基于流行的非关系型数据库MongoDB,结合spark机器学习库中的朴素贝叶斯分类器和支持向量机,对豆瓣影评及京东商评进行情感分类,并采用准确率、召回率、F-Measure等指标对分类效果进行评价,最后测试了spark-MongoDB平台的扩展性能。
关键词:文本分类;Spark;MongoDB;MLlib
互联网发展促进了社交媒体、在线交易等新兴媒介的发展,这些网站每天都会产生数以亿计的数据。其中文本数据占据了重要位置,有80%的数据以文本形式存在的。如何有效利用这些文本数据去创造价值,是亟待解决的问题。
文本挖掘(Text Mining,TM)是指从非结构化文本中获取用户有用信息的过程。文本挖掘是从数据挖掘发展而来,但与传统的数据挖掘相比,文本挖掘有其独特之处,主要表现在:文档本身是半结构化或非结构化的,无确定形式并且缺乏机器可理解的语义;而一般数据挖掘的对象以数据库中的结构化数据为主,并利用关系表等存储结构来发现知识。
针对上述问题,本文将结合MongoDB和Spark,在文本存储及文本分类效果两方面进行研究。
1.文本数据的存储
上文所述产生的数据,通常是由关系数据库管理系统来处理。实践证明,关系模型是非常适合于客户服务器编程,它是今天结构化数据存储在网络和商务应用的主导技术。然而在数据爆炸的互联网时代,传统的关系型数据在应对大规模和高并发访问时显得力不从心,因此一批NoSQL数据库开始涌现,如MongoDB,Redis,Cassandra,HBase,CouchDB等。这些非关系型数据库旨在解决大规模集合以及多重数据类型带来的挑战,尤其适合大数据处理。
1.1MongoDB数据库
MongoDB是最近几年非常火的一款NoSQL数据库,由c++语言编写,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下,MongoDB可以通过添加更多的节点,来保证服务器性能。MongoDB旨在为Web应用提供可扩展的高性能数据存储解决方案。(1)内存充足。MongoDB性能非常好,它将热数据存储在物理内存中,使得数据读取十分快速。(2)高扩展性。MongoDB的高可用集群扩展性非常好,通过物理机的增加和在数据库中配置Sharding,集群扩展简单、高效。(3)Failover机制。MongoDB集群的主节点宕机后,通过选举方式自动在从节点中选出新的主节点提供服务,不需要人工参与。(4)BSon的存储格式。类JSon的存储格式,使得MongoDB十分适合文档的存储与查询。
基于MongoDB的特点,本文尝试用MongoDB结合Spark做文本分析研究。MongoDB支持3种部署方式,分别是单机模式、复制集模式、分片模式,本文采用的是分片模式。
1.2Spark结合Mong0DB
Spark是加州大学伯克利分校的AMP實验室(UC Berkeley AMP lab),Matei Zaharia博士在2009年所创立的大数据处理和计算框架,是一个类Hadoop MapReduce的开源通用并行框架。不同于传统的数据处理框架,Spark基于内存的基本类型(primitive)为一些应用程序带来了100倍的性能提升。Spark允许用户程序将数据加载到集群的内存中,用于反复查询,非常适用于大数据和机器学习,已经成为最广泛采用的大数据模块之一。在本文中程序中,通过添加mongo-java-driver-3.3.0.jar.mongo-hadoo-core-2.0.1.jar实现MongoDB和Spark的连接,使用ANSJ中文分词工具对读入的短评进行中文分词,最后使用Spark MLlib中的朴素贝叶斯分类器与支持向量机进行文本分析。
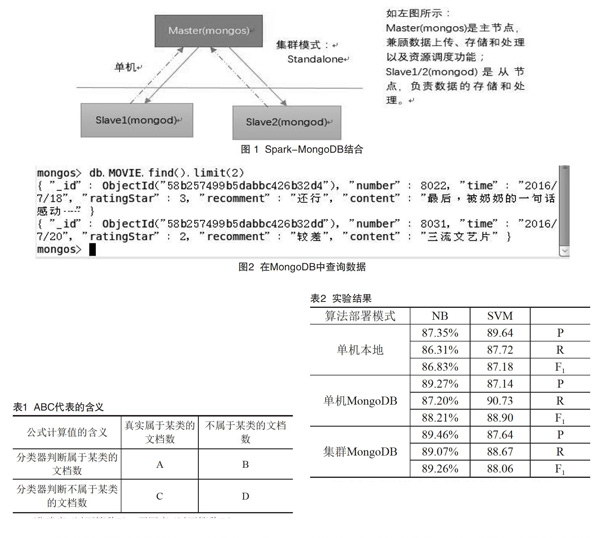
Spark-MongoDB结合的形式如图1所示,其中MongoDB采用的是分片模式。
1.3实验数据集
本文采用基于Java的网络爬虫获取互联网上的短评数据,共采集大概60万条评论,涉及了《疯狂动物城》《蝙蝠侠大战超人》《木星上行》(Honor8》等豆瓣、京东的评论。将影评和手机销售评论数据合并后,经过初步的清洗(去双引号,清除空数据,编码转换utf-8等),将数据导入MongoDB数据库中。在数据库中查看数据:
在文本分析实验中,按照评论的星级,将打1~2星的评论认为是差评,4~5星的评论认为是好评,以此来对短评进行文本分类。
1.4文本分类算法度量
在二分类问题中,通常使用的评价方法包括准确率,错误率,召回率,F-Measure,ROC曲线,准确率一召回率曲线下方面积,ROC曲线的下方面积以及等。在本文中,使用准确率、召回率、F值评估文本分类效果。其中,A,B,C所代表的含义如表1所示。
准确率(以下简称P);召回率(以下简称R)。
由于P值和R值出现矛盾的时候,还可以考虑用另外一种方法去分析,那就是F-Measure(又称F-Score)。F-Measure是P值和10值的加权和平均。
当参数a取1时,就是常见的值,即:可见综合P值和R值;当值较高时,说明分类方法有效。
接下来使用豆瓣数据集,验证文本分析情感分析在各种部署环境下的算法准确度。
1.5实验结果
从表2中可以看到,在单机本地,单机MongoDB,集群MongoDB集中模式中,朴素贝叶斯和支持向量机的分类效果相差无几。算法准确度并没有因为数据分散在各个不同节点而下降,可知分布式存储是适合做机器学习的。基于SparkMLlib的机器学习库的算法效率也比较高,可见已经可以适应一般的实际应用场景。
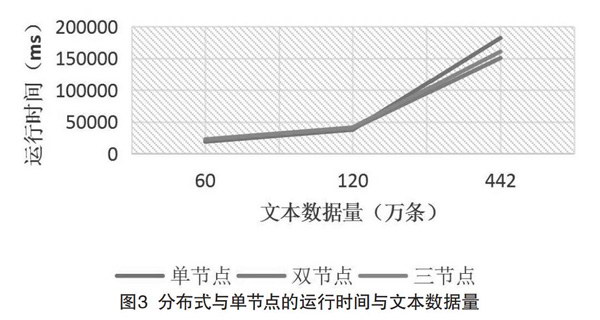
通过自我复制的方式对数据进行扩大,验证Spark-MongoDB分布式计算能力。使用分词工具分词,分别在单节点、双节点、三节点做分词和统计总词数的操作,通过运行时间比较他们之间的处理效率。其中单节点(主节点)是双核6G内存,单节点(从节点)是单核3G内存。
从图3中可以看出,分布式与单节点的运行时间比较中,在数据量达到一定程度后,加速比是大于1的,证明MongoDB集群在大数据处理方面确实比单机的效率要高。但由于数据量大小的原因以及内存的限制,它们之间的差别并不是很明显,甚至还出现了双节点速度比三节点快的尴尬,造成这种现象的原因是因为启动多个节点,在通信和资源调度方面会花费一定的时间。但总体而言依旧可以看出分布式平台比单节点操作具有更平缓的时间增长曲线。如果在更大规模的数据量以及性能更好的机器集群上,相信它们之间会有比较明显区别。由此可知,在实际应用中,如果需要处理的数据量很大的话,应用Spark-MongoDB分布式平台处理大数据将是一个很好的解决方案。
2.结语
由上述实验可知,spark自带的机器学习库,对一般文本的分类准确率已经比较高,结合文档型MongoDB做文本分析,将会是分布式环境下大数据分析的不错选择,具有实际应用价值。
